Linear Regression, Single Predictor
IMS1 Ch. 7
Math 215
Body Measurements
bdims1 body measurement dataset.507 physically active individuals (247 men, 260 women)
age, weight (wgt), height (hgt),sex, 21 body girth variables (e.g., hip girth)
Weight vs. Height
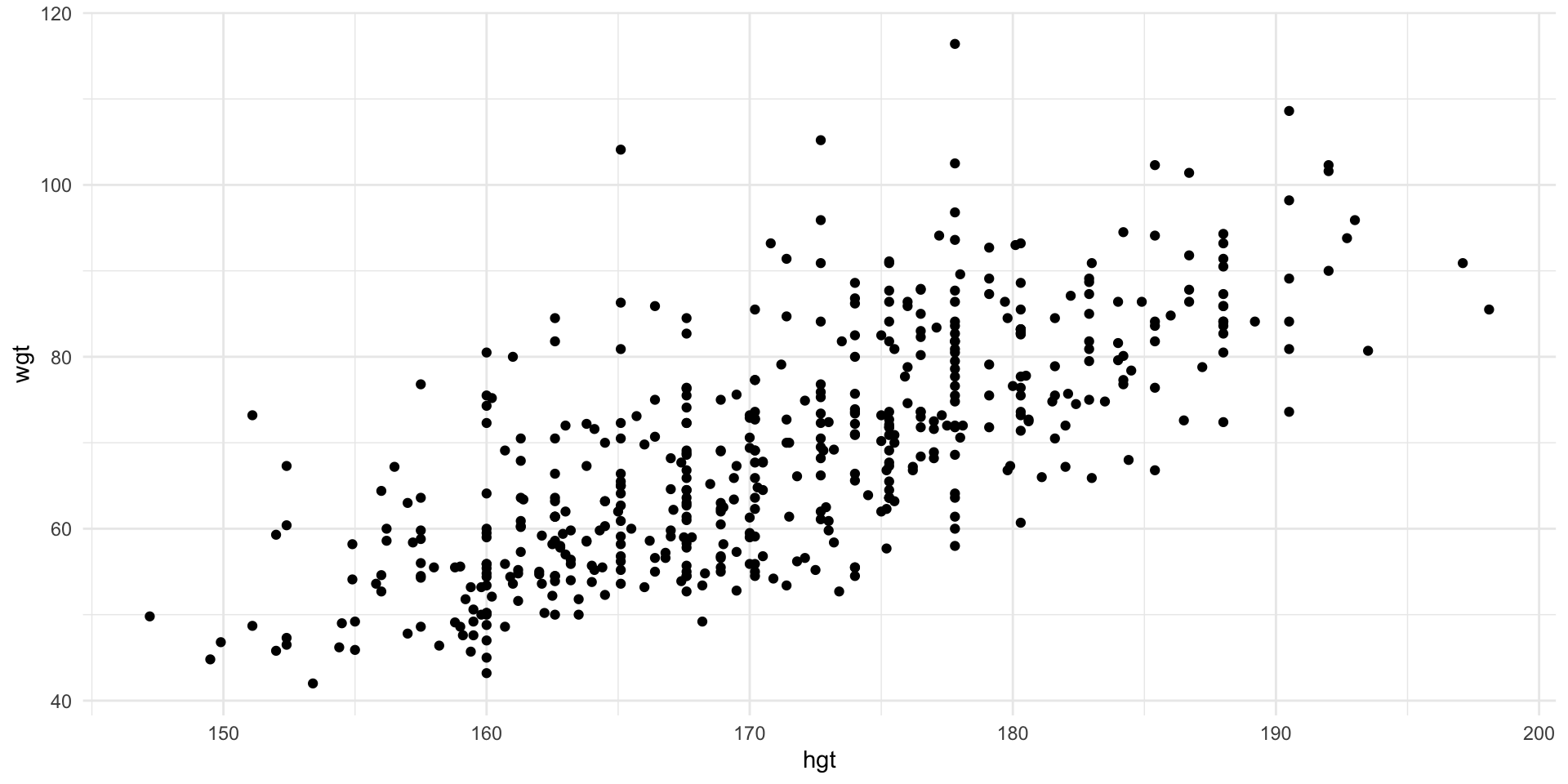
Scatter plot of weight vs. height.
