Hypothesis Testing with Randomization
Chapter 11
Math 219
Math 219
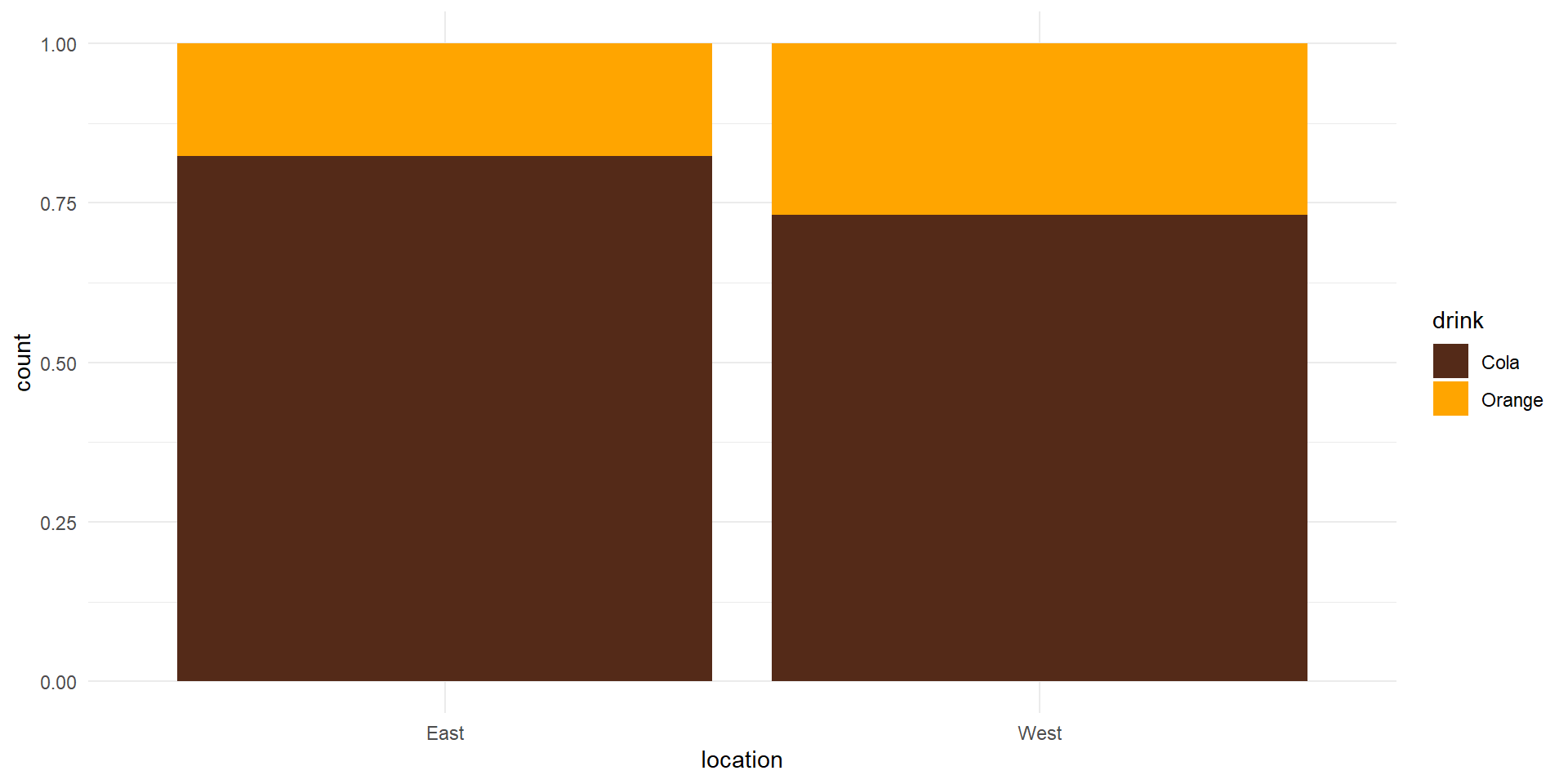
Null Distribution Using Random Permutation
- The sample data we collected represent the best available picture of the distribution of the drinkers on the coasts
![Responses in the data]()

Random Permutation
- To simulate the null hypothesis being true (no difference between West Coast and East Coast), I could shuffle the