Inference with Mathematical Models
Chapter 13
Math 215
Math 215

Histogram of 1,000 differences in randomized proportions (null distribution), showing observed difference as dashed vertical line.
Normal Distributions
- \(N(\mu, \sigma)\) denotes a normal distribution with mean \(\mu\) and standard deviation \(\sigma\)
- Normal distributions are bell-shaped and symmetric
- The center of the distribution is determined by mean \(\mu\)
- The width is determined by the standard deviation \(\sigma\)
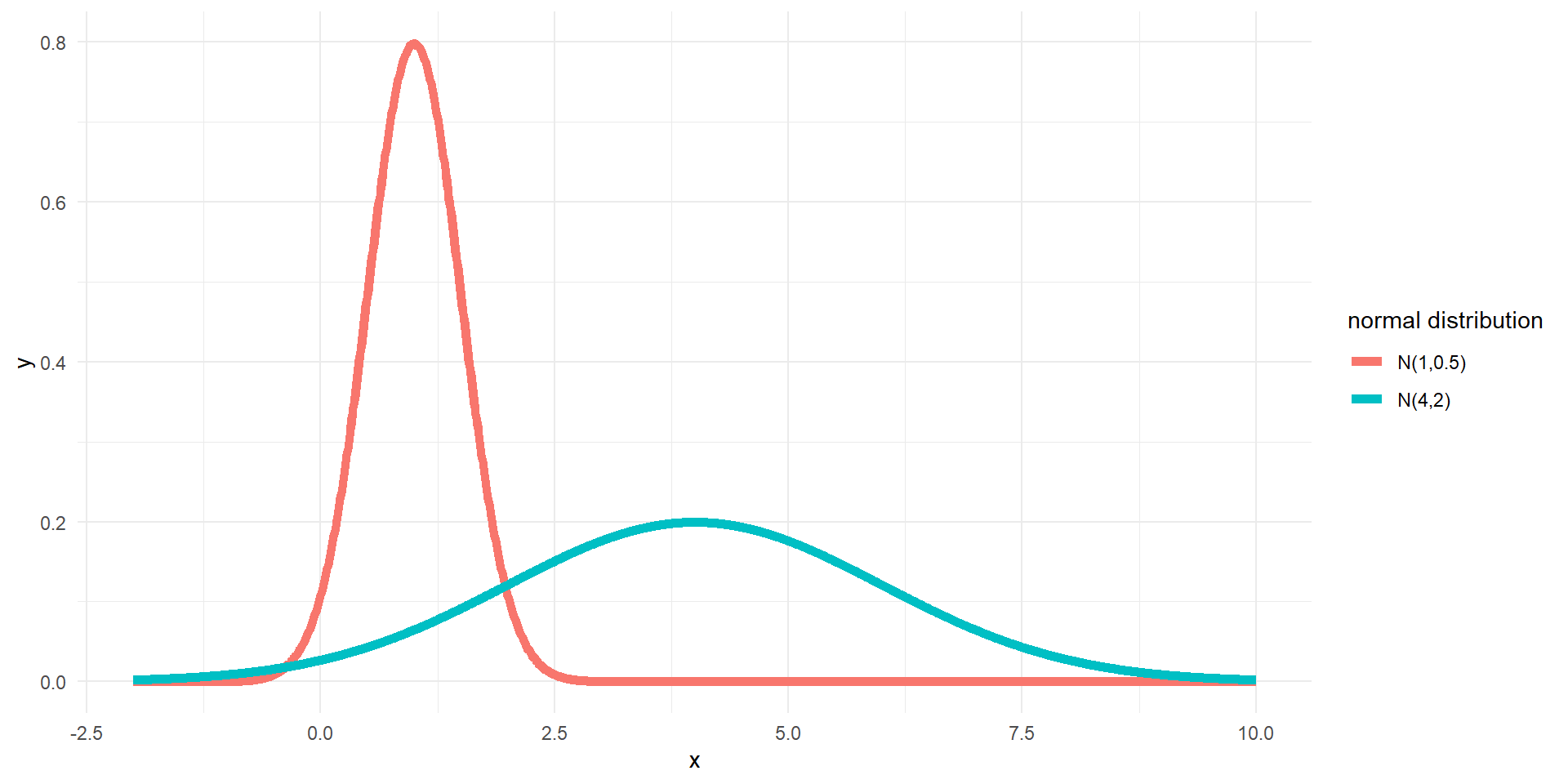
Two examples of normal distributions with different means and standard deviations
How good is the approximation?
