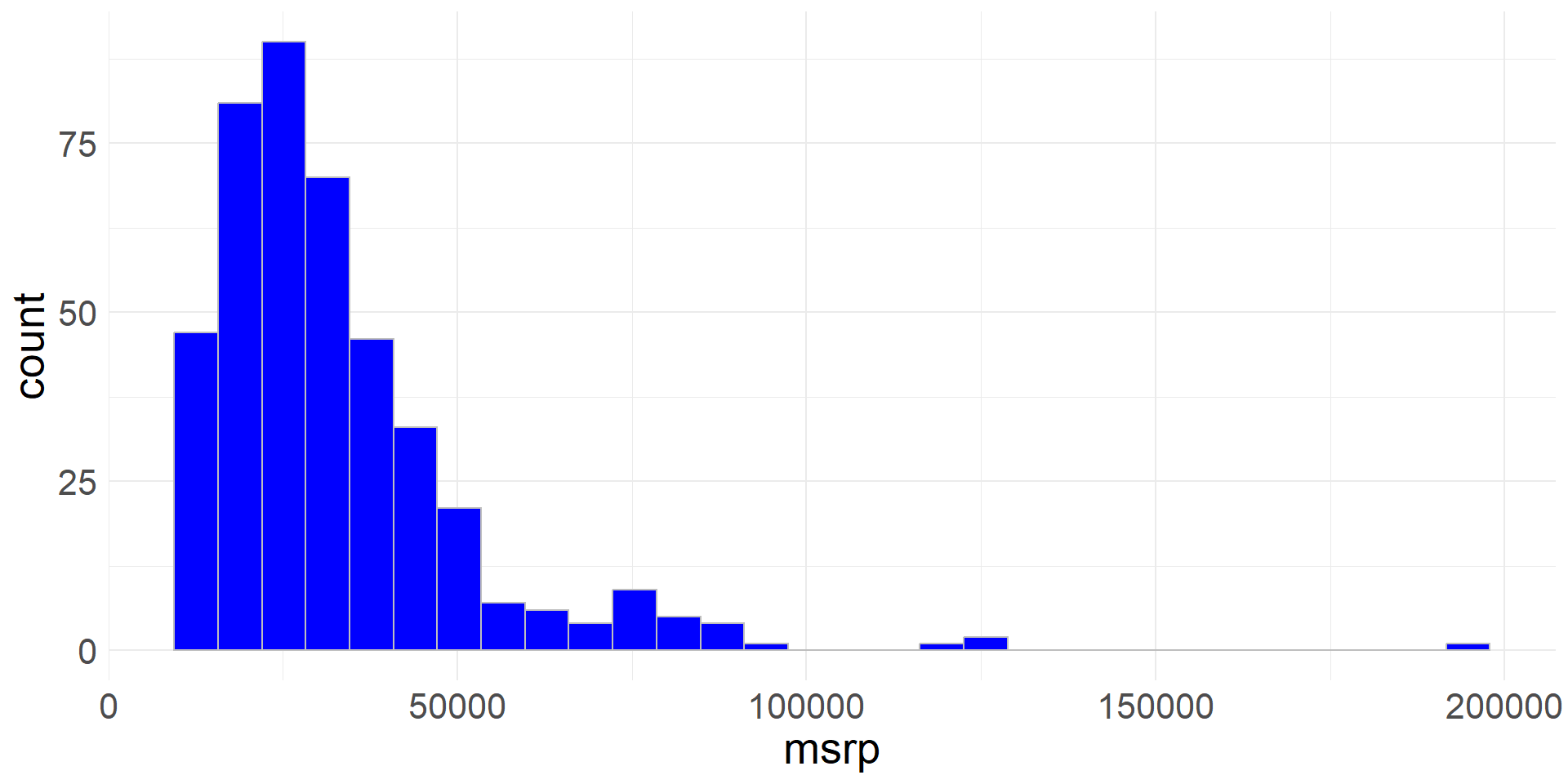
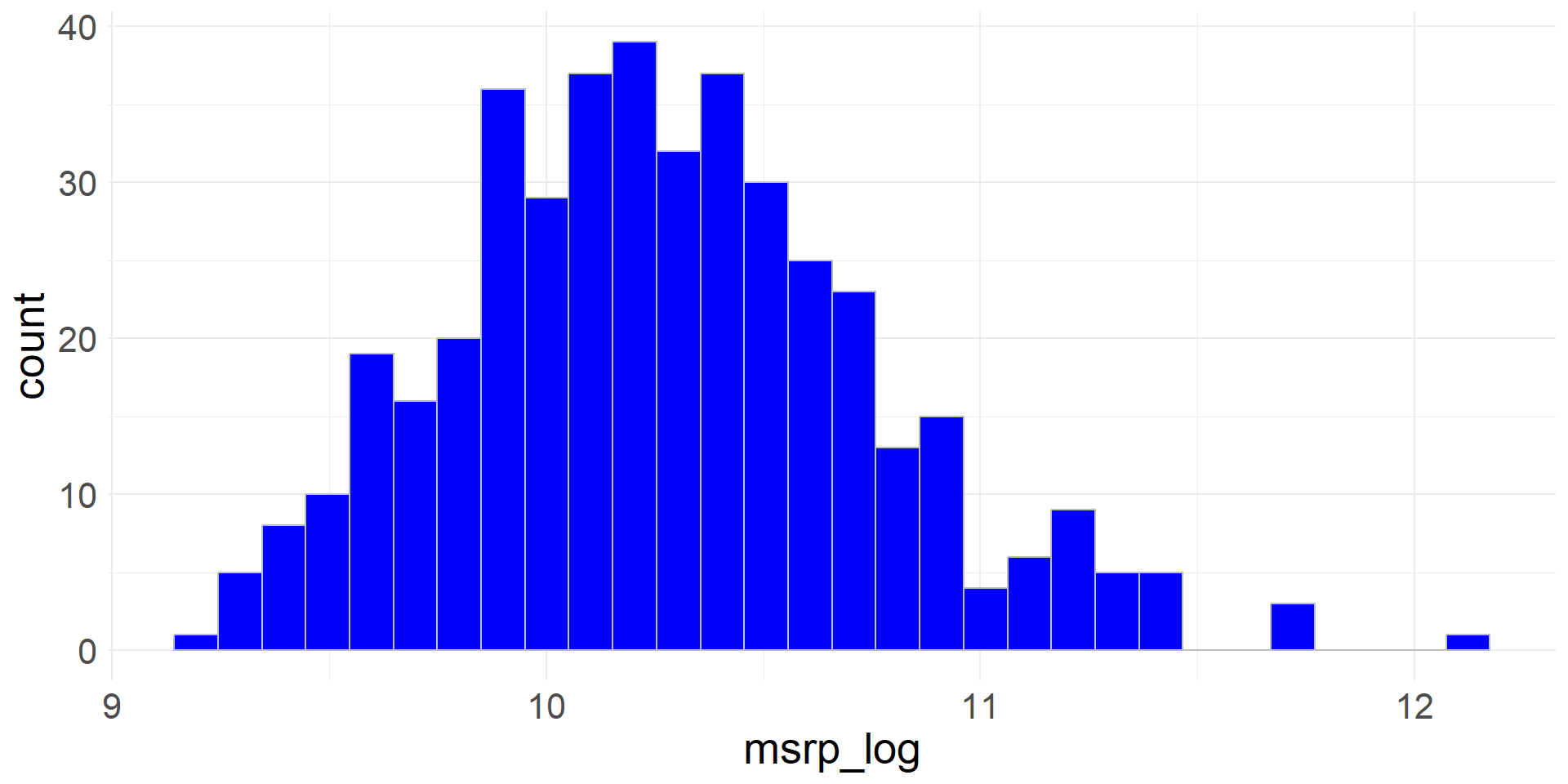
Rows: 3,142
Columns: 4
$ state <chr> "Alabama", "Alabama", "Alabama", "Alabama", "Alabama", "Ala…
$ county <chr> "Autauga County", "Baldwin County", "Barbour County", "Bibb…
$ expectancy <dbl> 76.060, 77.630, 74.675, 74.155, 75.880, 71.790, 73.730, 73.…