responses, split them into two piles according to sample sizes and calculate the new difference of sample proportions

- If I do this many times it will give me a good idea of what the differences would look like if the null hypothesis is true (the null distribution)
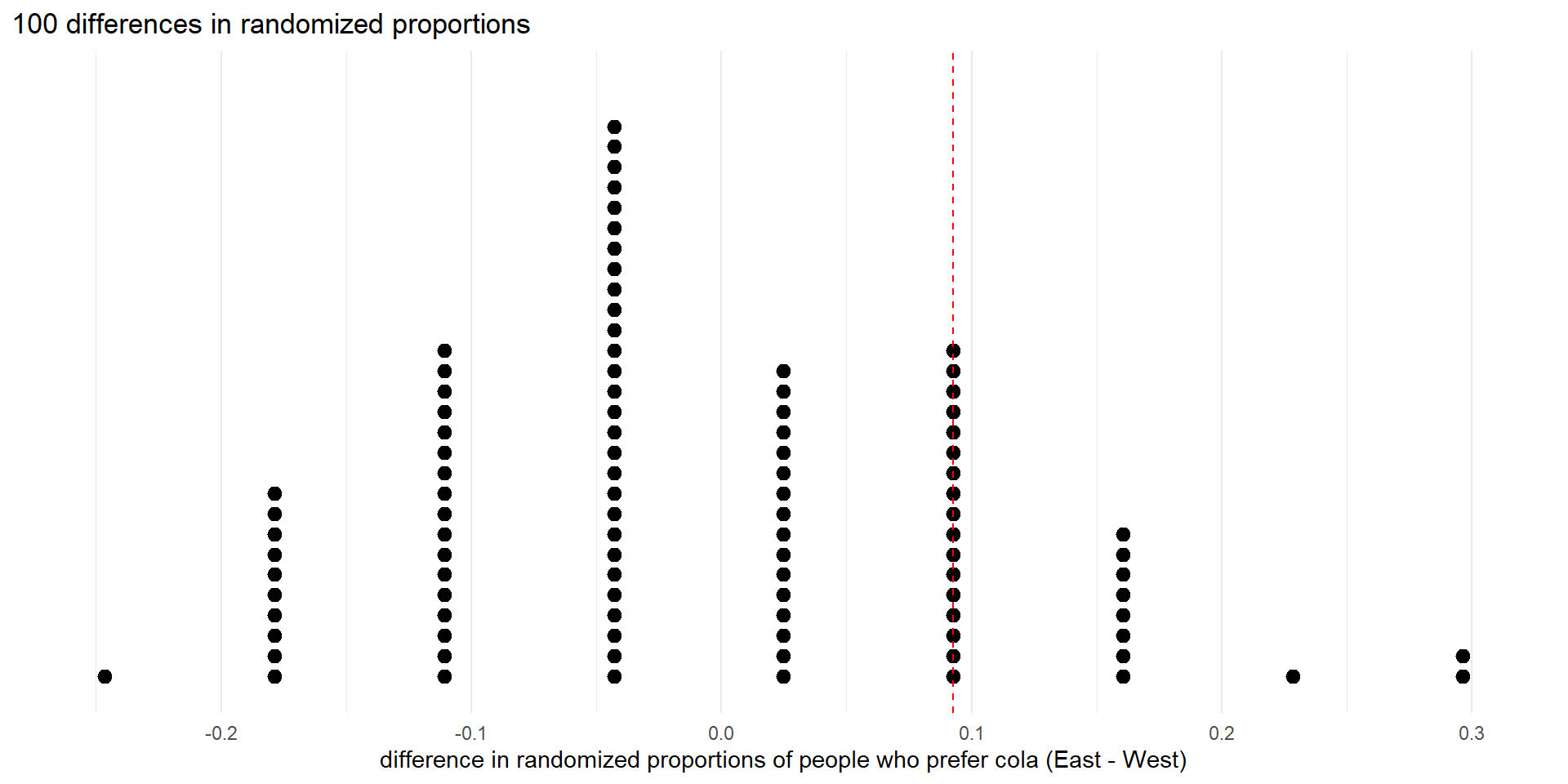
Dot plot of 100 differences in randomized proportions (null distribution), showing observed difference as dashed vertical line.