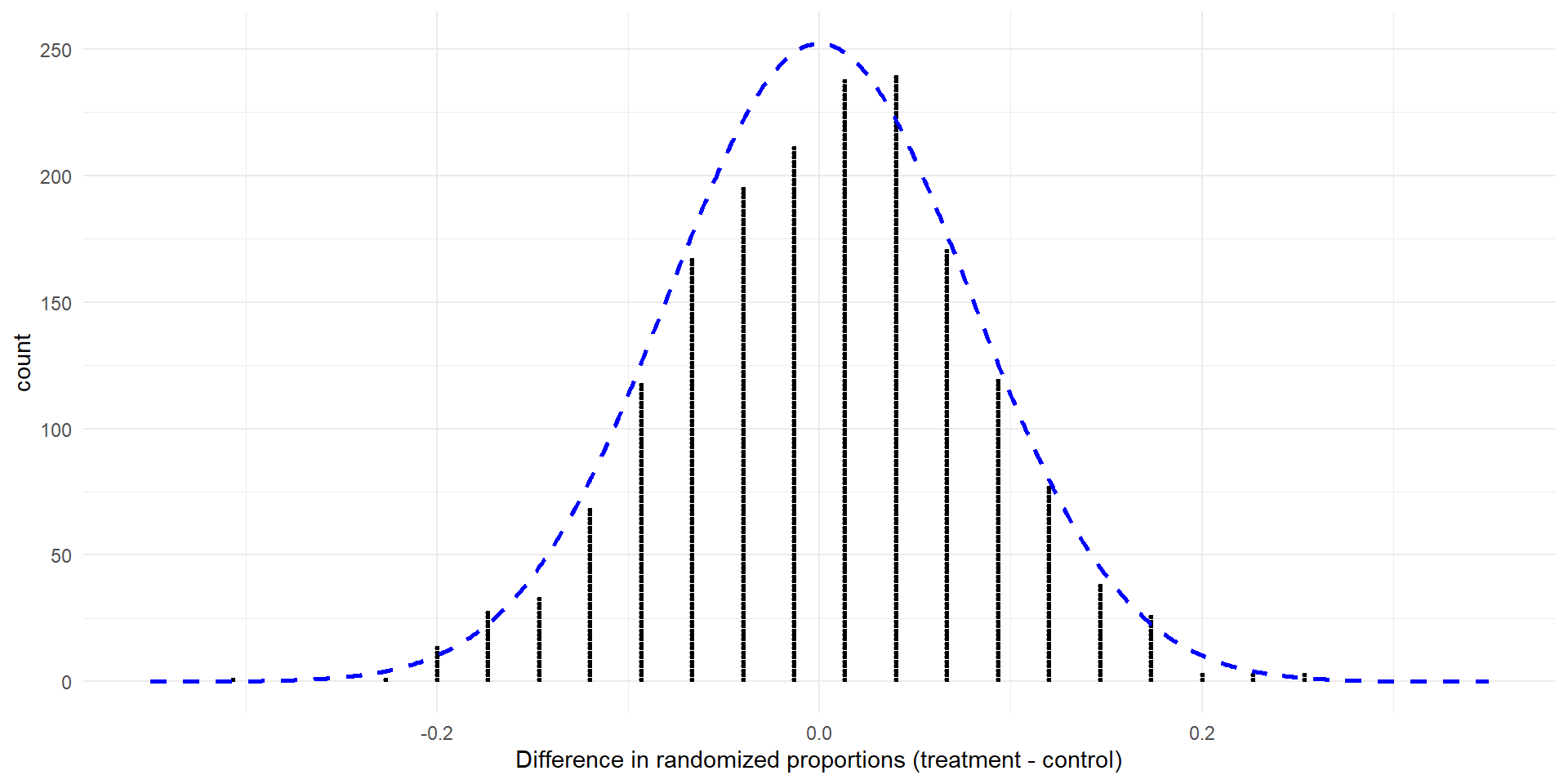
Null distribution from randomly permuted data and normal approximation
We can find the p-value by calculating the area under the curve in the same region
