# A tibble: 2 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) -105. 7.54 -13.9 1.50e-37
2 hgt 1.02 0.0440 23.1 2.83e-81Inference: Regression Single Predictor
Chapter 24
Math 219
Math 219
Regression Line
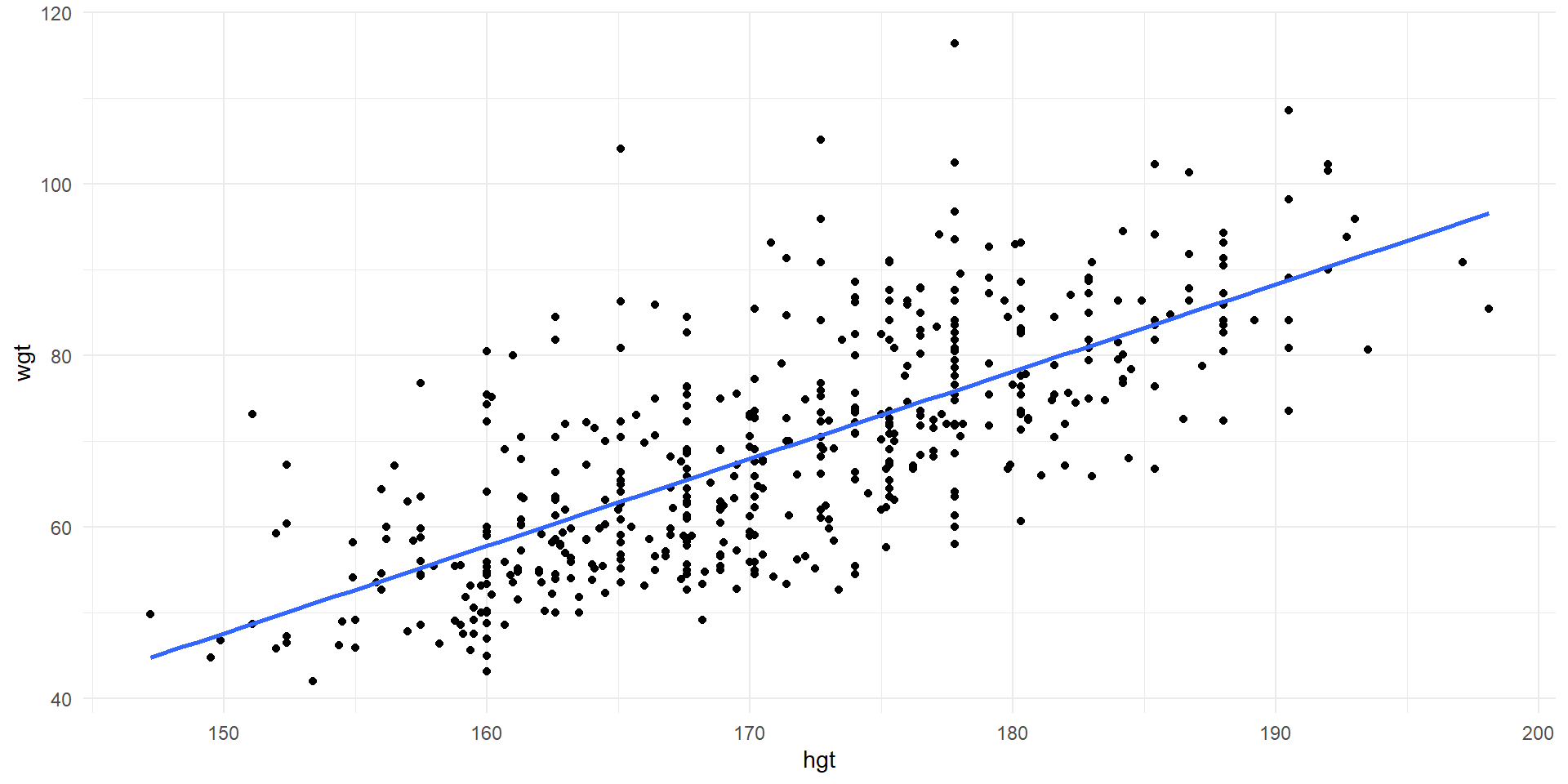
Observations of wgt vs. hgt and least squares line for the entire population.