$ income <dbl> 37773, 40121, 31443, 29075, 31663, 25929, 33518, 33418, 312…Exploring Numerical Data
Chapter 5
Math 215
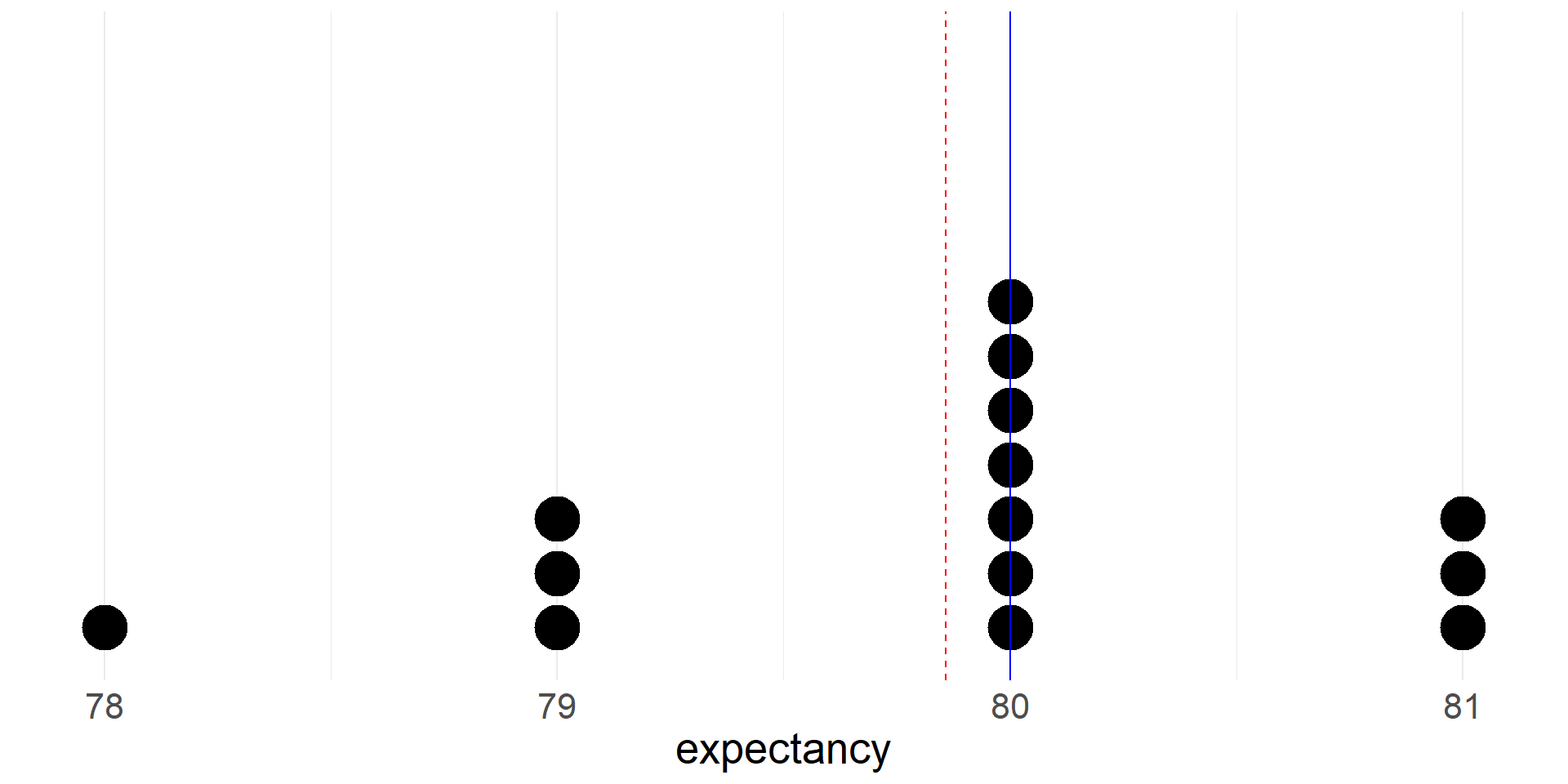
Life Expectancies in MA Counties
- Now we can take a look on a dotplot of life expectancies for the fourteen MA counties
