Confidence Intervals with Bootstrapping
Chapter 12
Math 219
Math 219
- We can begin constructing a dot plot of sample proportions
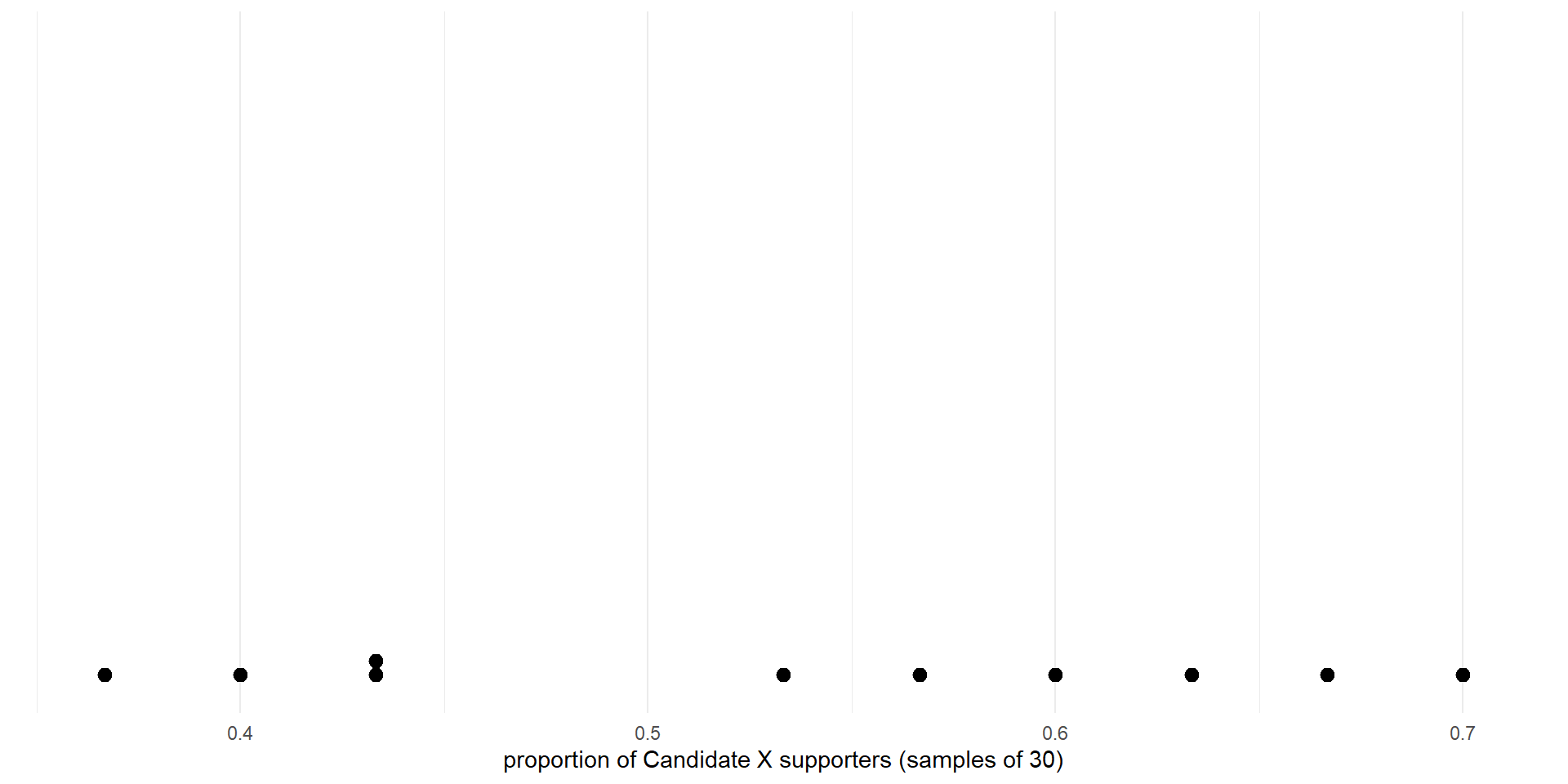
Sampling distribution. Proportions for 10 samples of 30 from a population.