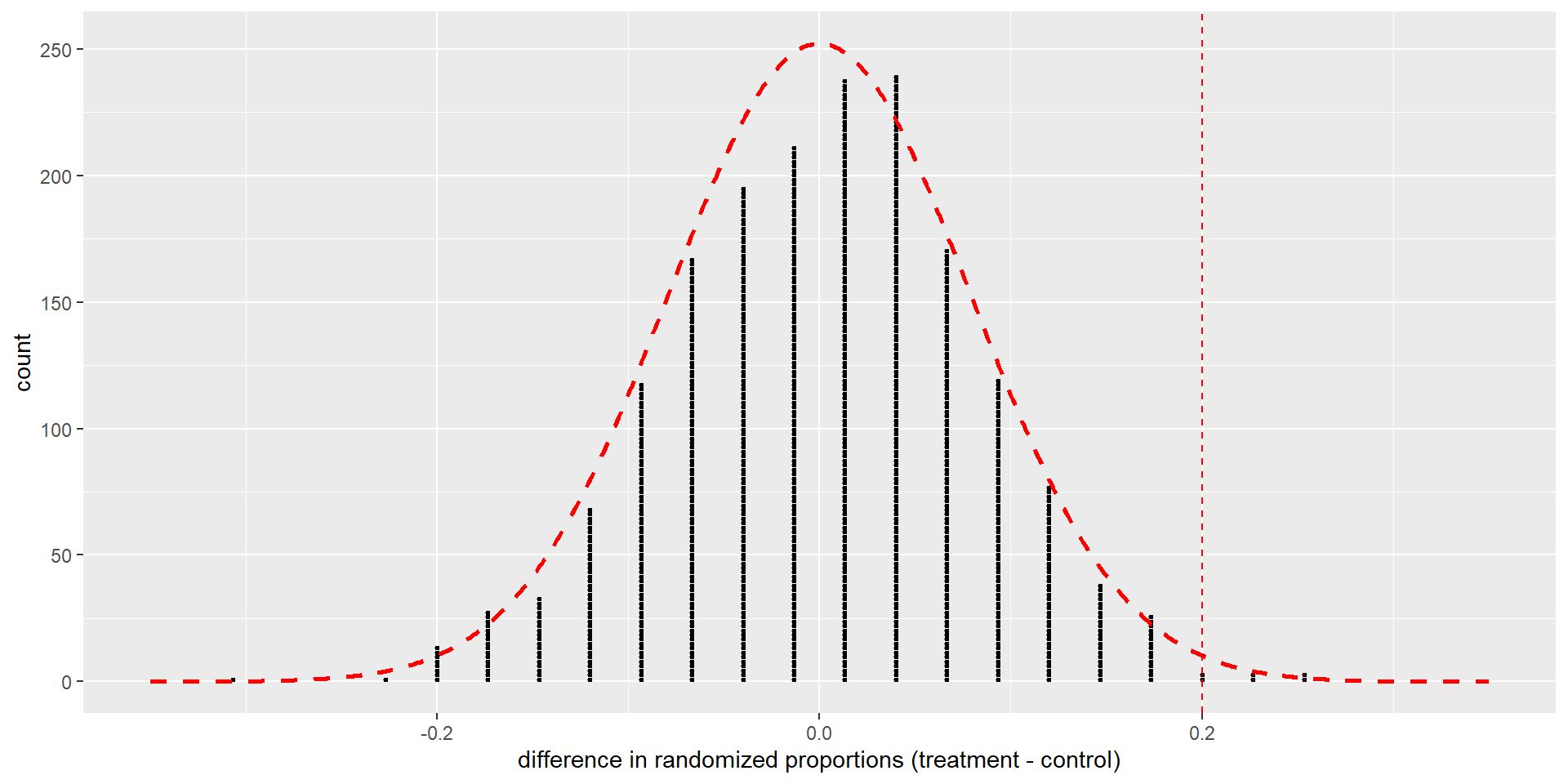
The p-value represents the area under the normal distribution
Computing Probabilities Using a Normal Distribution
For a probability density function, the area under