- Least squares regression line \[\widehat{Weight}=-105.01+1.02\times Height\]
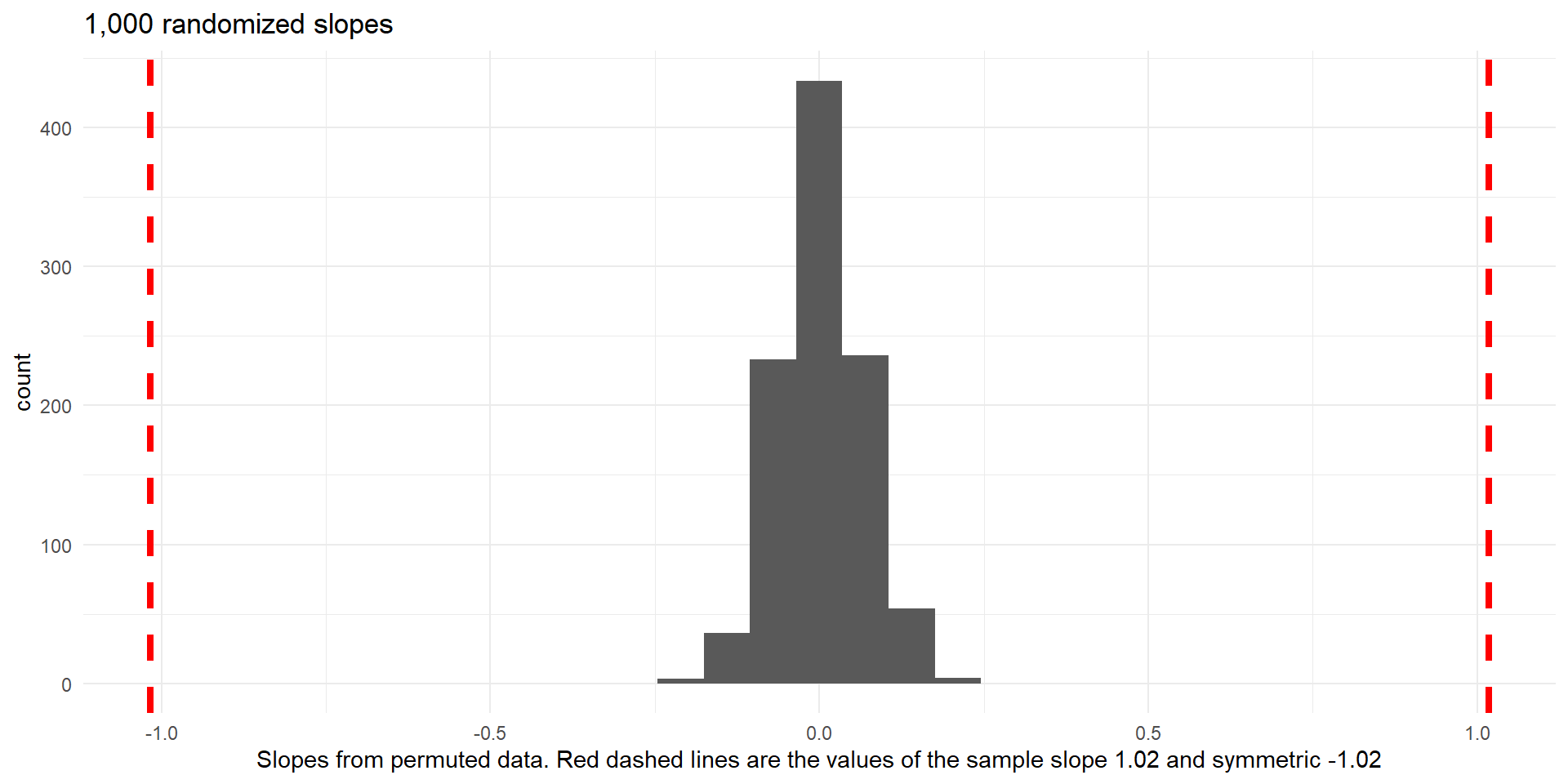
p-value \(\approx0\)
# A tibble: 1 × 2
num_extreme pval
<int> <dbl>
1 0 0Checking Conditions
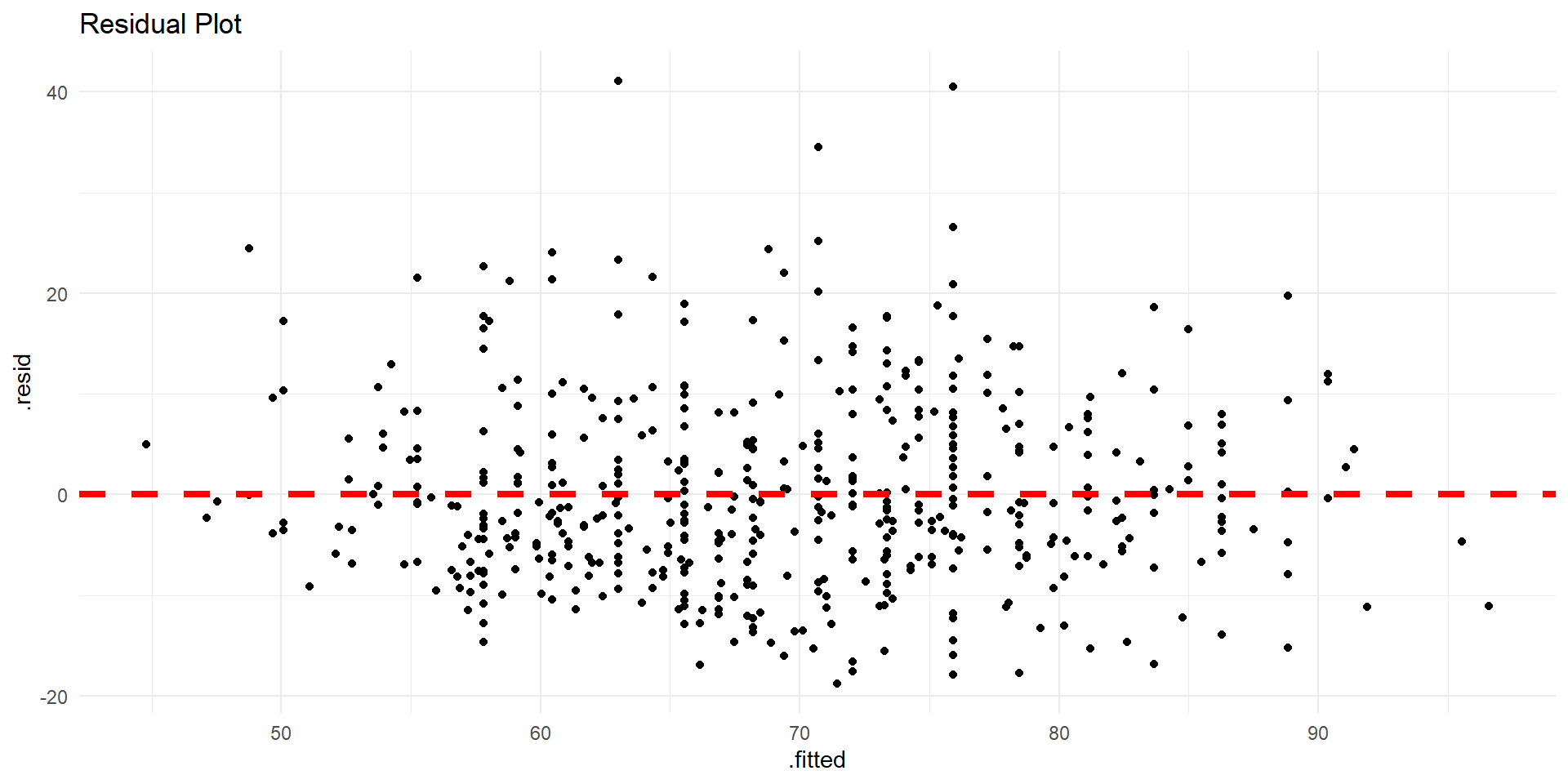
Linearity? Independent observations? Normality of residuals? Constant variability?