It appears that the data fall roughly along a line.
Linear Model
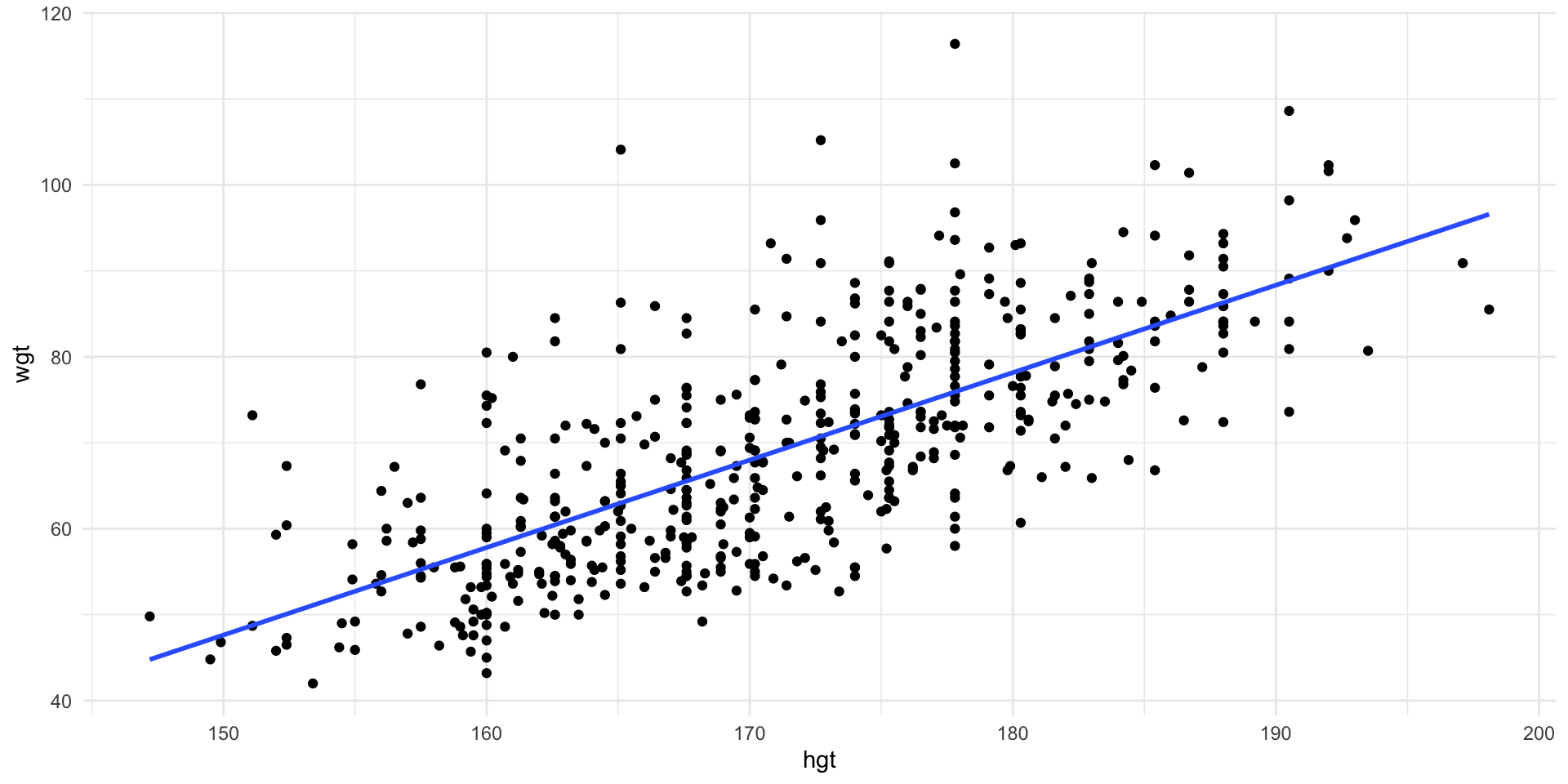
Scatter plot of weight vs. height with line of best fit.