the curve (integral) is a probability
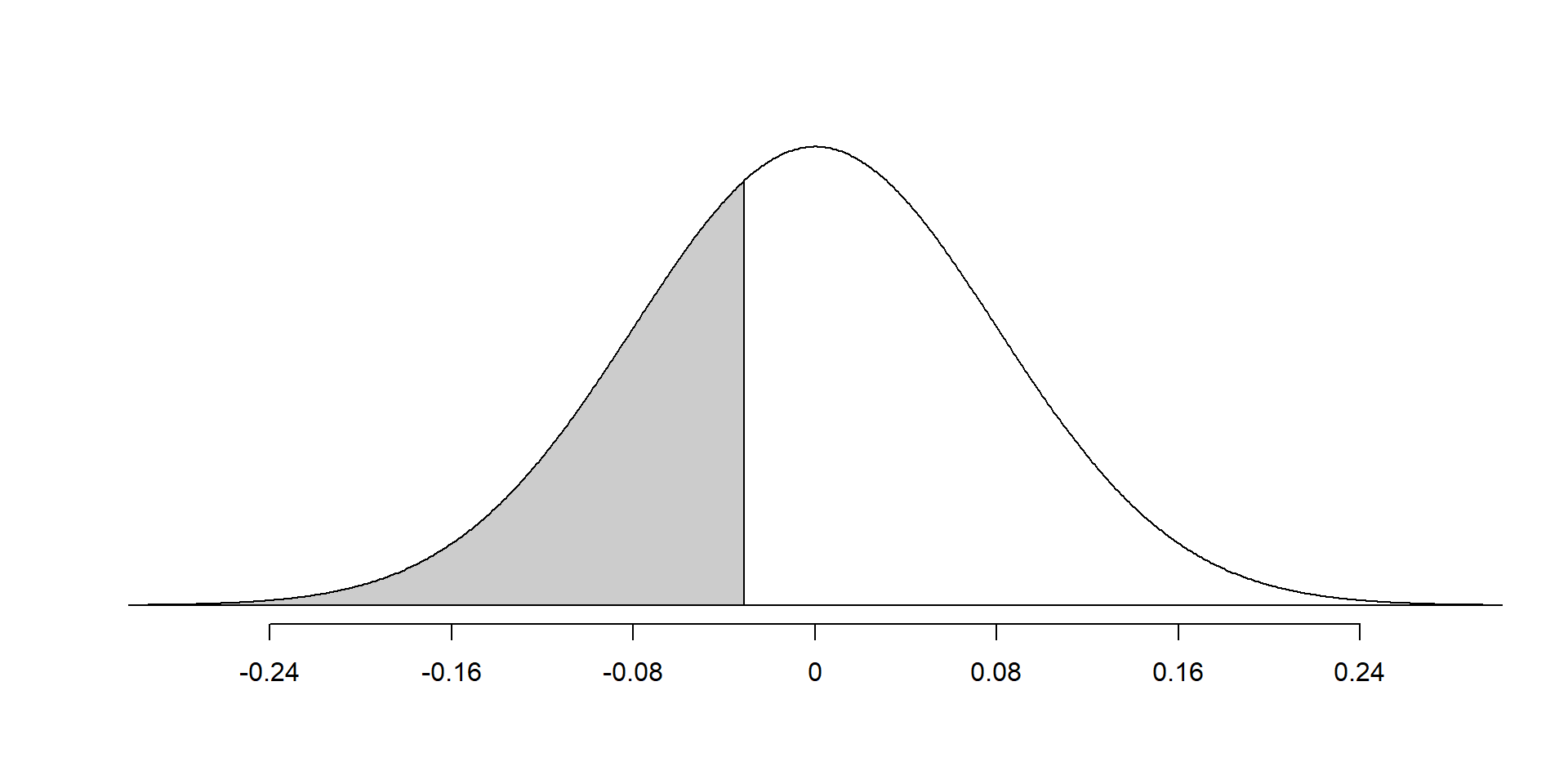
Example: Shaded area is probability that value is less than -0.03
The probability that the value is less than -0.03 is