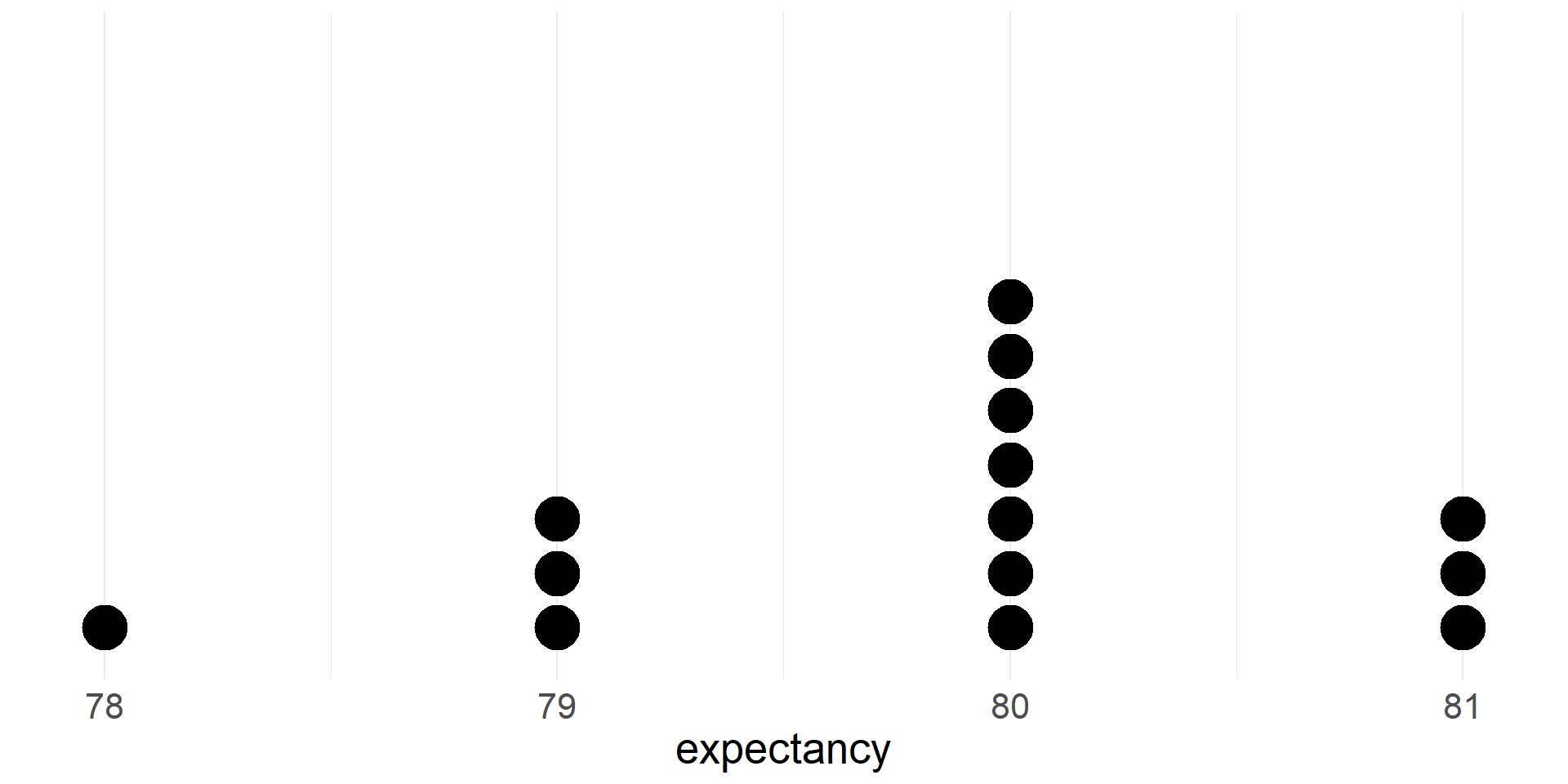
- Shape: Skewed to the left, Unimodal
- Mode = 80 (the most commonly occurring data point)
- Max = 81, Min = 78, Range = Max - Min = 81-78=3
- Let’s see where the mean and median fall on the dotplot
- Note that the mean is pulled toward the left tail of the distribution.