We can add a line of best fit to the scatter plot.
- Equation for line: \[y = b_0 + b_1 x\]
- \(b_0\) and \(b_1\) are coefficients
- \(b_0\) = intercept
- \(b_1\) = slope
- \(b_0\) and \(b_1\) are statistics (fit using sample)
- \(\beta_0\) and \(\beta_1\) are the corresponding parameters
- The fitted values are \(b_0=-105.0\), \(b_1=1.018\)
Variable Roles
wgt= outcome/response (dependent variable, \(y\))hgt= predictor (independent variable, \(x\))- We use a hat to indicate an estimate or prediction \[\widehat{wgt} = -105.0 + 1.018 \times hgt\]
Using a Model to Make Predictions
- Use the model to predict the weight of a person with a given height
- The predicted weight of a 170 cm tall individual is \[\begin{array}{rcl}\widehat{wgt} &=& -105.0 + 1.018 \times hgt\\ &=& -105.0 + 1.018 \times 170 \\ &=& 68.06\, kg\end{array}\]
Correlation
- The correlation coefficient describes strength and direction of a linear relationship
- Denoted \(r\) for a sample, \(\rho\) for a population
- \(-1\leq r\leq1\)
- Direction of linear relationship
- \(r>0\) indicates a positive association
- \(r<0\) indicates a negative association.
- Strength of linear relationship
- Values close to 0 indicate a weak linear association
- Values close to -1 or 1 indicate a strong linear association
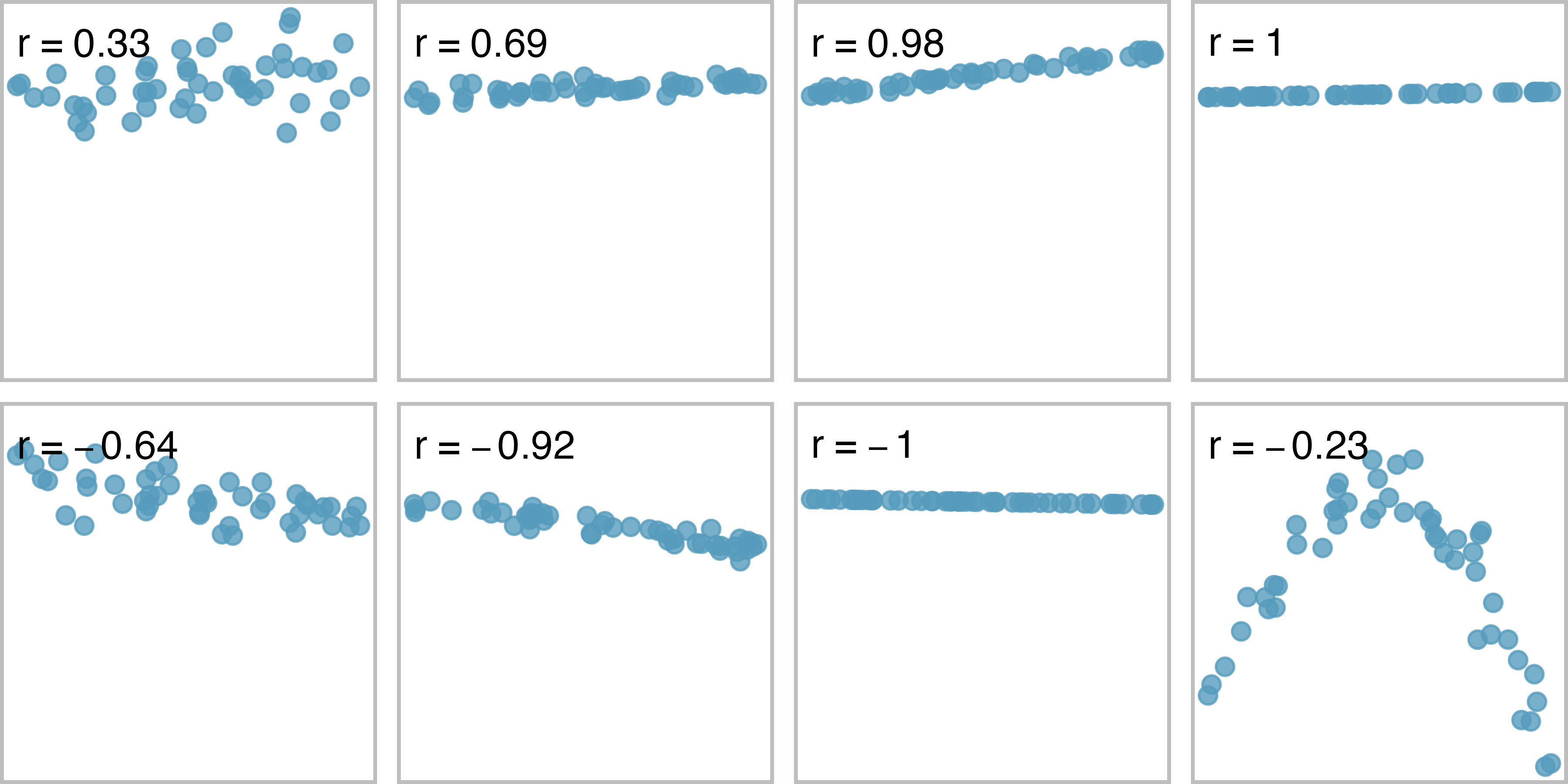
