Linear Regression: Multiple Predictors
IMS1 Ch. 8
Math 215
Maria Kart
- You have finally decided to sell your collection of Mario Kart games for the Nintendo Wii
- How do different auction and game characteristics affect the price of the game on Ebay?

Box art from Mario Kart.
EDA
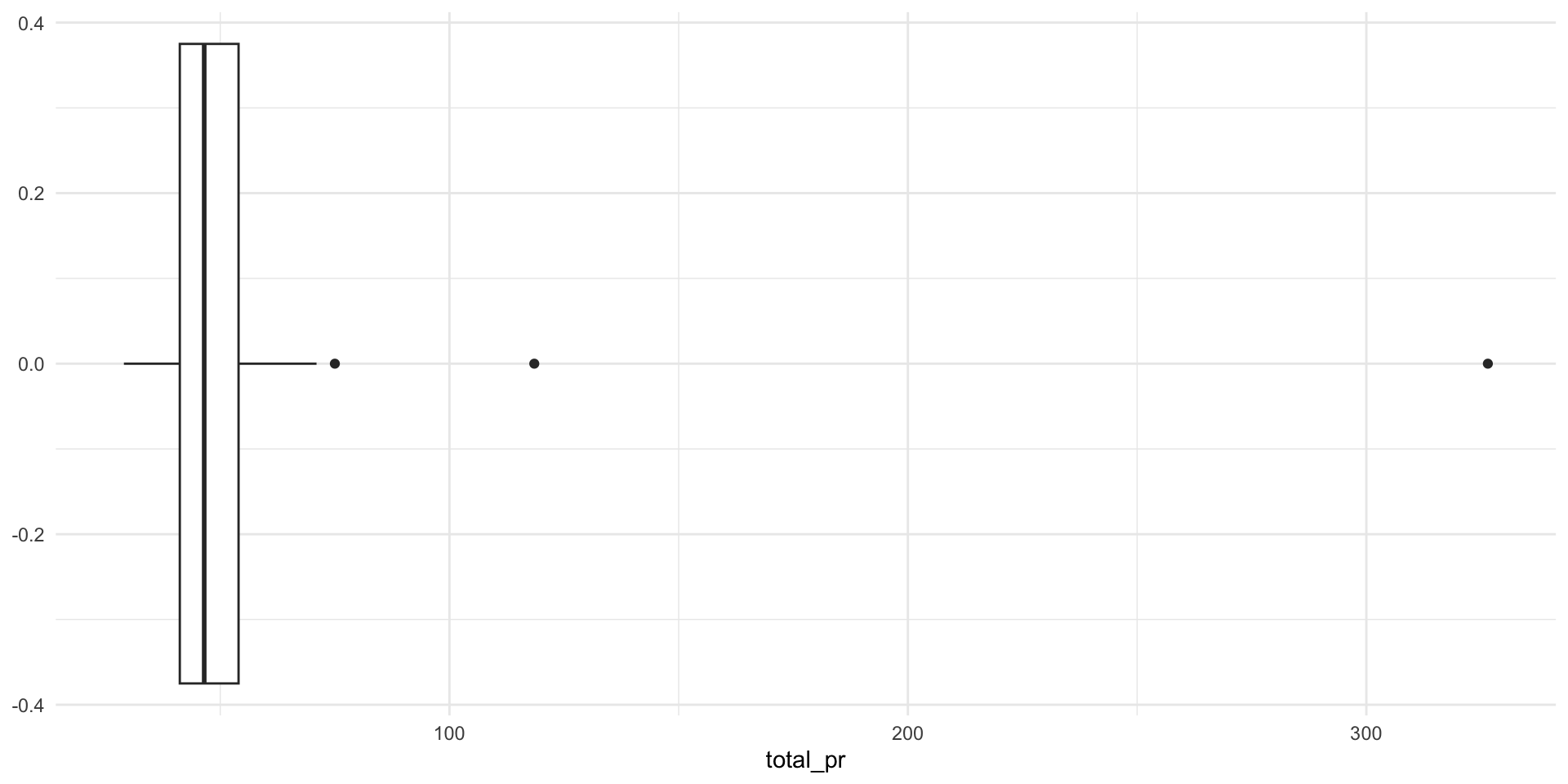
- The two highest prices include more than just the game and wheels. Remove these points from the data.