Skew and Symmetry

Box plot for the five number summary
- The box extends from Q1 to Q3 with a vertical line at the median (Q2)
- Whiskers extend from the box to the smallest and largest values that are not outliers
- Outliers are plotted as individual points according to \(1.5\times\)IQR rule
# A tibble: 1 × 7
min Q1 median Q3 max iqr range
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 78 79.2 80 80 81 0.75 3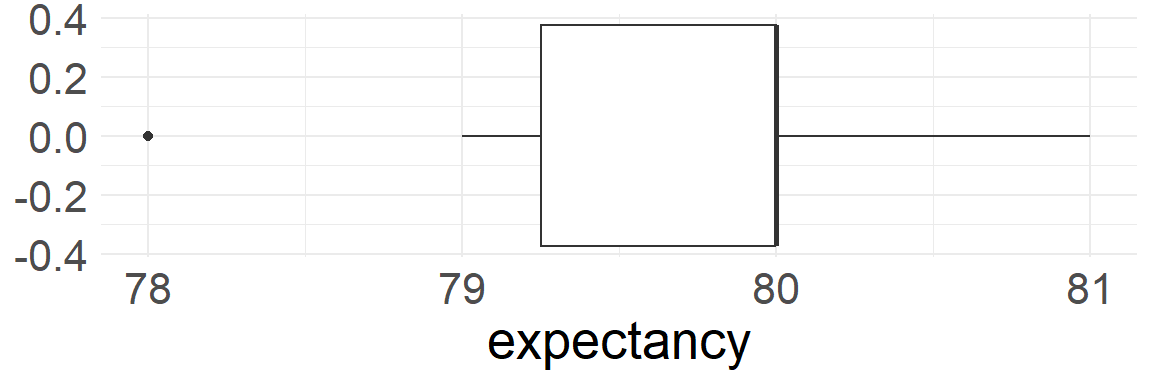
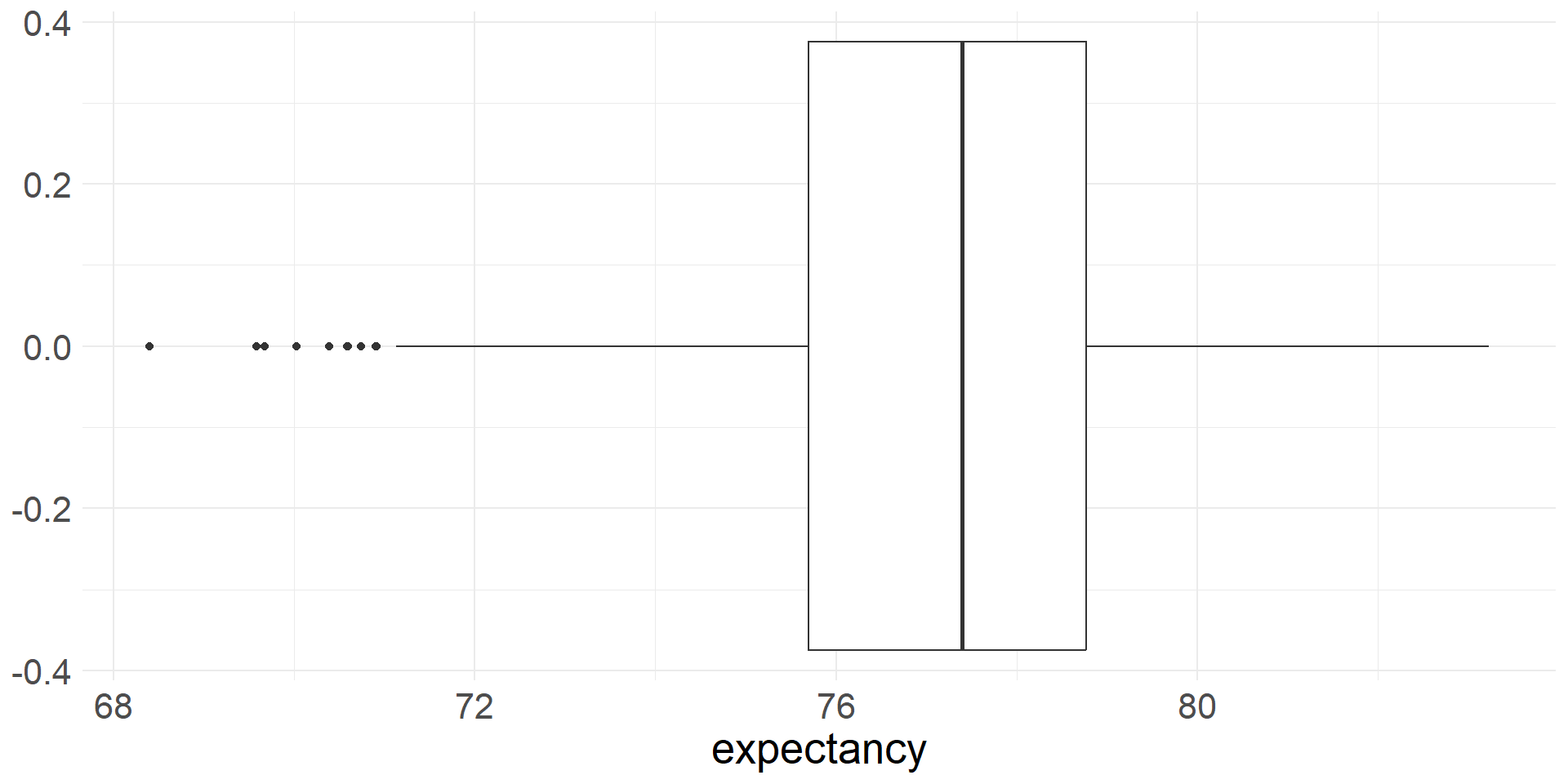
- Here is the boxplot of the life expectancy of the entire dataset
- For many numeric variables the following rules of thumb apply:
- Roughly 68% of the data fall within 1 standard deviation of the mean
- Roughly 95% of the data fall within 2 standard deviations of the mean
- Roughly 99.7% of the data fall within 3 standard deviations of the mean
Illustrations of 68-95-99.7 rule. IMS1 Figure 5.7.