Some scatter plots and their correlations. IMS 1 Figure 7.11.
- Let \((x_i,y_i)\) be the \(i\)th observation of the numeric variables \(x\) and \(y\)
- Then \(r\) is \[r=\frac{1}{n-1}\sum_{i=1}^n\frac{x_i-\bar{x}}{s_x}\cdot\frac{y_i-\bar{y}}{s_y}\]
- Here \(\bar{x}\) and \(\bar{y}\) are the sample means, and \(s_x\) and \(s_y\) are the sample standard deviations of the \(x\) and \(y\)
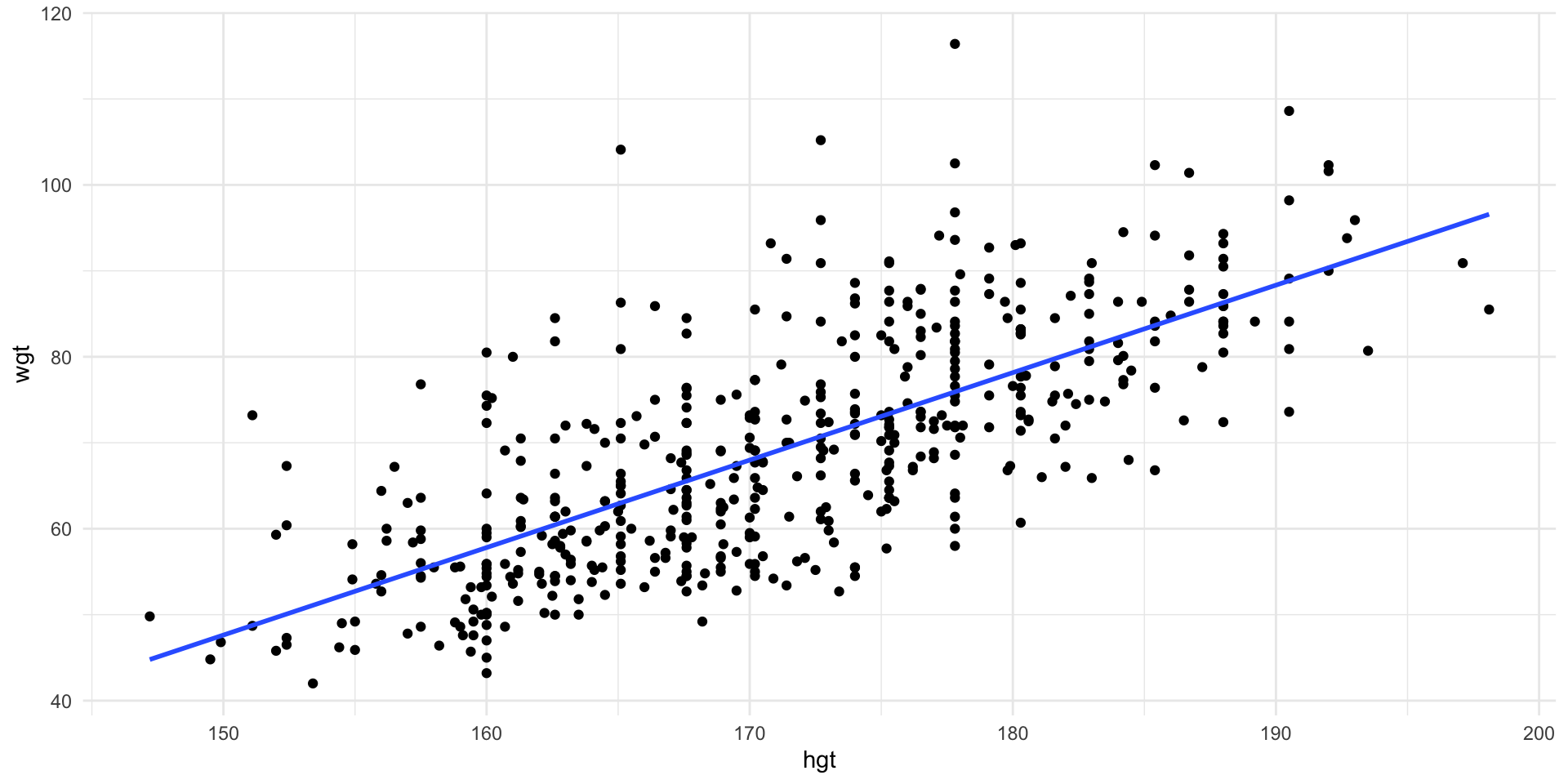
Scatter plot of weight vs. height with line of best fit.
Correlation between height and weight: \(r=0.717\)
Interpretation of coefficients
\[\widehat{wgt} = -105.0 + 1.018 \times hgt\]
- Slope: for each additional centimeter of height, we expect weight to increase by 1.018 kg
- Intercept: we would predict a 0 cm tall individual to weigh -105.0 kg
- In many cases, this intercept interpretation is not useful
- Better to think of intercept as positioning line vertically so it passes through the data cloud
Extrapolation
- Predicting weight for individual with height outside of the range of the observed data is an example of extrapolation
- We should not expect the model to apply outside of this range
- Extrapolation can lead to nonsensical predictions (0 cm tall individuals with negative weight) or inaccurate ones
Least Squares Regression
- How is the best fit line determined?