# A tibble: 3 × 2
total_pr title
<dbl> <fct>
1 327. "Nintedo Wii Console Bundle Guitar Hero 5 Mario Kart "
2 118. "10 Nintendo Wii Games - MarioKart Wii, SpiderMan 3, etc"
3 75 "NEW MARIO KART WITH WII WHEEL+2 GT PRO WHITE WII WHEEL" 
Single Predictor (total_pr ~ wheels)
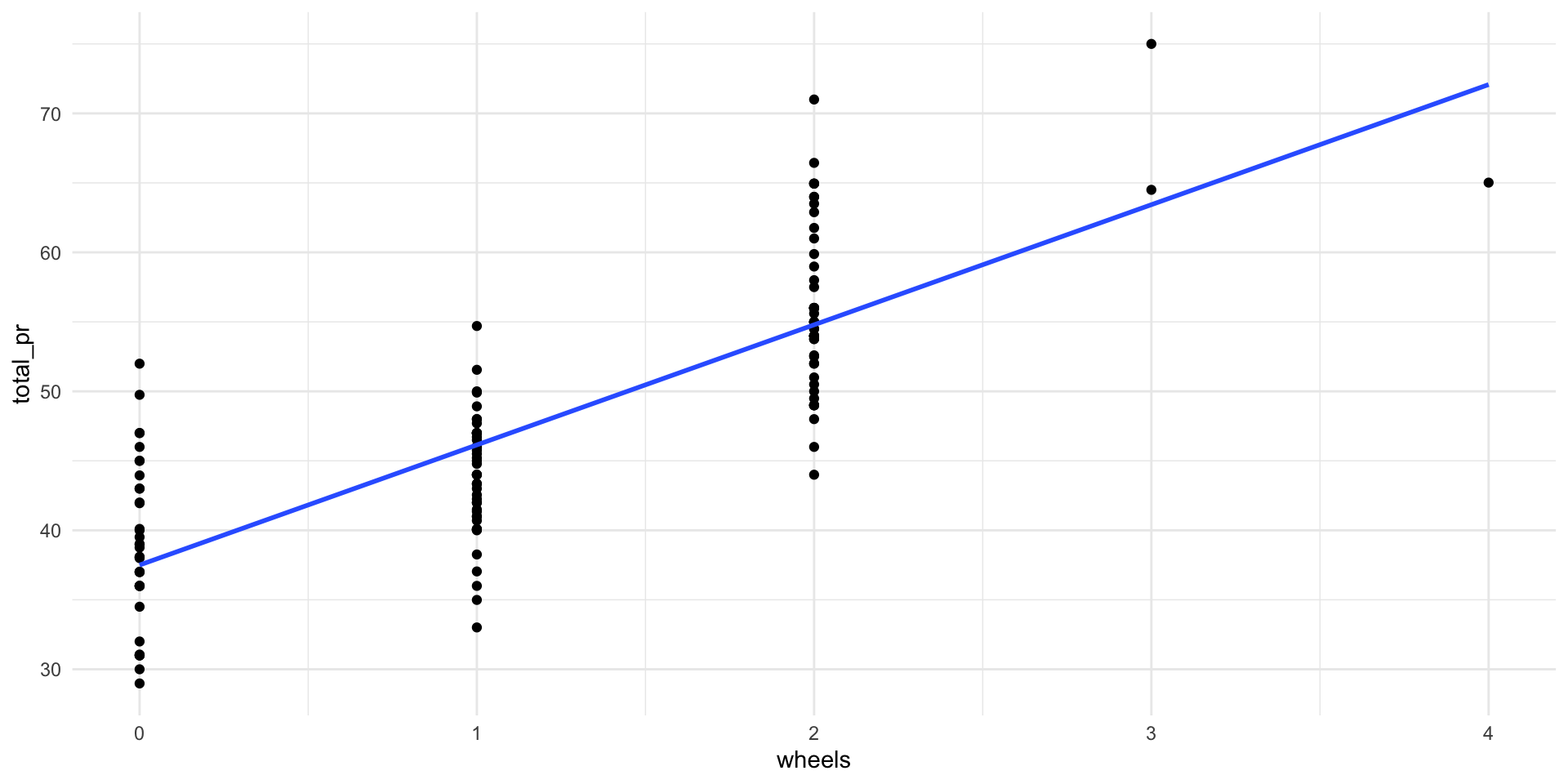
\[\widehat{total\_pr} = 37.5 + 8.64\times wheels\]
Coefficient of determination: \(R^2=0.642\)
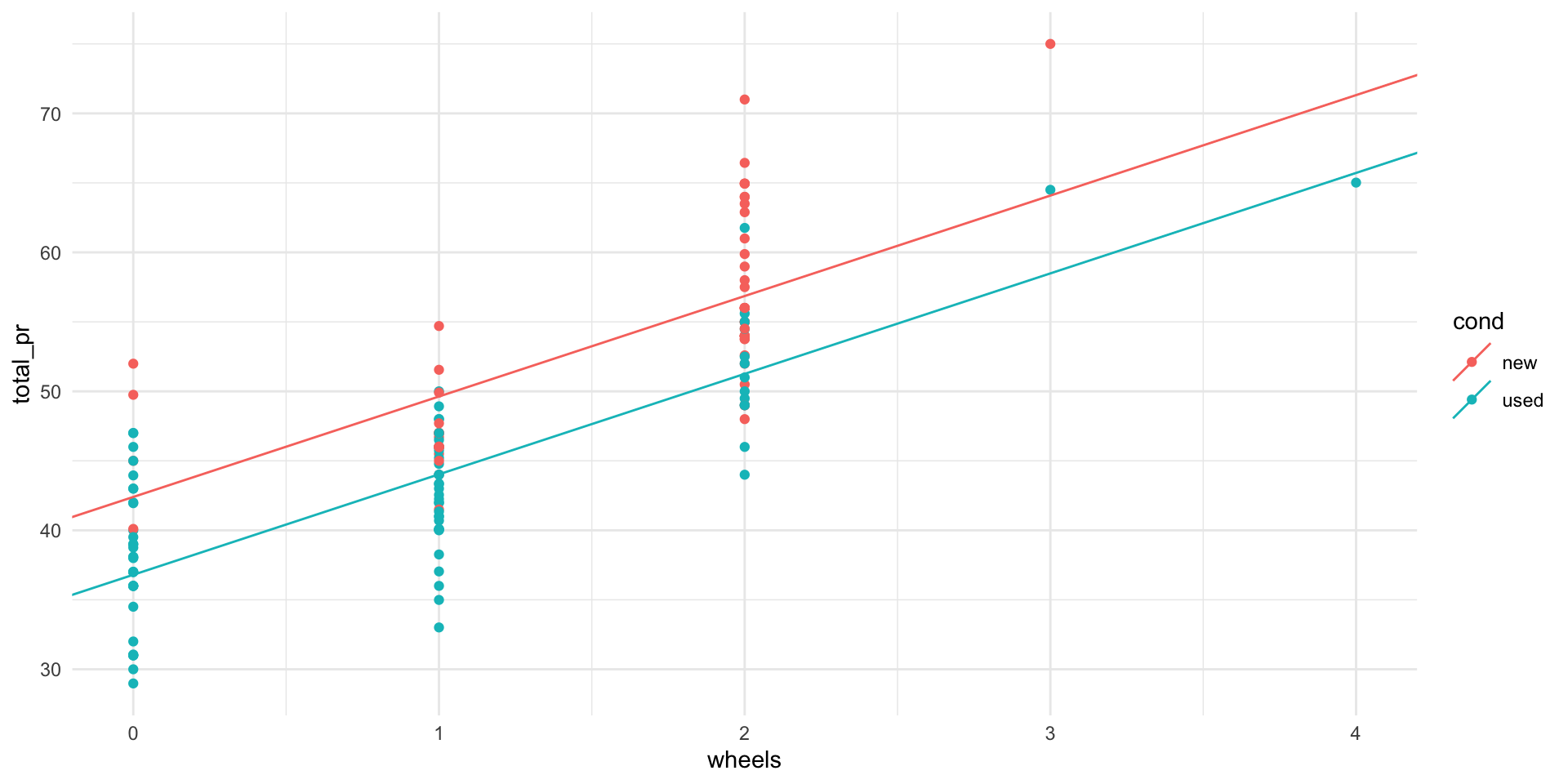
Scatter plot of total price vs. number of steering wheels colored by condition, along with parallel slopes model.