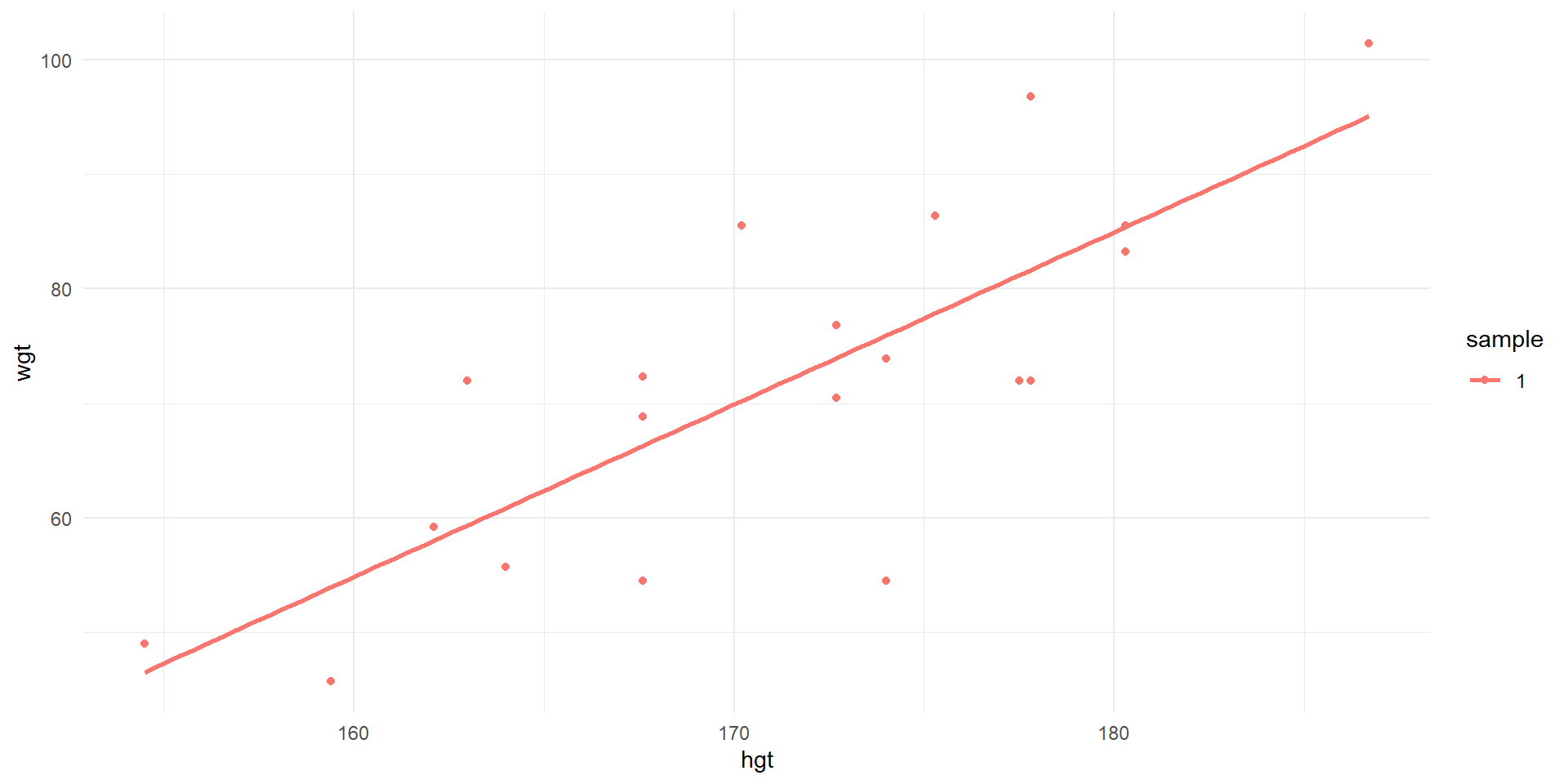
Observations of wgt vs. hgt and least squares line for first sample of 20.
Sample 1
# A tibble: 2 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) -186. 47.3 -3.94 0.000964
2 hgt 1.51 0.276 5.46 0.0000346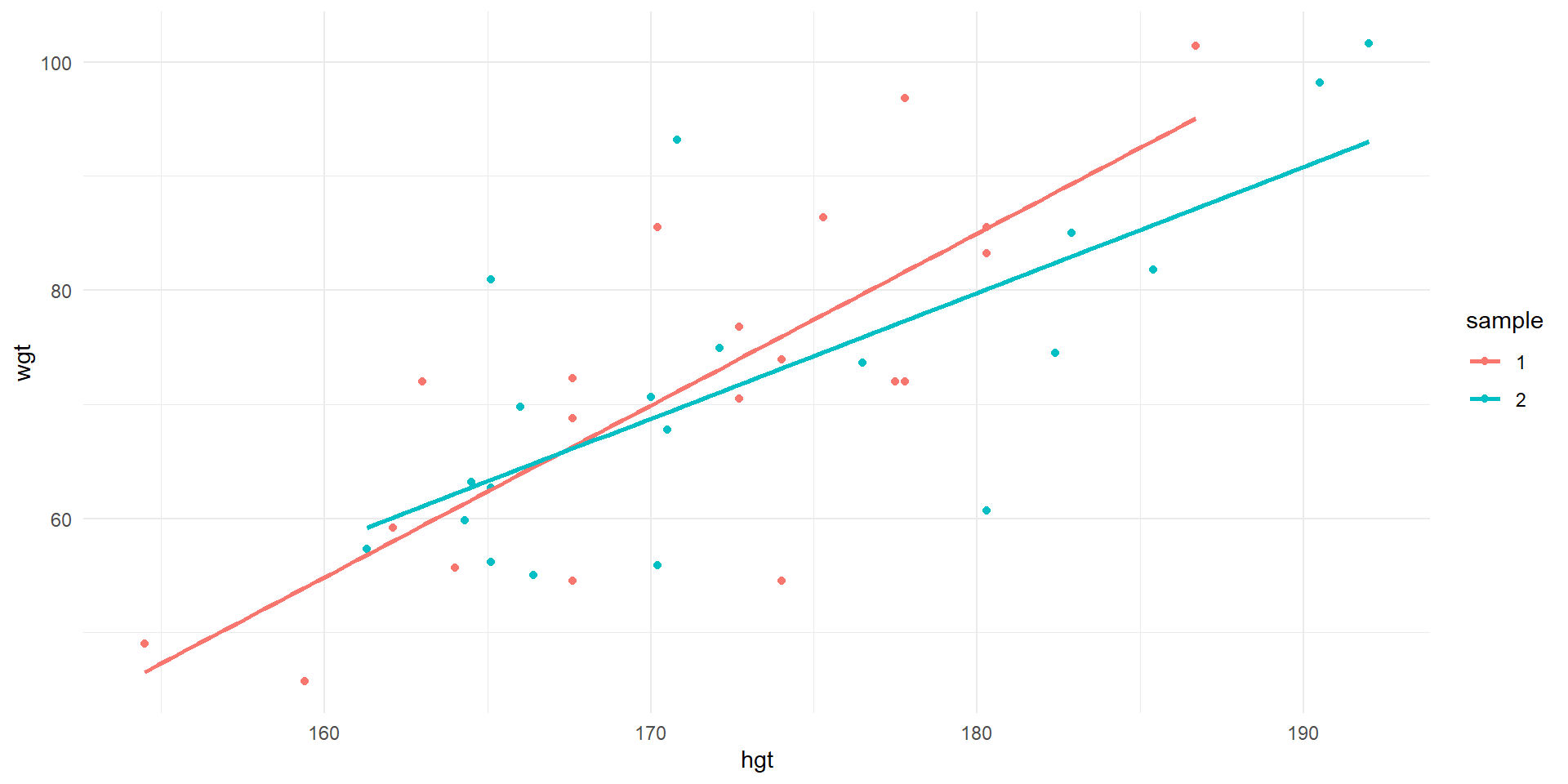
Observations of wgt vs. hgt and least squares lines for first two samples of 20.