- Slope and intercept chosen to minimize the error between the observed and predicted response
Plot highlighting three residuals. IMS1 Figure 7.8.
The residual (error) for the \(i\)th observation \((x_i,y_i)\) is \[e_i = y_i - \hat{y}_i\]
Least Squares Line
The least squares regression line minimizes the sum of the squared residuals, \[e_1^2+e_2^2+\cdots+e_n^2\]
Properties of least squares line
- The line passes through the point \((\bar{x},\bar{y})\)
- The slope is \(b_1=\frac{s_y}{s_x}r\)
We can use these properties to compute the slope and intercept if we know the means, SDs, and correlation
Calculating Coefficients
- Let’s compute the coefficients for the weight vs. height example
- First we need to compute the summary statistics
Calculating the Slope
We use \(b_1=\frac{s_y}{s_x}r\) to calculate the slope
Calculating the Intercept
- If \((x_0,y_0)\) is a point on a line, then the line can be expressed as \[y-y_0 = b_1(x-x_0)\]
- This is called the point-slope form for the line
- We calculate the intercept using the property that \((\bar{x},\bar{y})\) is on the line
Using the lm function
Typically we will use the lm function (for linear model) to compute the coefficients of the least squares line
Categorical predictor with 2 levels
- If the independent variable is categorical can we still use linear regression?