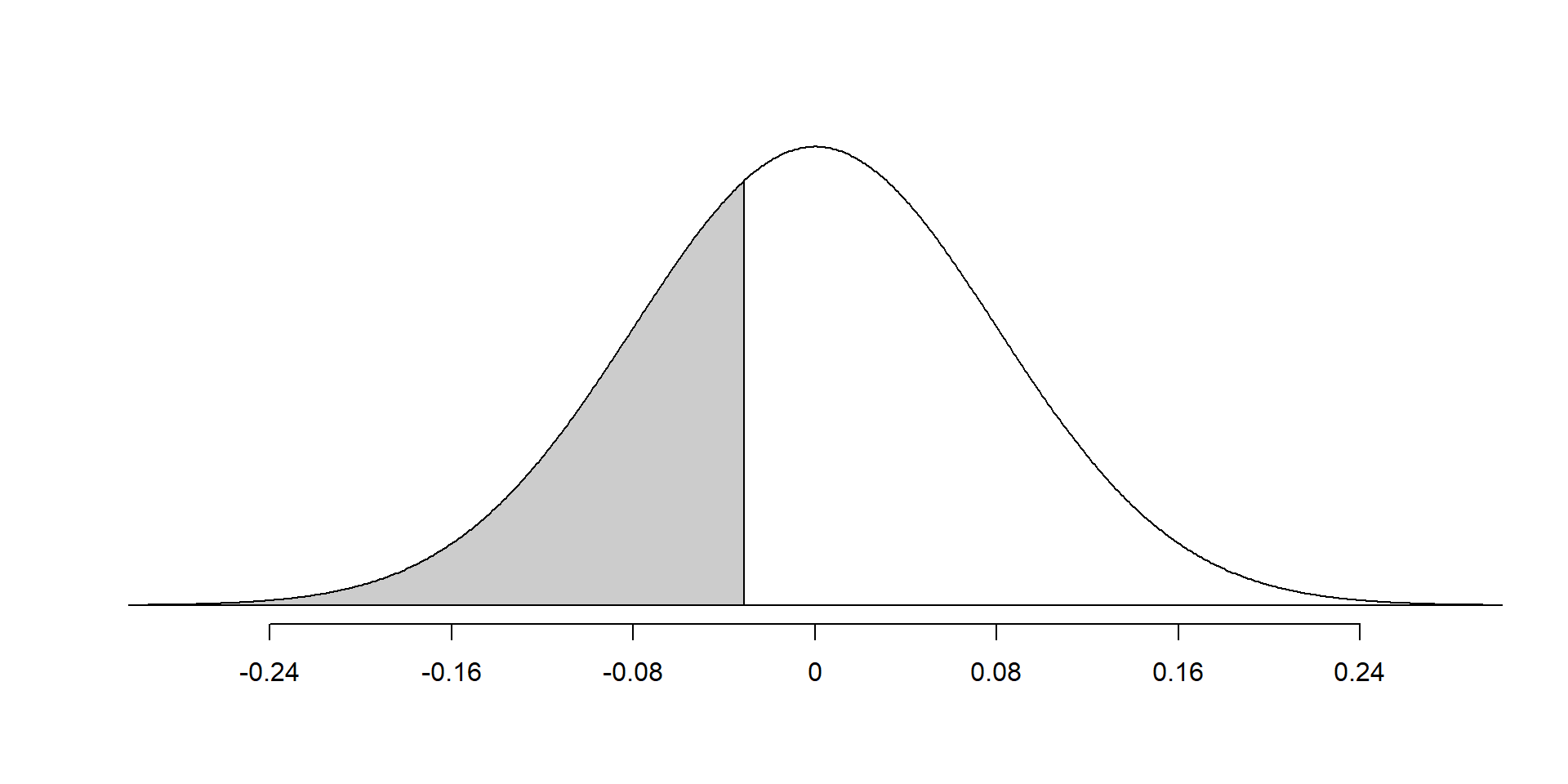
The probability that the value is at least -0.03 is
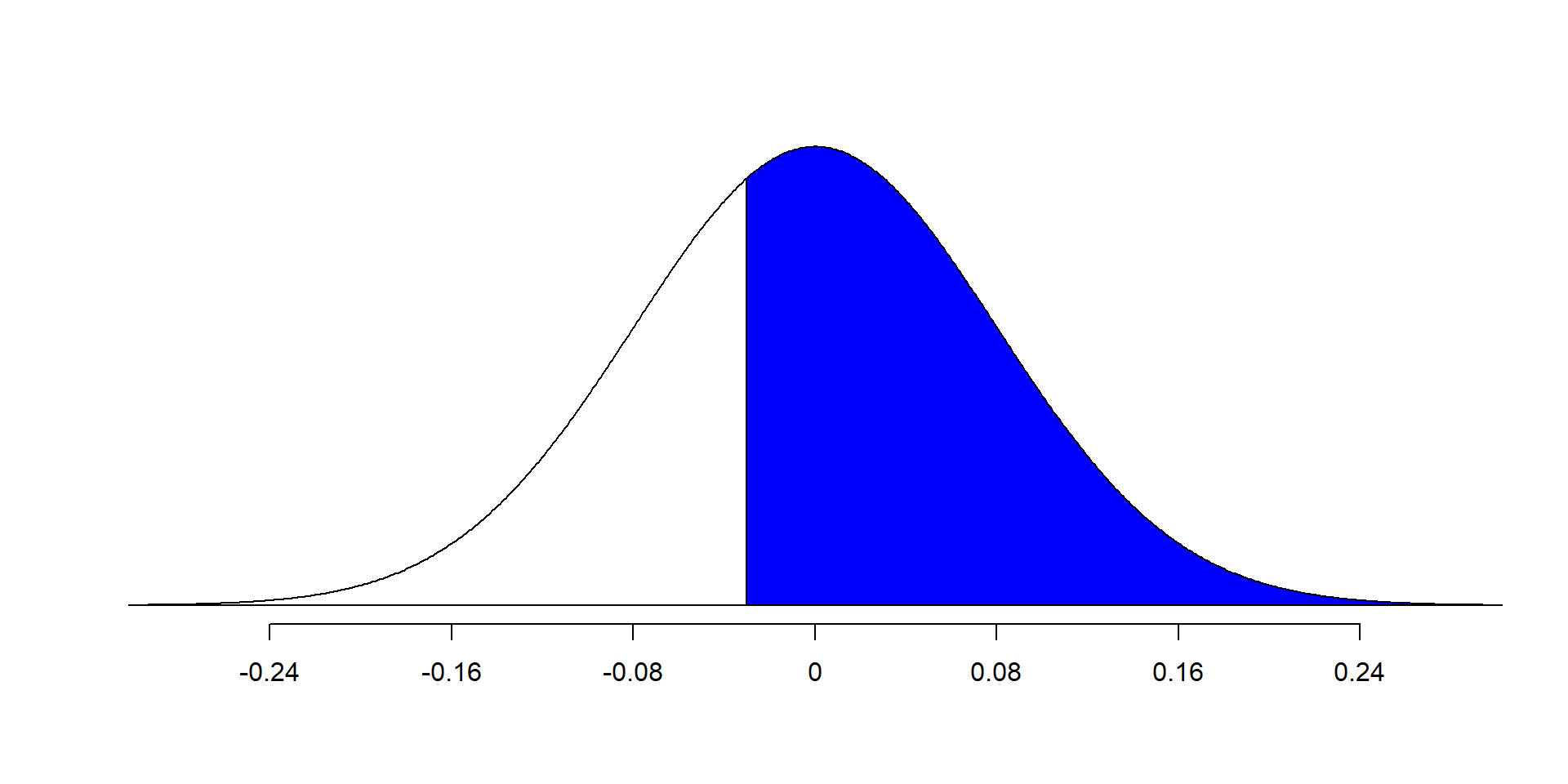
Computing a p-value from a Normal Distribution