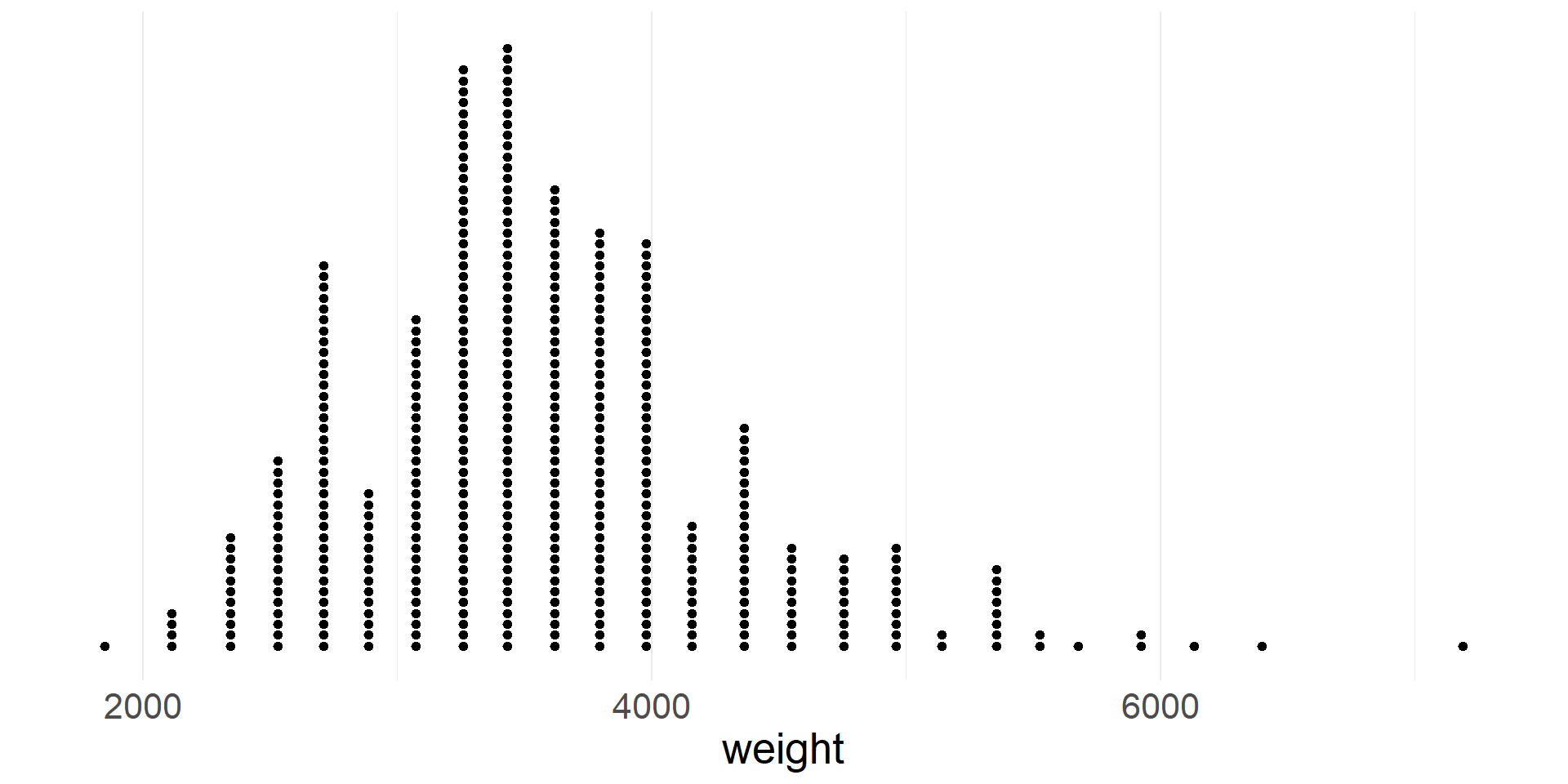
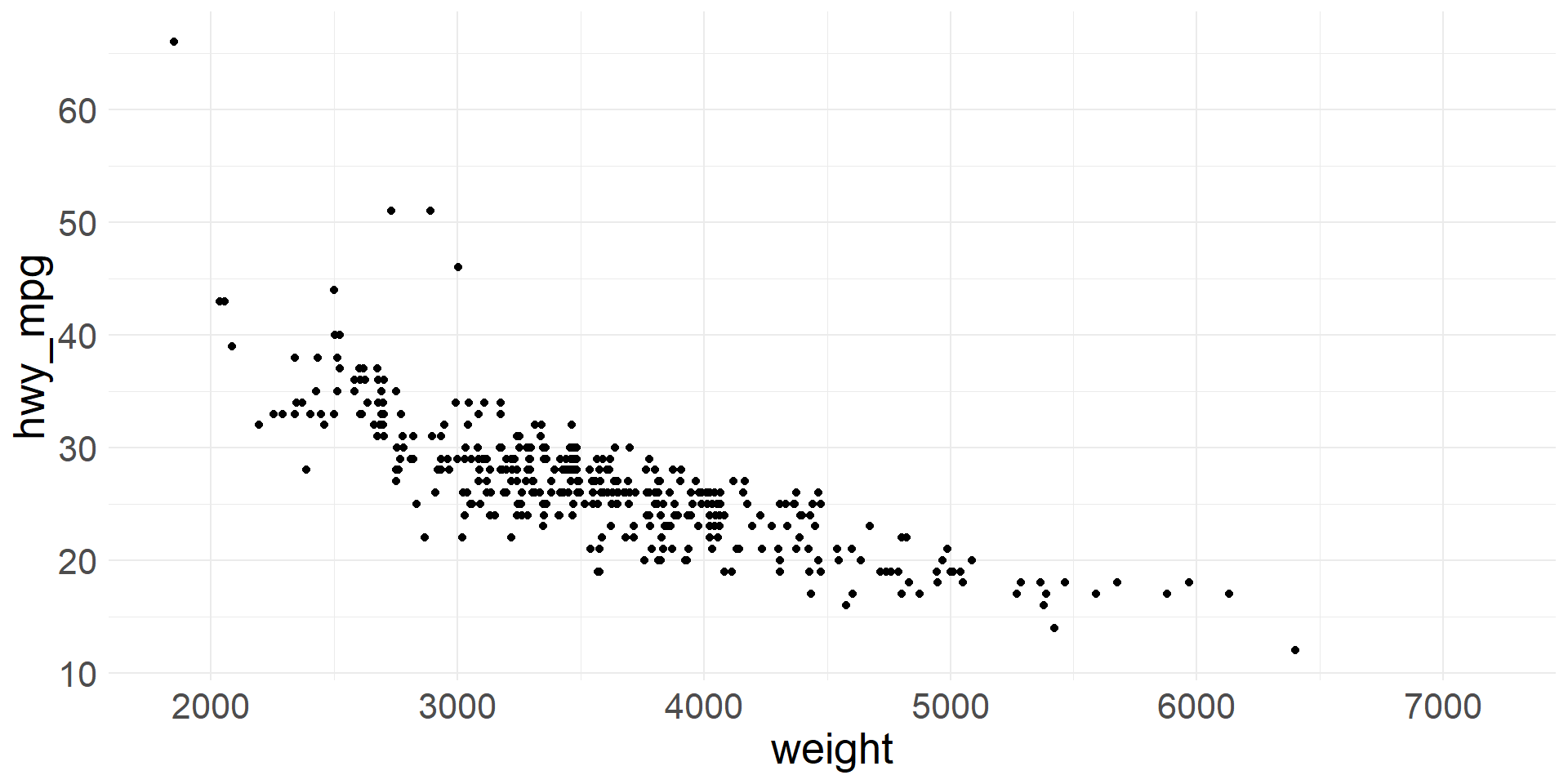
- Note that the distribution of weights is skewed right, meaning that it has a tail on the right