- We will consider categorical predictors with 2 levels
- Can have more than 2 (chapter 8)
- Linear model only makes sense if \(x\) is a number, so we need to recode the levels of the predictor as numbers
- In the
bdimsdata, thesexvariable has two levels: 0 for female, and 1 for male - This variable already has indicator coding
- We can code any variable with two levels this way
- Assign one level as 0 and the other as 1
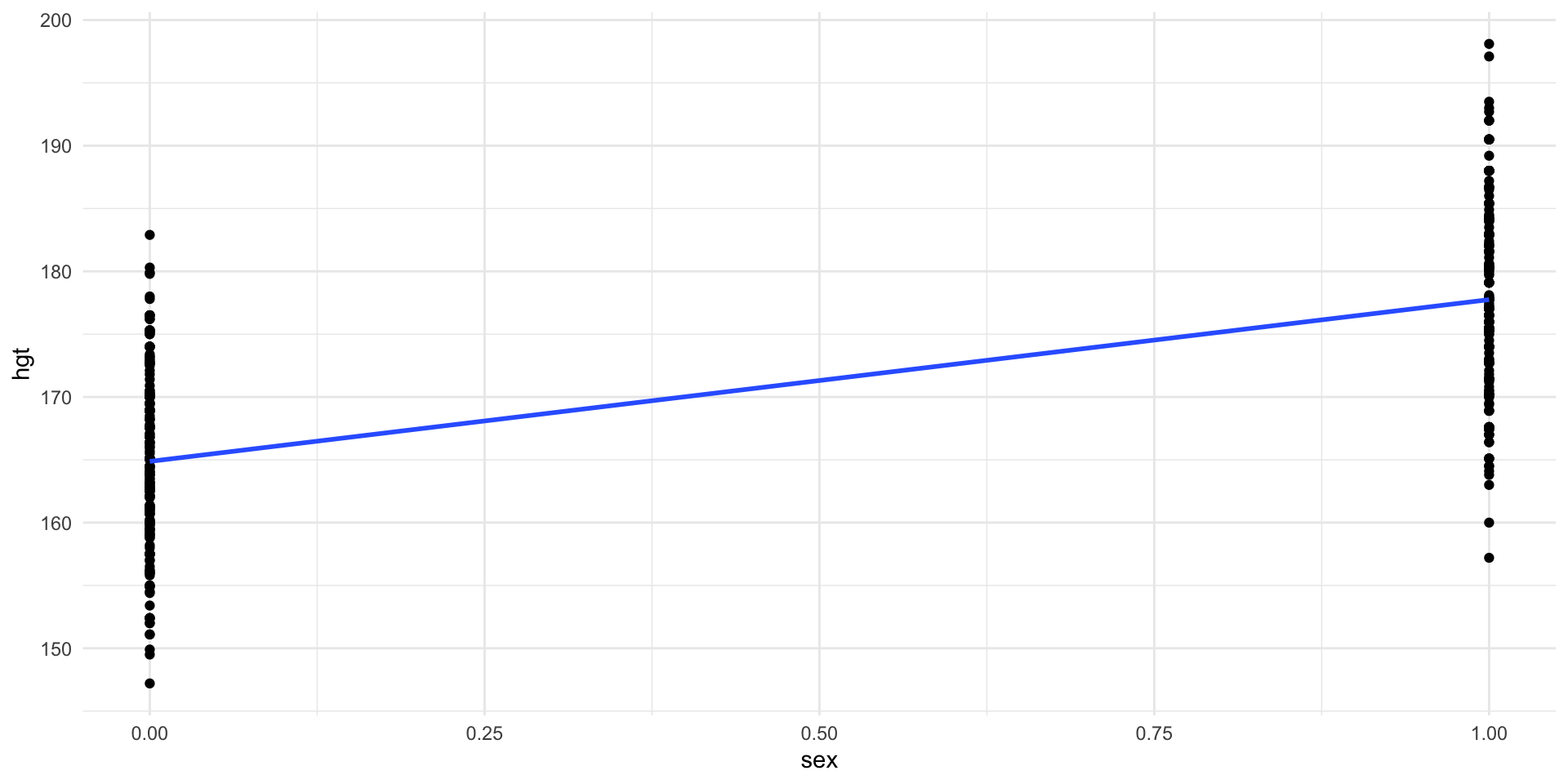
Scatter plot of height vs. sex with least squares regression line.