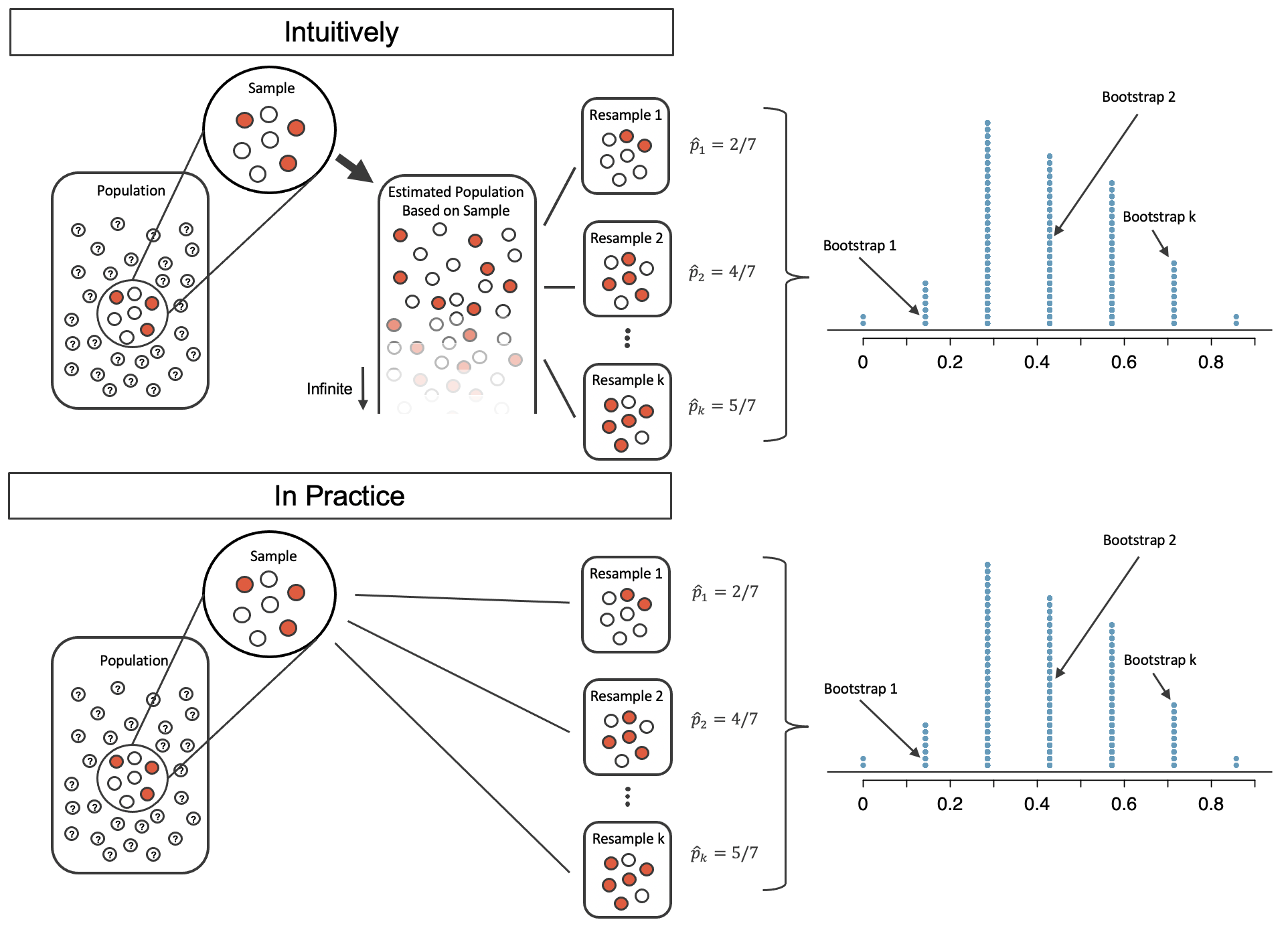
A single sample
A comparison of the process of sampling from the estimate infinite population and resampling with