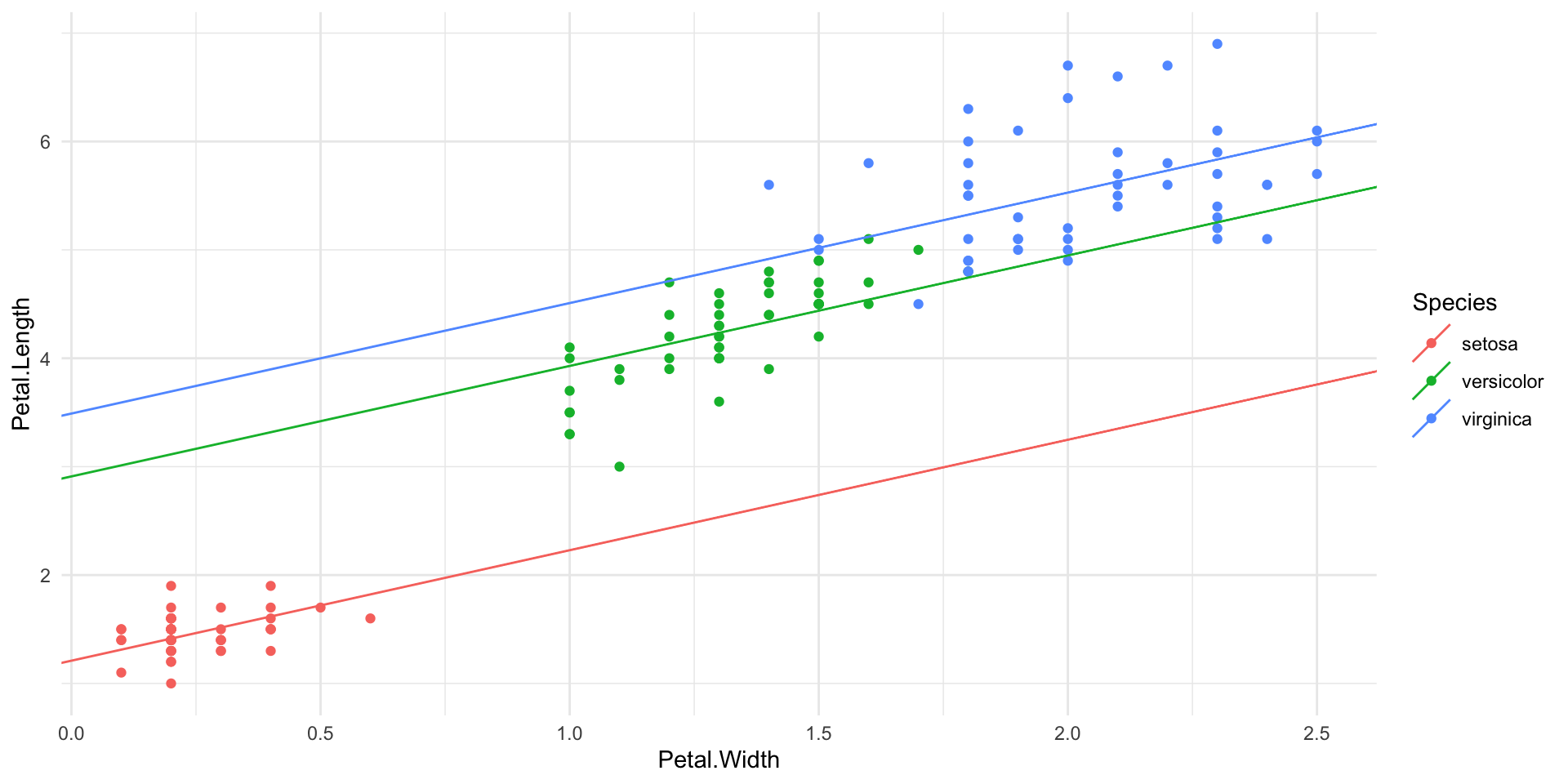
Scatter plot of petal length vs. petal width colored by species, along with parallel slopes model.