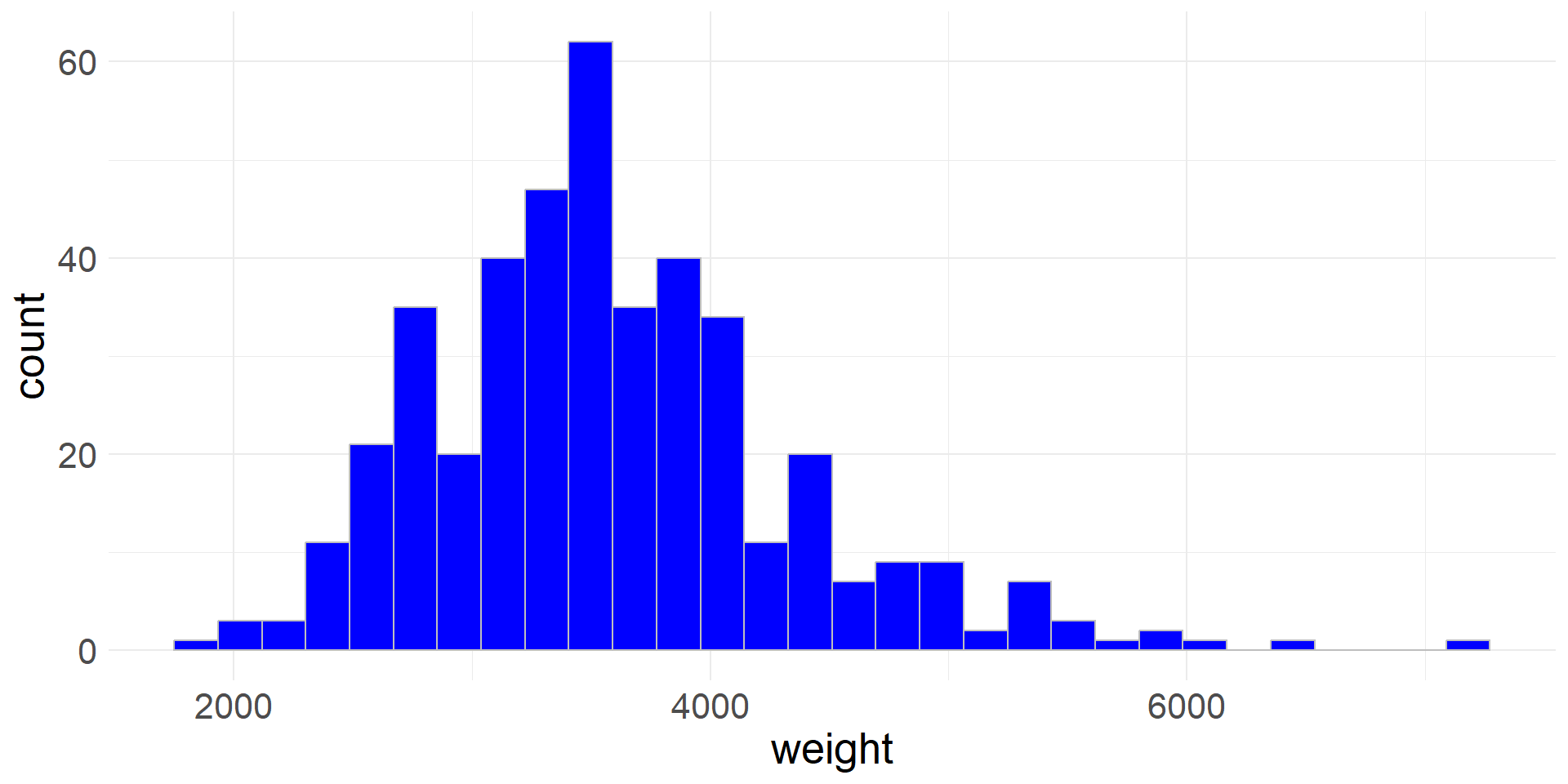
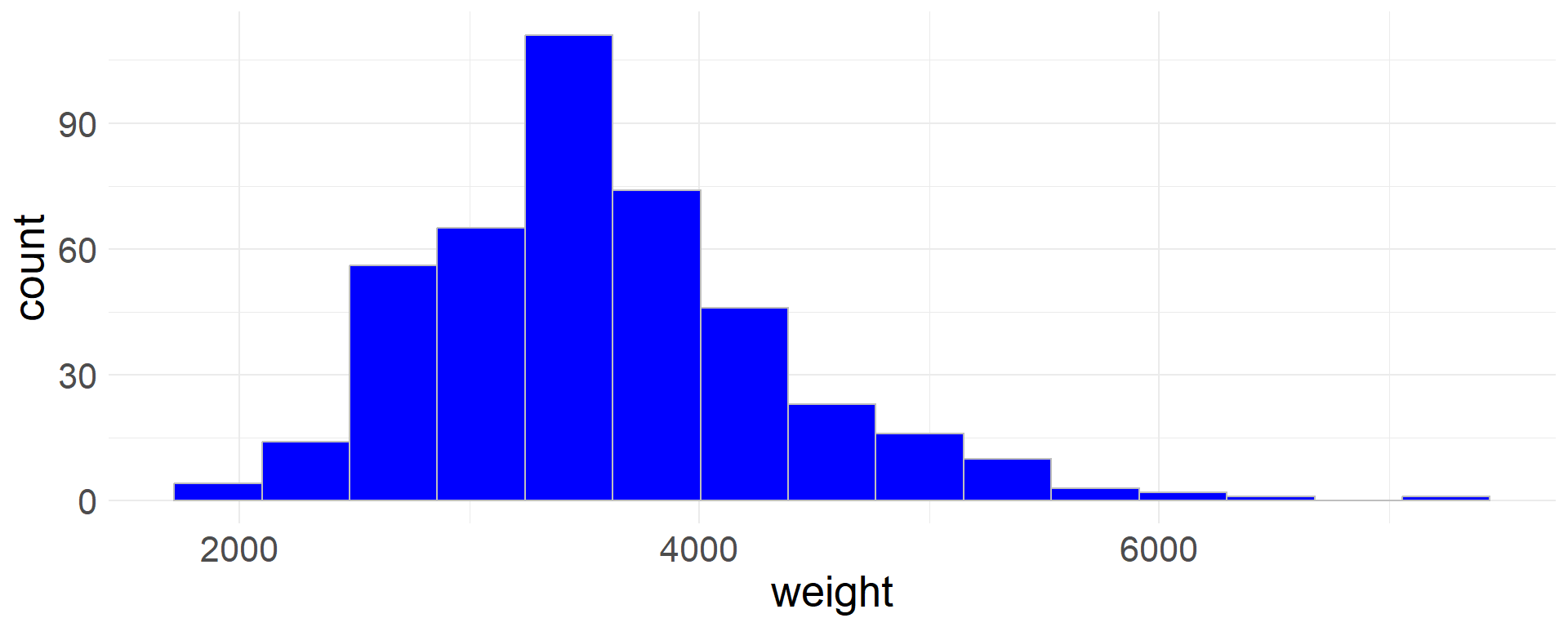
- Rather than using the default values, we can also specify the number of bins (