replacement from the original sample.(Fugure 12.5 from IMS2)
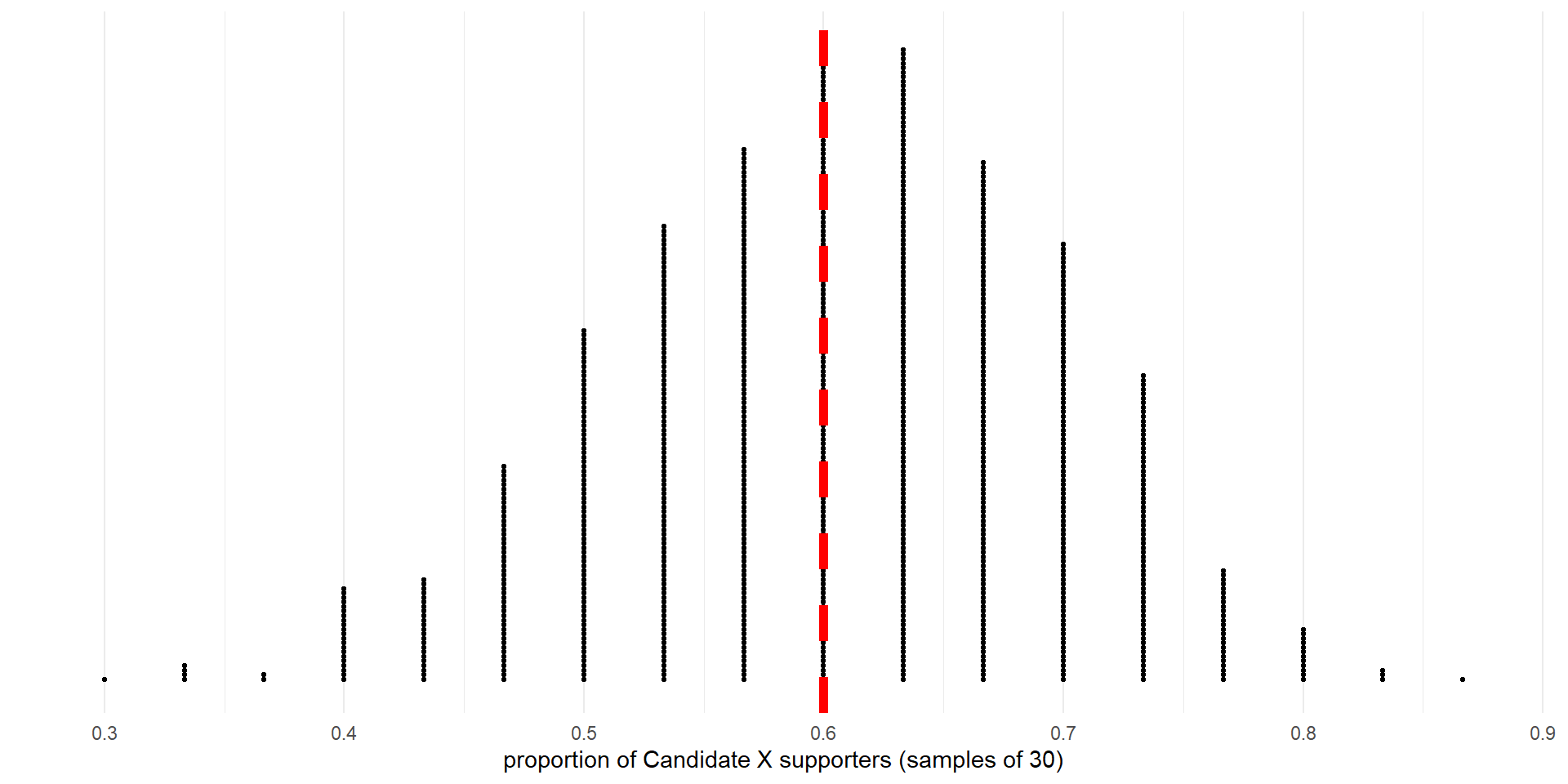
Bootstrapped sample proportions from 1000 samples.