Sample 2
# A tibble: 2 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) -119. 42.8 -2.77 0.0125
2 hgt 1.10 0.247 4.47 0.000299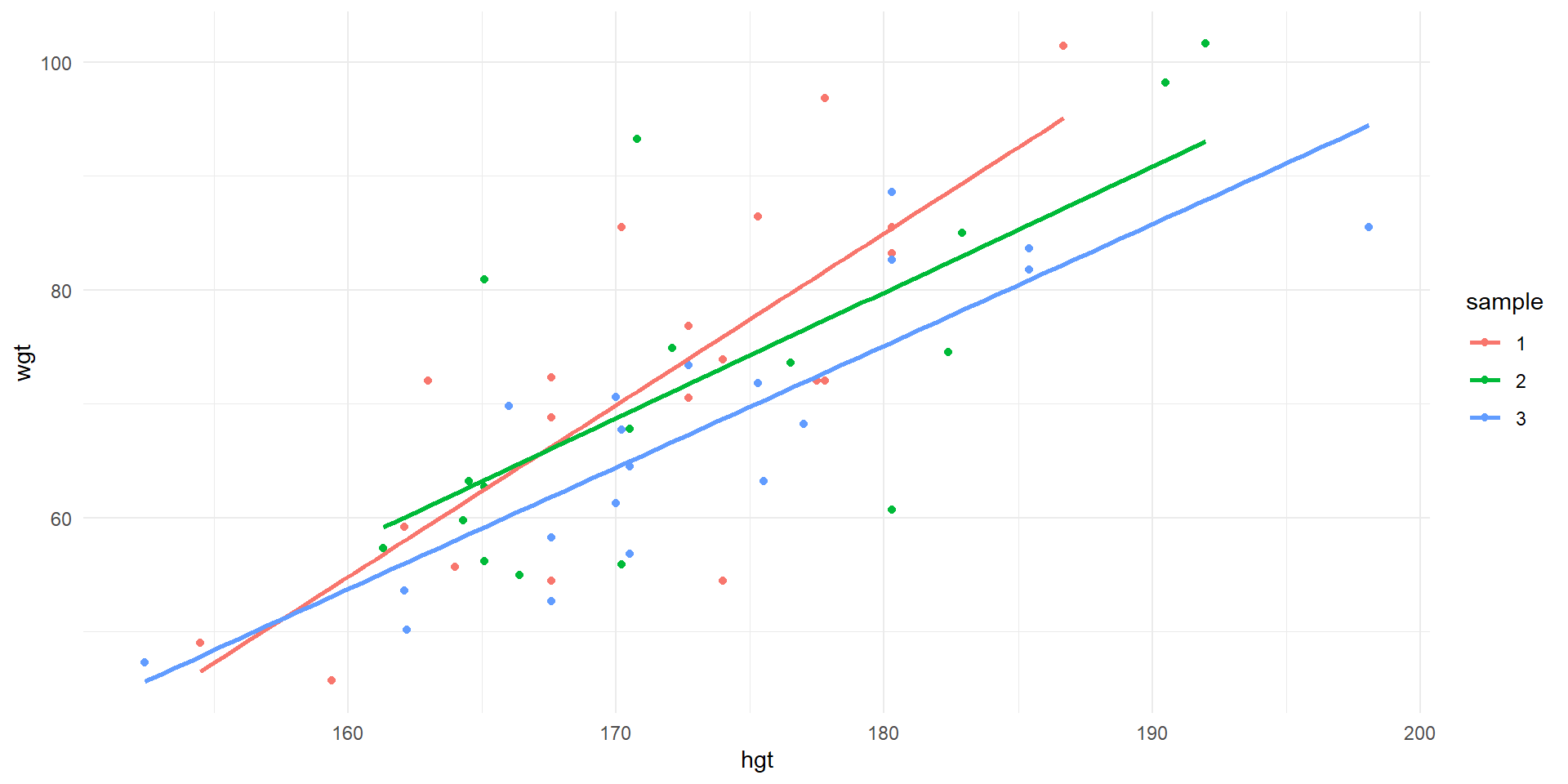
Observations of wgt vs. hgt and least squares lines for first three samples of 20.