bins) or the bin width (binwidth) - Here we specify the number of bins
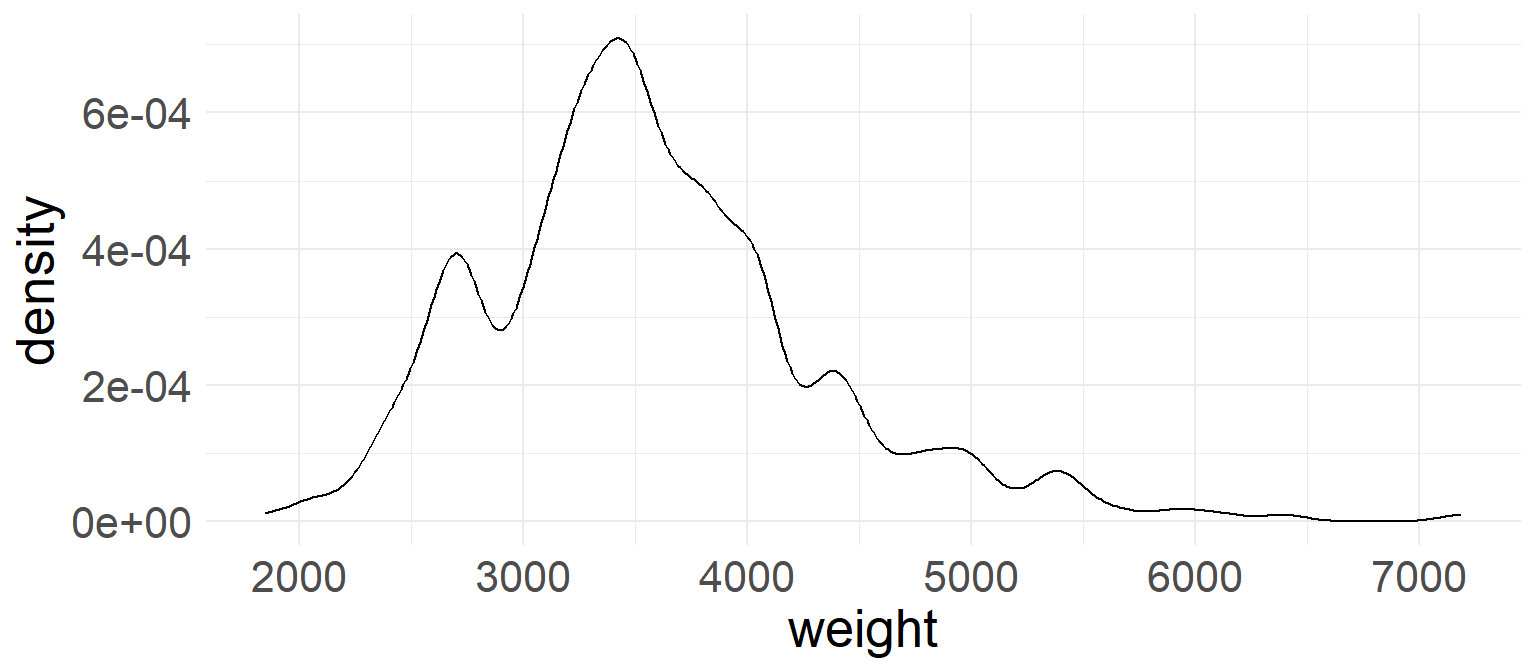
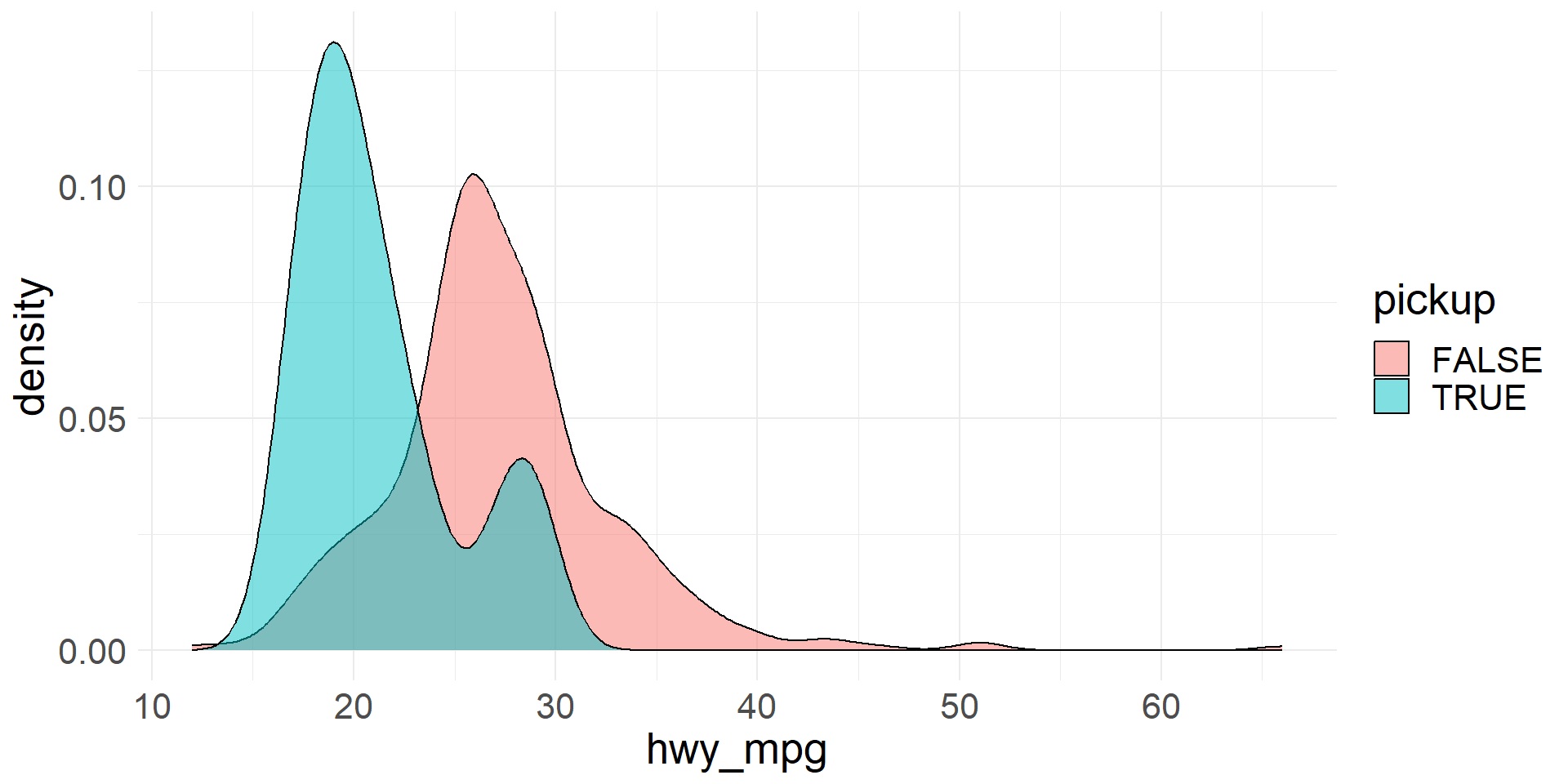
Density plot
In a density plot the shape of the distribution is outlined by smooth line
Let’s create a density plot of vehicle weights (The bandwith (
bw) controls the degree of smoothing)