We can compute a p-value using the normal approximation of the null distribution
The p-value is
- If the \(X\) is distributed according to \(N(\mu,\sigma)\), then \(Z\) will be distributed according to \(N(0,1)\)
- \(N(0,1)\) is called the standard normal distribution
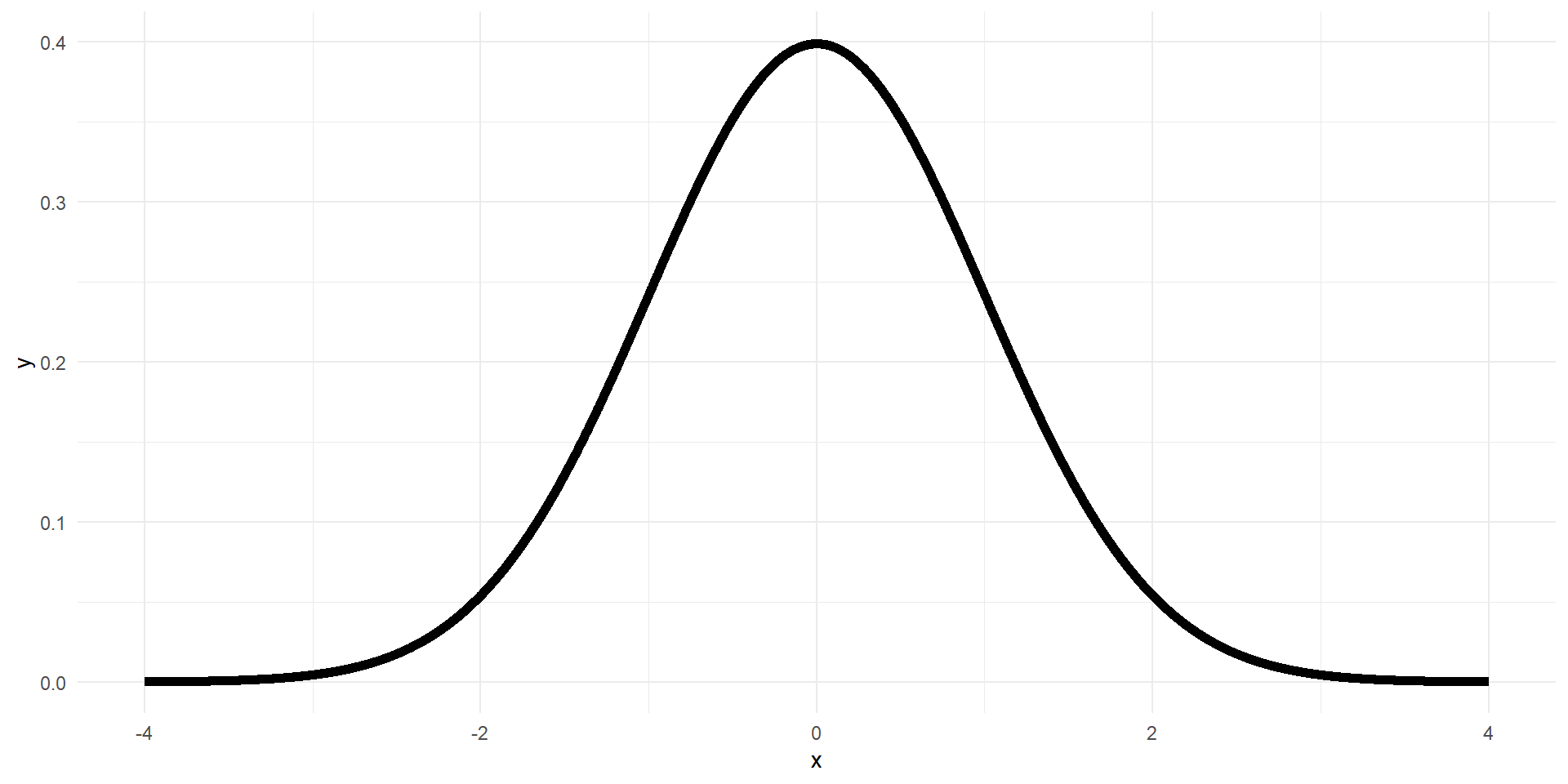
Standard normal distribution
68-95-99.7 rule
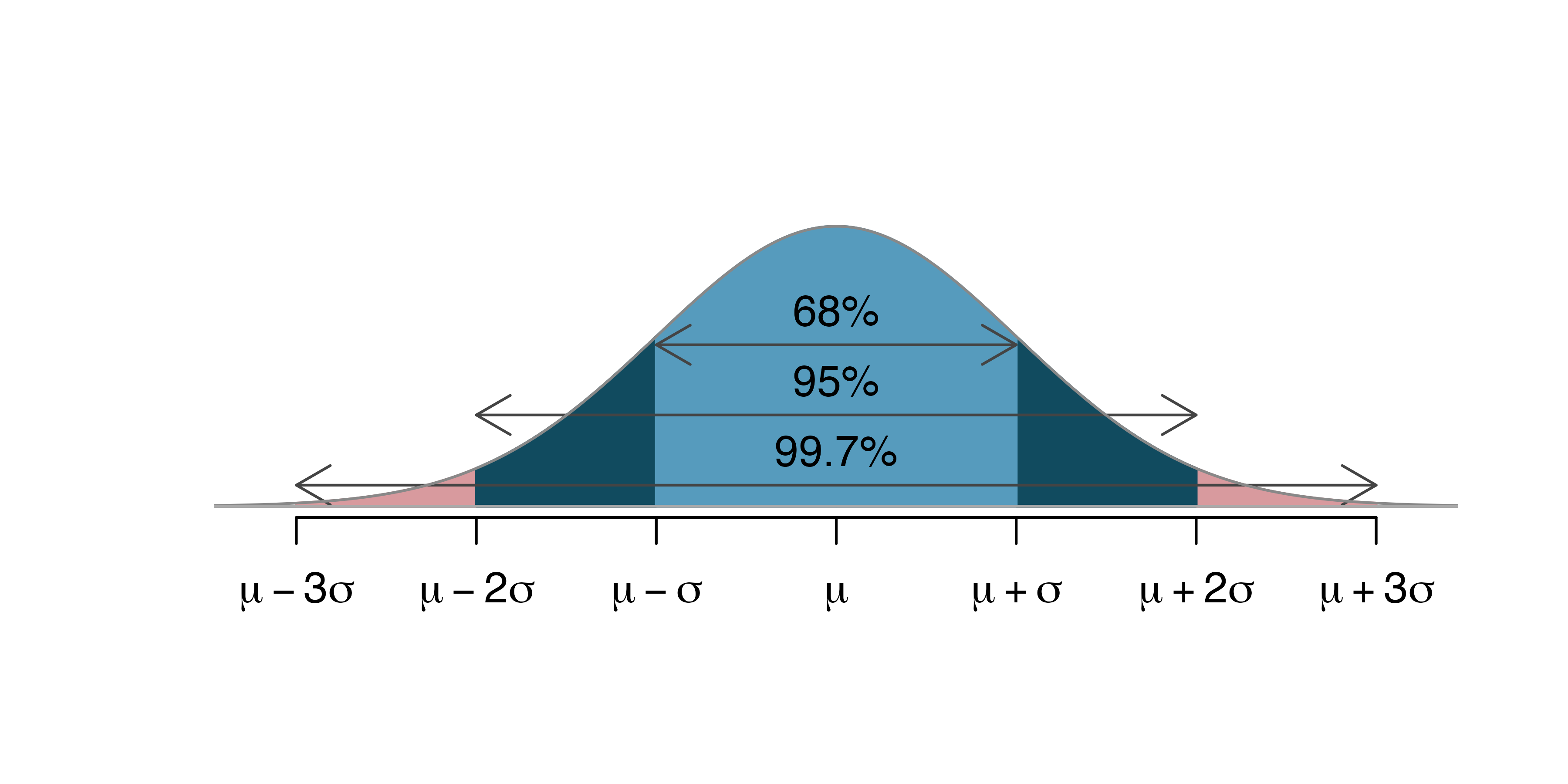
From IMS1 Figure 13.8.