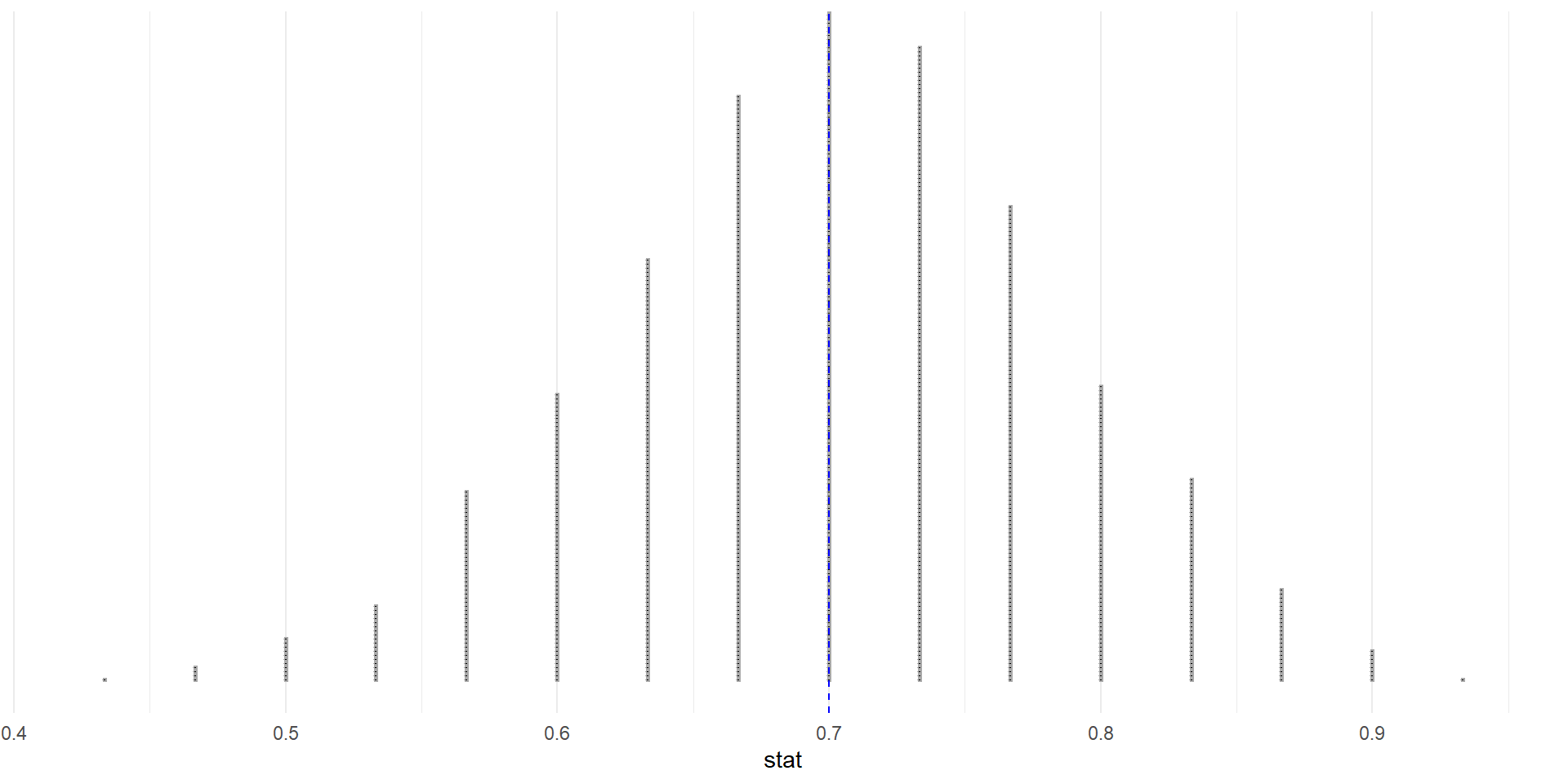
Properties of Confidence Intervals
- The confidence interval will contain the observed value of the statistic. (at or near the center of the interval)

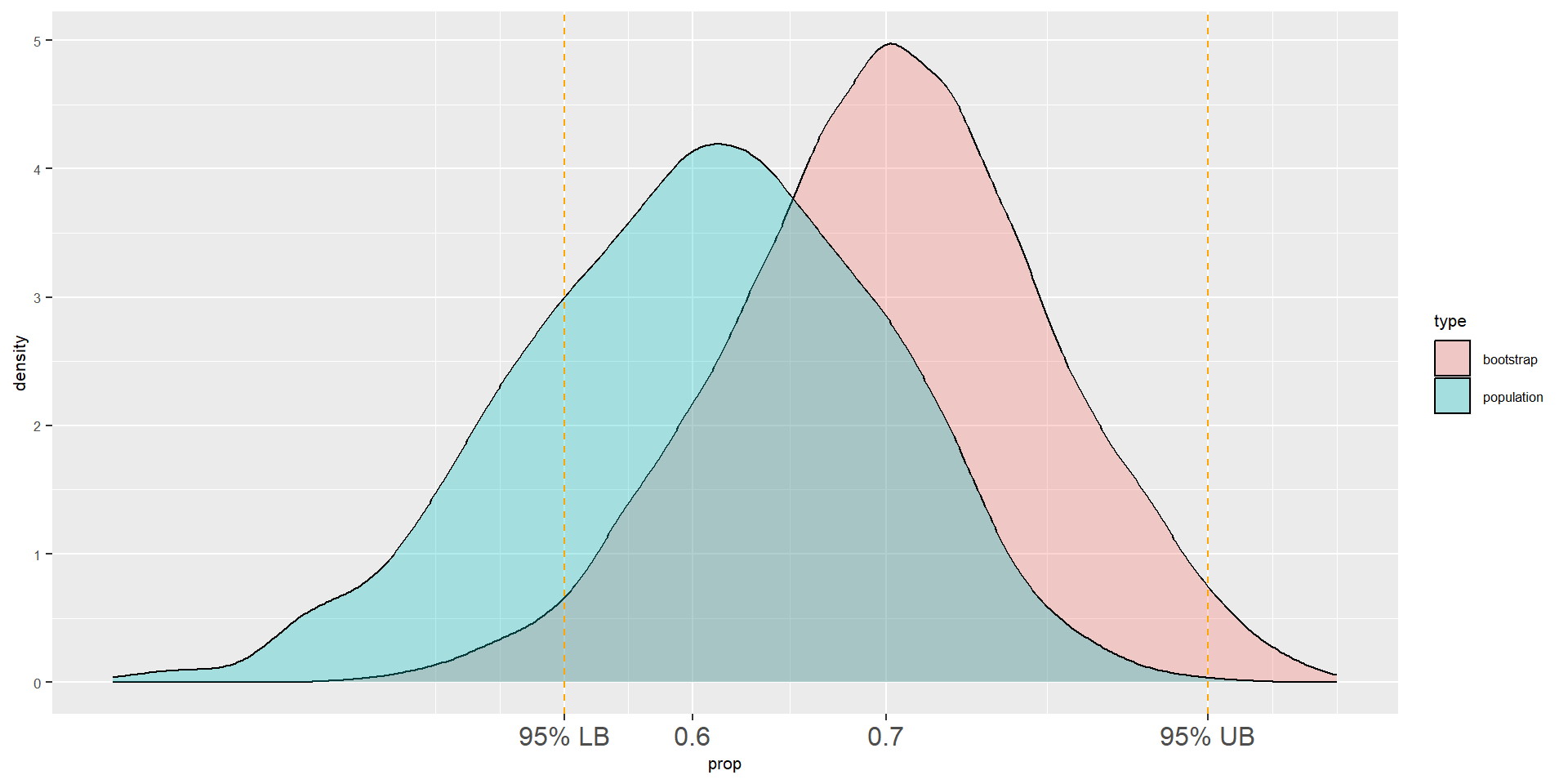
Two density plots
- Let’s place the population density plot and the bootstrap density plot together
- As you can see, the true value of the parameter (0.6) is inside of the 95% CI
Why Do Bootstrap Confidence Intervals Work?

Illustration of sampling distribution and bootstrap distribution. From IMS2 Tutorial 4.4.
- Bootstrap distribution has approximately same SE as sampling distribution