Sample 3
# A tibble: 2 × 5
term estimate std.error statistic p.value
<chr> <dbl> <dbl> <dbl> <dbl>
1 (Intercept) -117. 26.2 -4.46 0.000299
2 hgt 1.07 0.151 7.05 0.00000140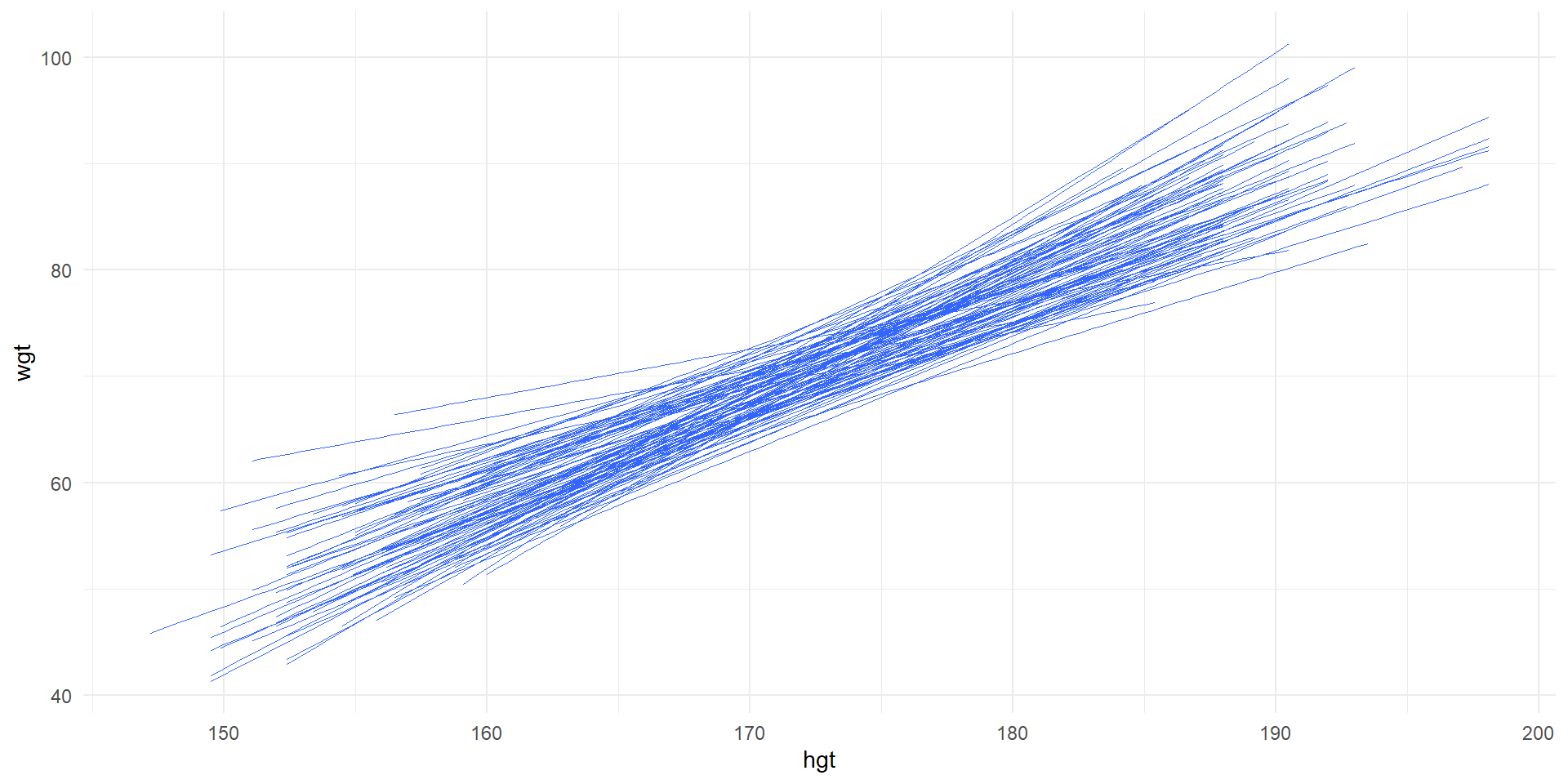
Least squares lines for 100 random samples of 20.
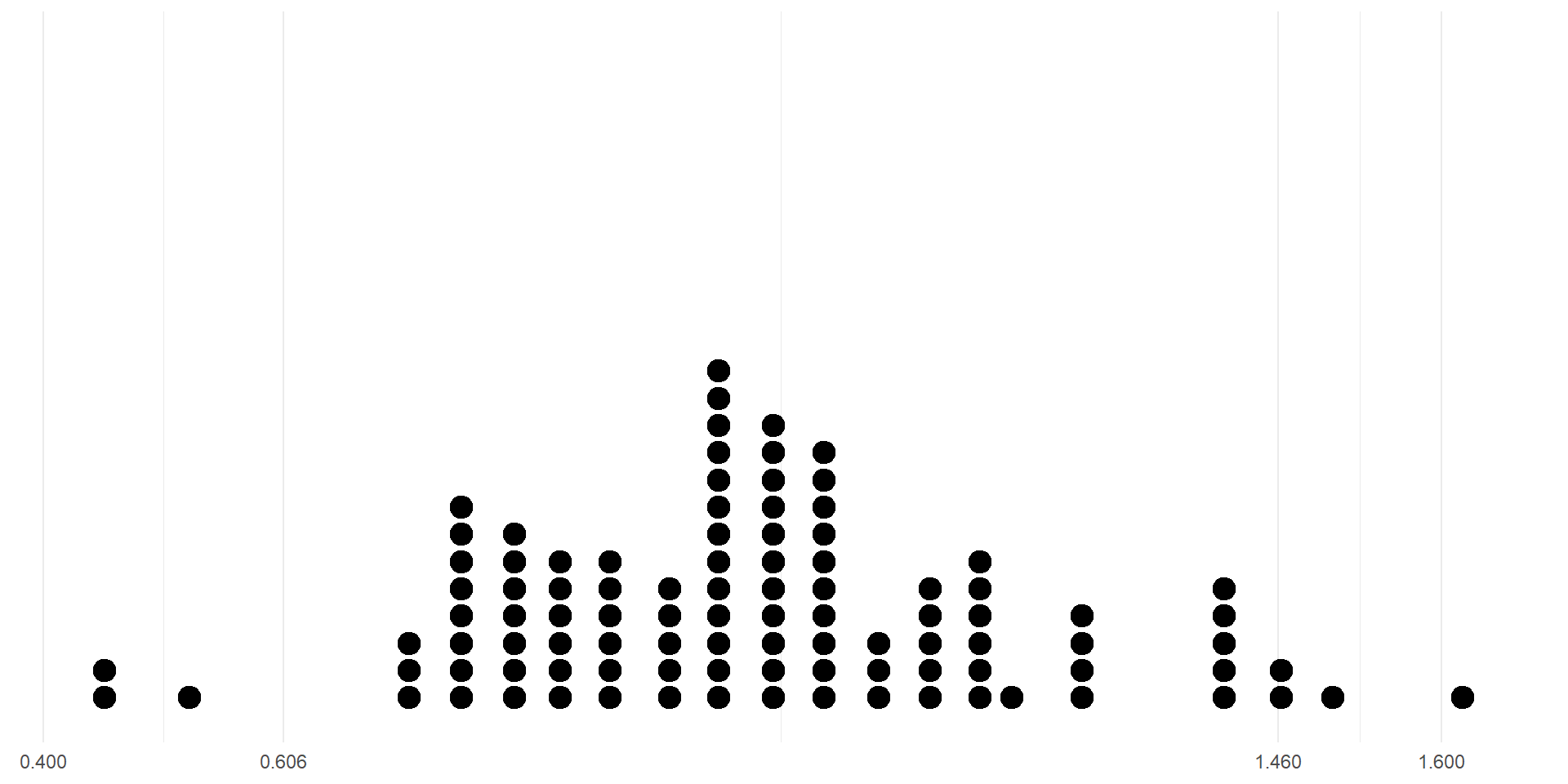
# A tibble: 1 × 3
n mean sd
<int> <dbl> <dbl>