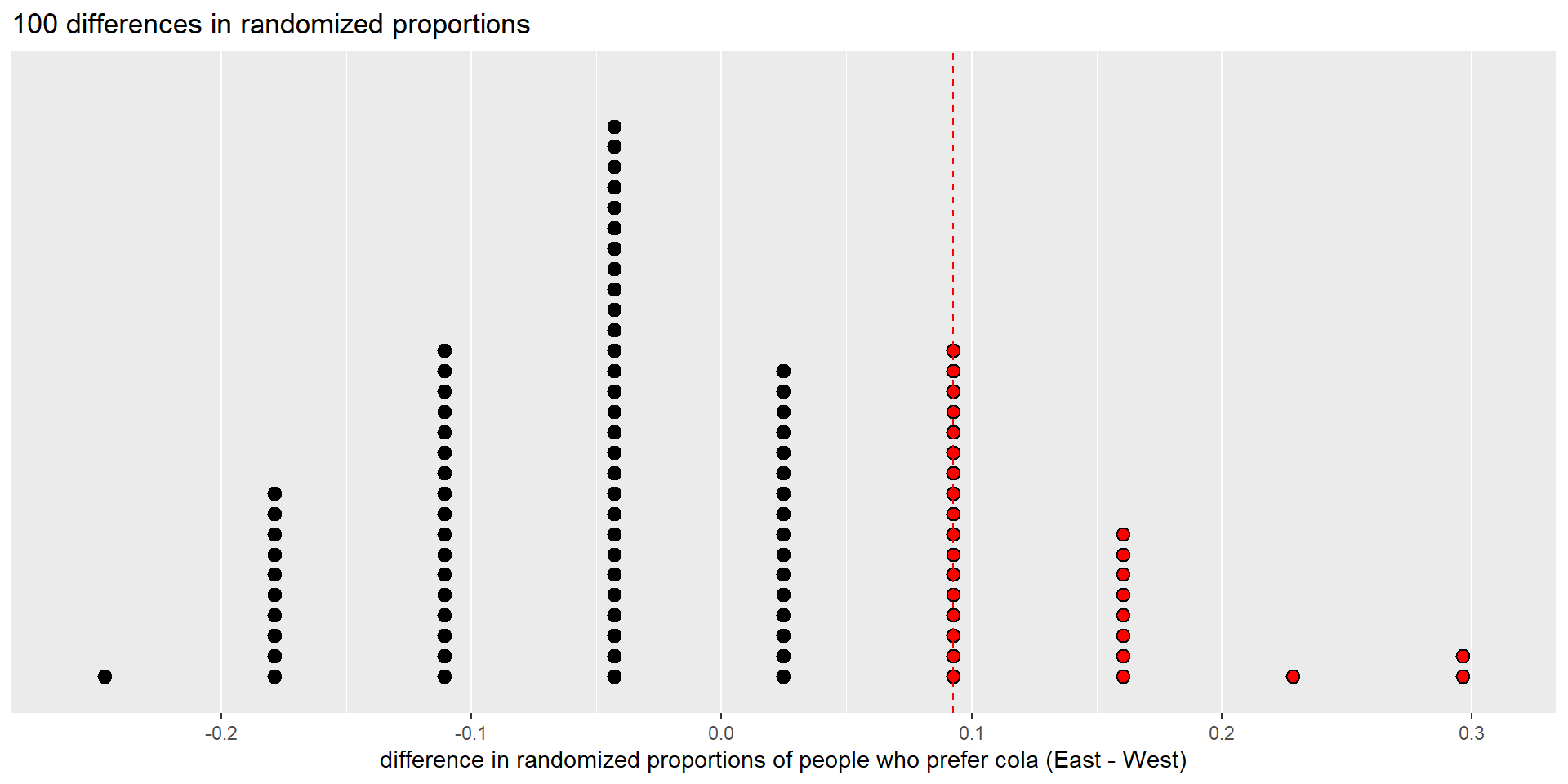
Red dots are as large or larger than the observed test statistic.