- About 68% of normally distributed data fall within 1 SD of the mean
- About 95% fall within 2 SD (1.96 to be more precise)
- About 99.7% fall within 3 SD
Meaning of the level of confidence
Figure below shows 25 confidence intervals for a proportion that were constructed from 25 different datasets that all came from the same population where the true proportion was p=0.3.
However, 1 of these 25 confidence intervals happened not to include the true value
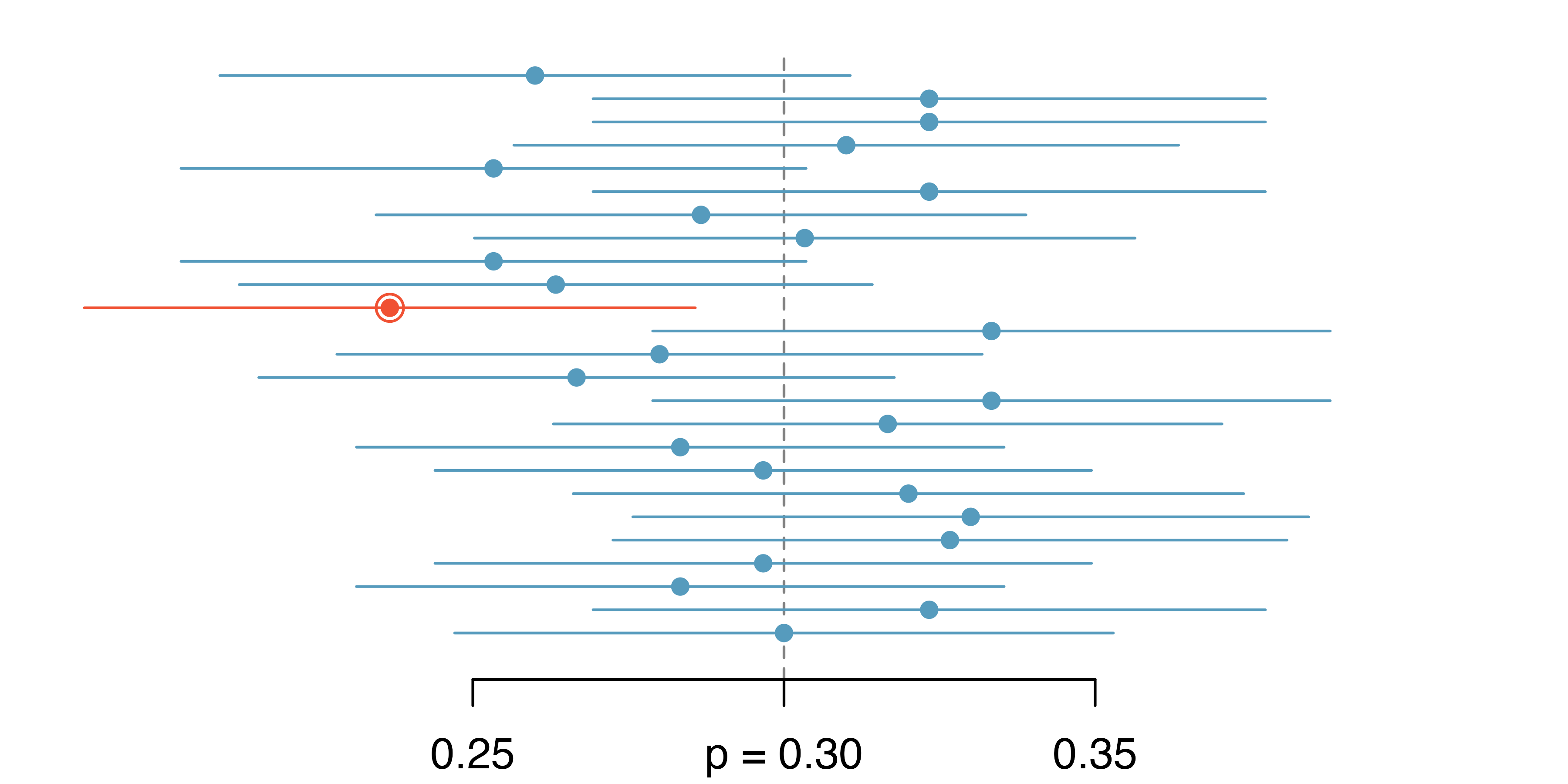
From IMS1 Figure 13.11.