1 100 1.01 0.221Based on a 100 simulations, we can form a 95% bootstrap CI for the slope:
# A tibble: 1 × 2
ci_lo ci_hi
<dbl> <dbl>
1 0.606 1.46CI Using Randomization
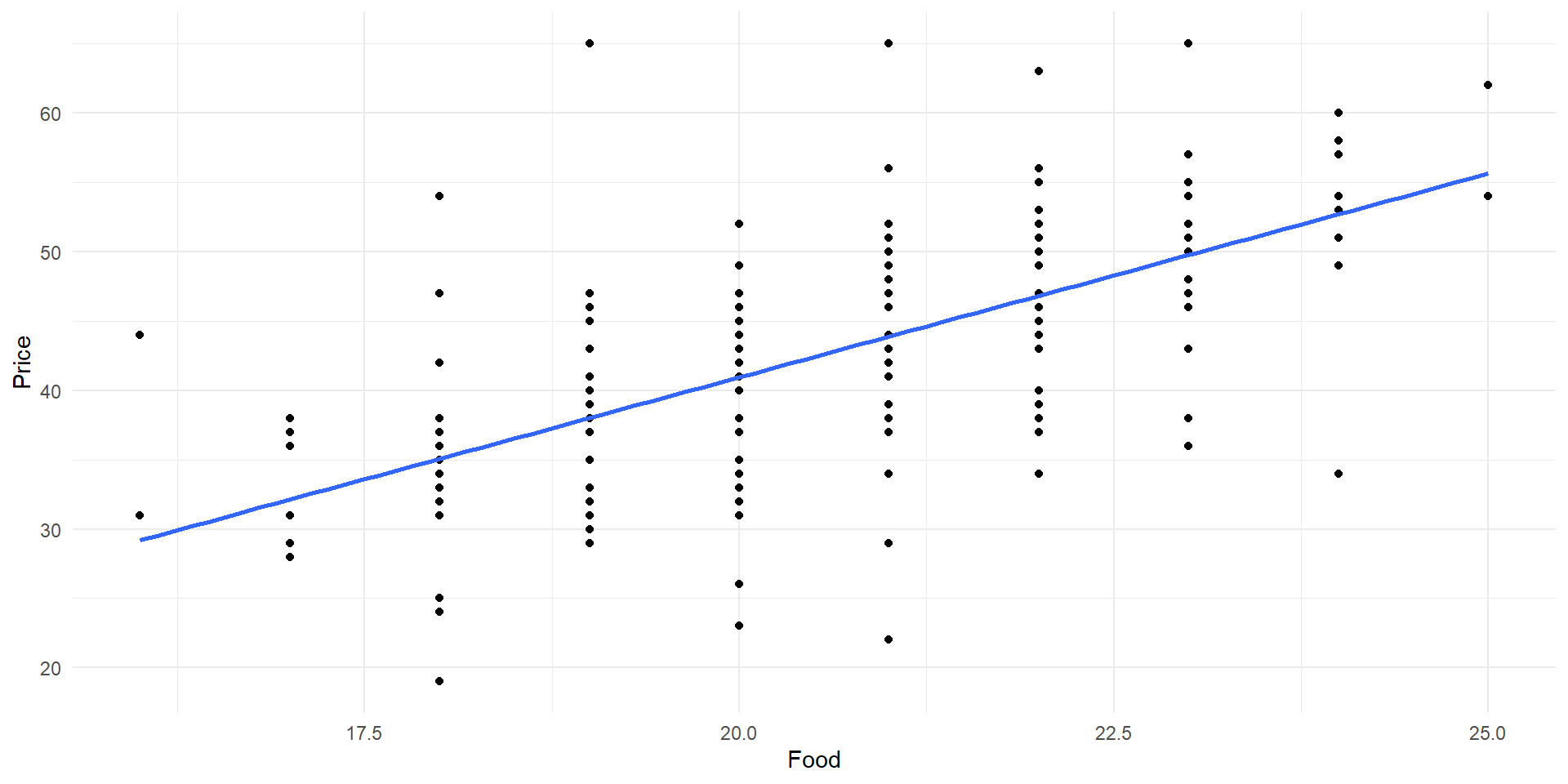
Scatter plot of Price vs Food with least squares line.
Checking Conditions
Linearity? Independent observations? Normality of residuals? Constant variability?
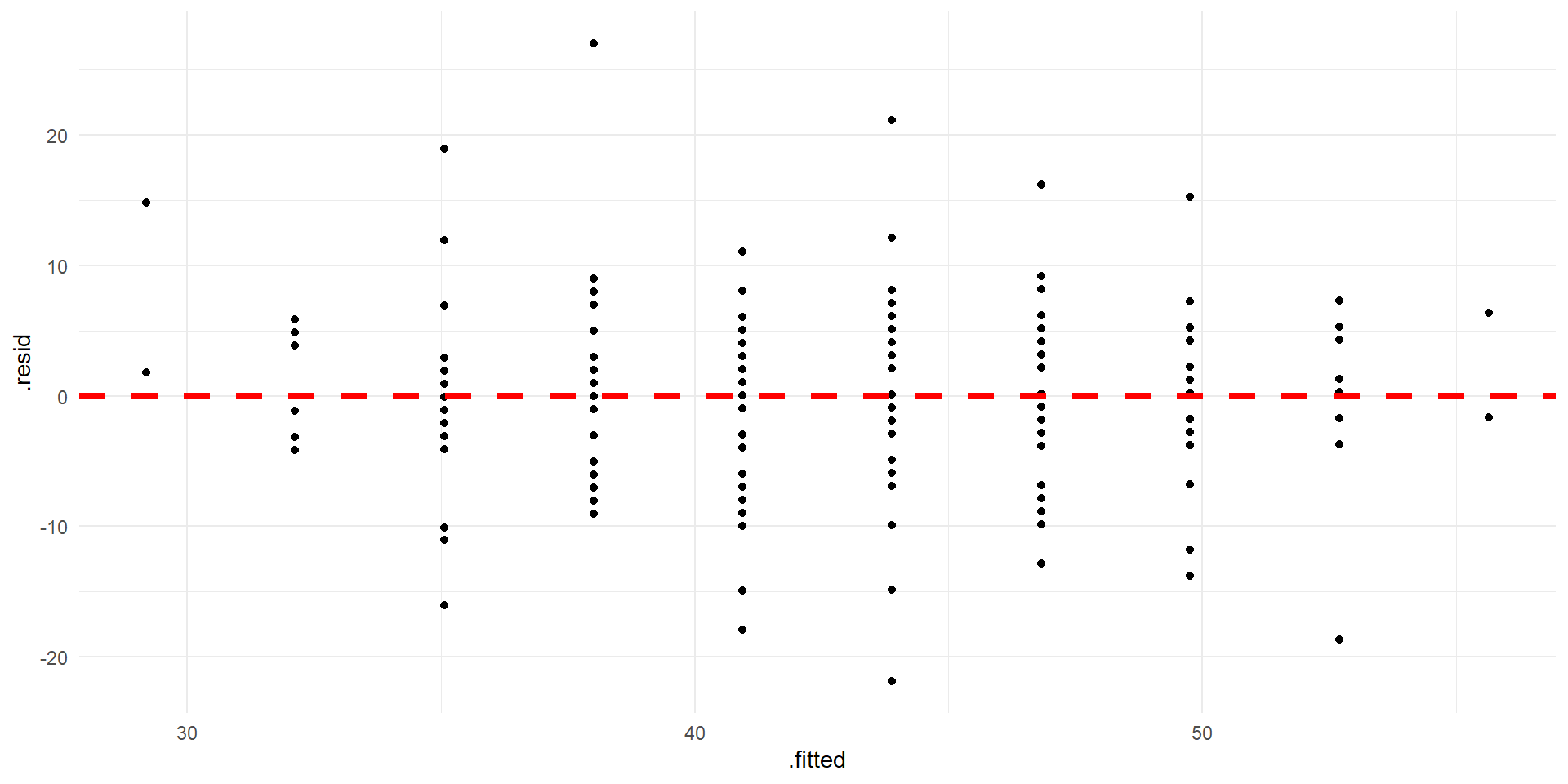
Residual plot.