There are 28 differences in randomization proportions that are greater than or equal to the observed value (0.09276). So we estimate the p-value to be 28/100 = 0.28.
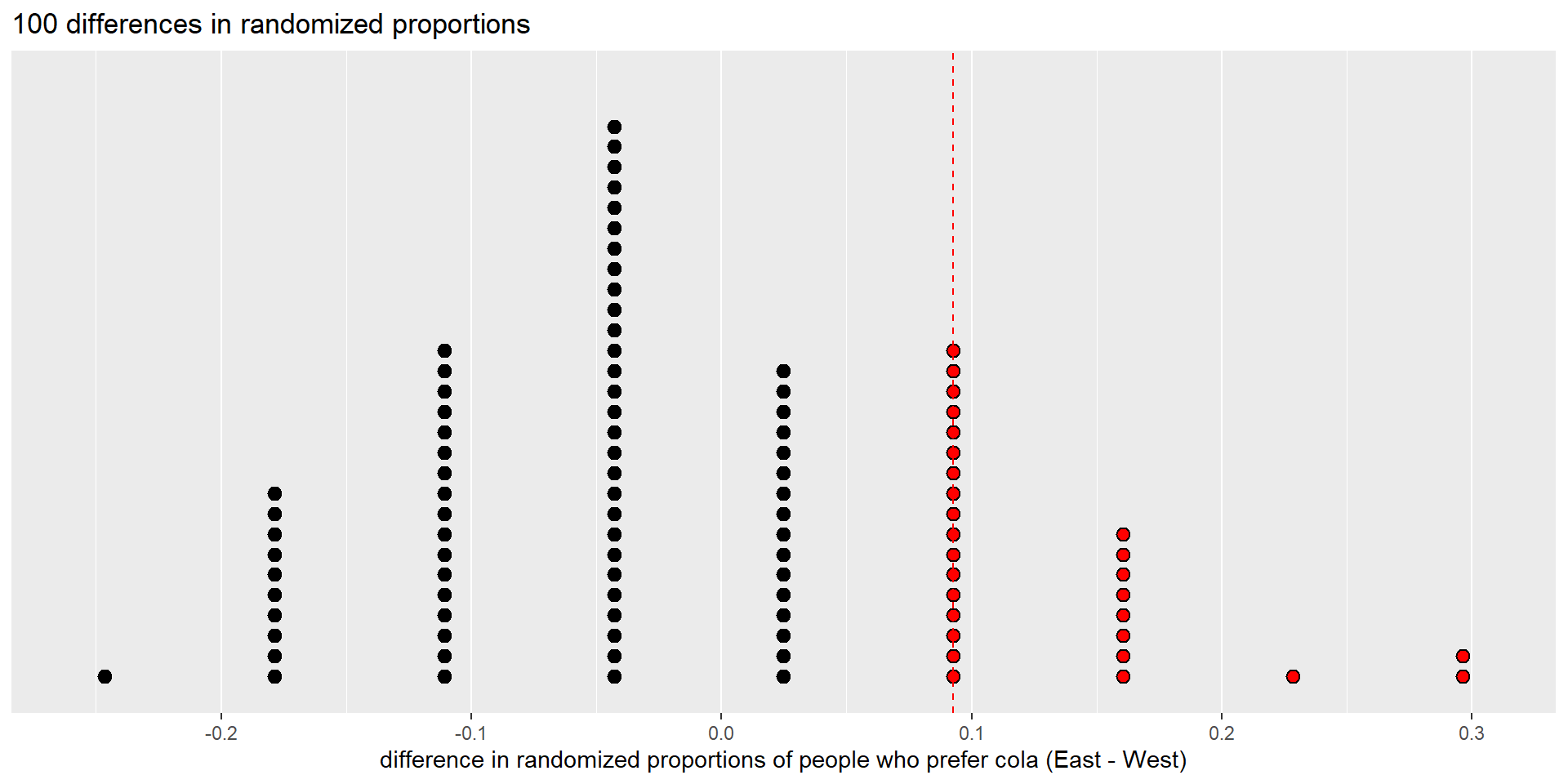
The p-value is the proportion of red dots.