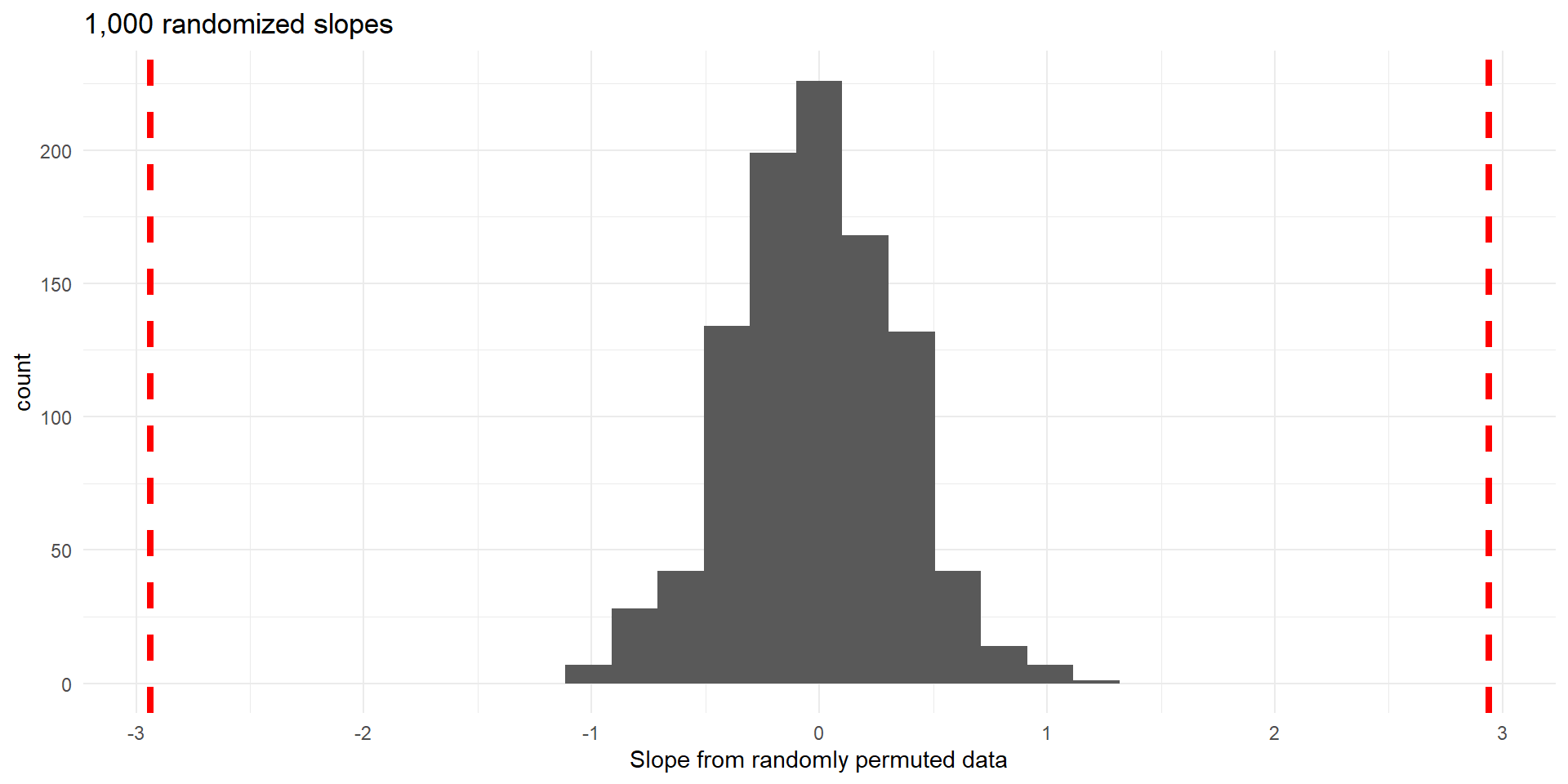
Histogram of slopes from different random permultations of Price (null distribution).
p-value \(\approx0\)
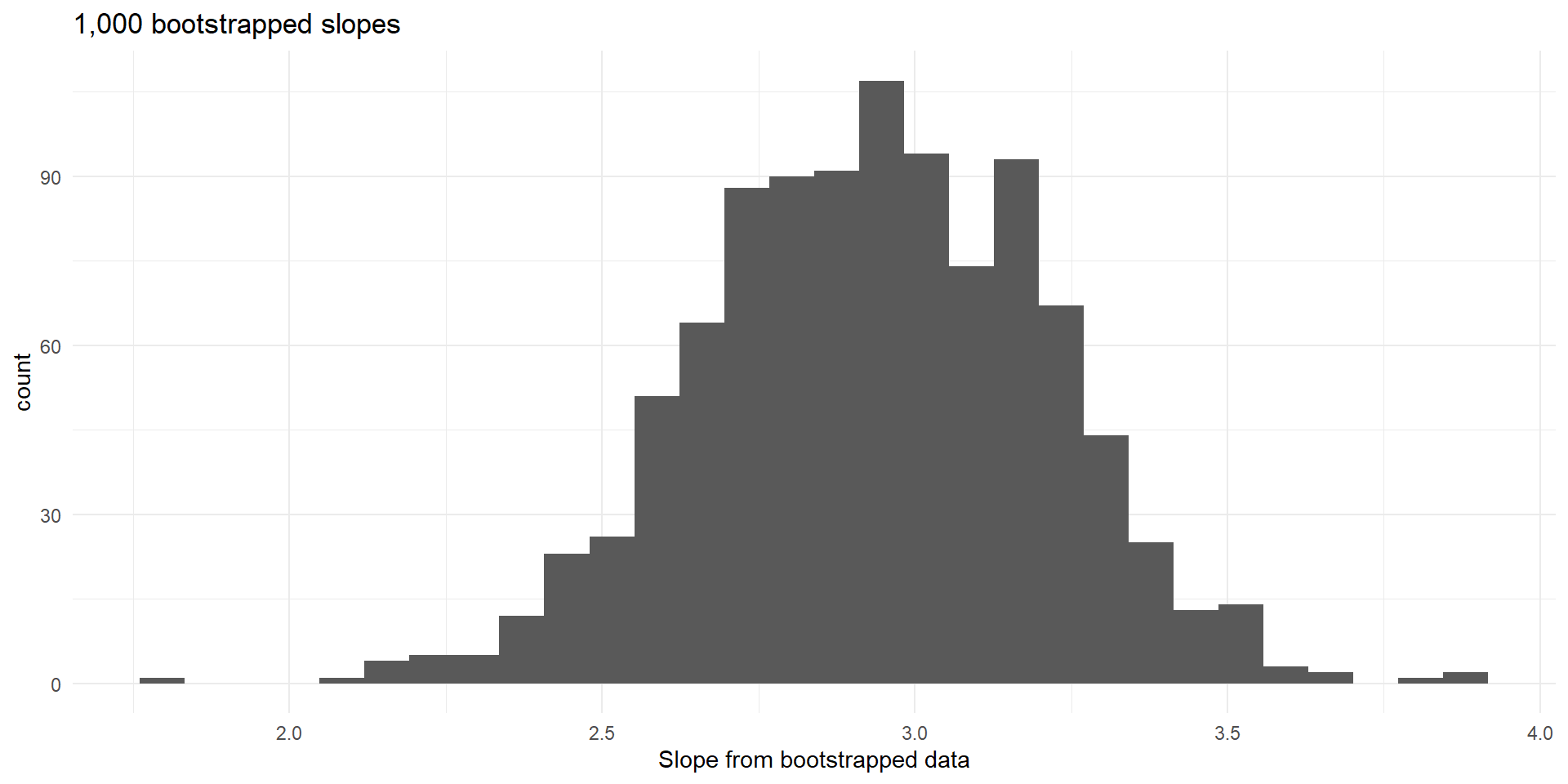
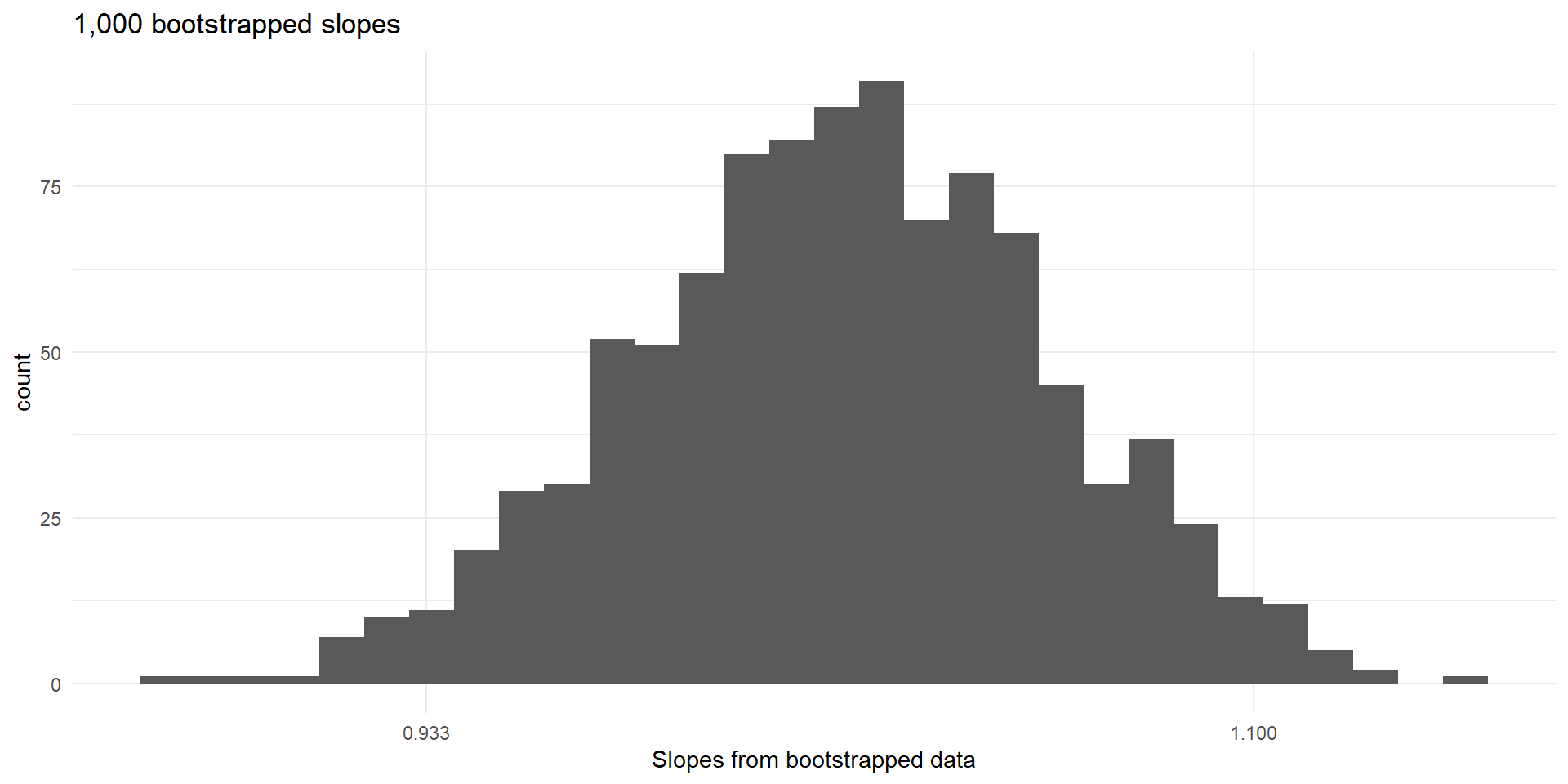
Histogram of slopes from bootstrapped data.