The equation for the regression line is \[\widehat{hgt}=164.87 + 12.87\times sex\]
\[\widehat{hgt}=164.87 + 12.87\times sex\]
- Females (
sex= 0) \[\widehat{hgt} = 164.87\,cm\] - Males (
sex= 1) \[\widehat{hgt} = 164.87 + 12.87 = 177.7\,cm\] - intercept is predicted female height
- slope adjusts height to get predicted male height
The model predicts that each female will have the mean height for females and each male will have the mean height for males!
Coefficient of determination (\(R^2\))
- The coefficient of determination, also known as R-squared (\(R^2\)) is used to measure how well a model describes the data
- \(R^2\) is the proportion of variation in the outcome/response variable that is explained by the model
- For simple linear regression (one numeric predictor), \(R^2 = r^2\)
- \(R^2\) will always have values between 0 and 1
- Value close to 1: linear model fits the data well (describes nearly 100% of the variability in outcomes)
- Value close to 0 indicates that it does not fit well
Total Sum of Squares
- total sum of squares, denoted SST, describes the total variation in the outcome \[SST = (y_1-\bar{y})^2 + (y_2-\bar{y})^2 + \cdots + (y_n-\bar{y})^2\]
- Note that SST does not involve the model at all
- However, can think of a null model that uses the sample mean as the prediction
- SST is the sum of the squared residuals for the null model
Sum of Squared Errors
- sum of squared errors, denoted SSE, quantifies the variation in outcomes that the model fails to describe \[\begin{array}{rcl}SSE &=& (y_1-\hat{y}_1)^2 + (y_2-\hat{y}_2)^2 + \cdots + (y_n-\hat{y}_n)^2 \\ &=& e_1^2 + e_2^2 + \cdots + e_n^2\end{array}\]
- Given by the sum of the squared residuals, which we have encountered before
Regression Sum of Squares
- regression sum of squares, denoted SSR, measures the variation that is accounted for by the model \[SSR = SST - SSE\]
- Hence, the proportion of variation in the outcome that is described by the model is \[R^2 = \frac{SST - SSE}{SST} = 1 - \frac{SSE}{SST}\]
- We can have R compute \(R^2\)
- Height explains about 51.5% of the variability in weights
# A tibble: 1 × 12
r.squared adj.r.squared sigma statistic p.value df logLik AIC BIC
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0.515 0.514 9.31 535. 2.83e-81 1 -1849. 3705. 3718.
# ℹ 3 more variables: deviance <dbl>, df.residual <int>, nobs <int>Sex explains about 46.9% of the variability in heights
# A tibble: 1 × 12
r.squared adj.r.squared sigma statistic p.value df logLik AIC BIC
<dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 0.469 0.468 6.86 446. 2.23e-71 1 -1695. 3396. 3409.
# ℹ 3 more variables: deviance <dbl>, df.residual <int>, nobs <int>Residual plots
- residual plot is a plot of residuals vs. predicted values (scatter plot with points \((\hat{y}_i,e_i)\)
- Useful for diagnosing problems with the linear models
- If there is a pattern in the residual plot, then a more complicated model (e.g., a nonlinear model or a model that includes more predictors) may be more appropriate
- Residual plot can be created using the
augmentfunction from thebroompackage. - The predictions are stored in the variable \(.fitted\) and the residuals are stored as \(.resid\)
There are no obvious patterns in the height vs. weight residual plot.
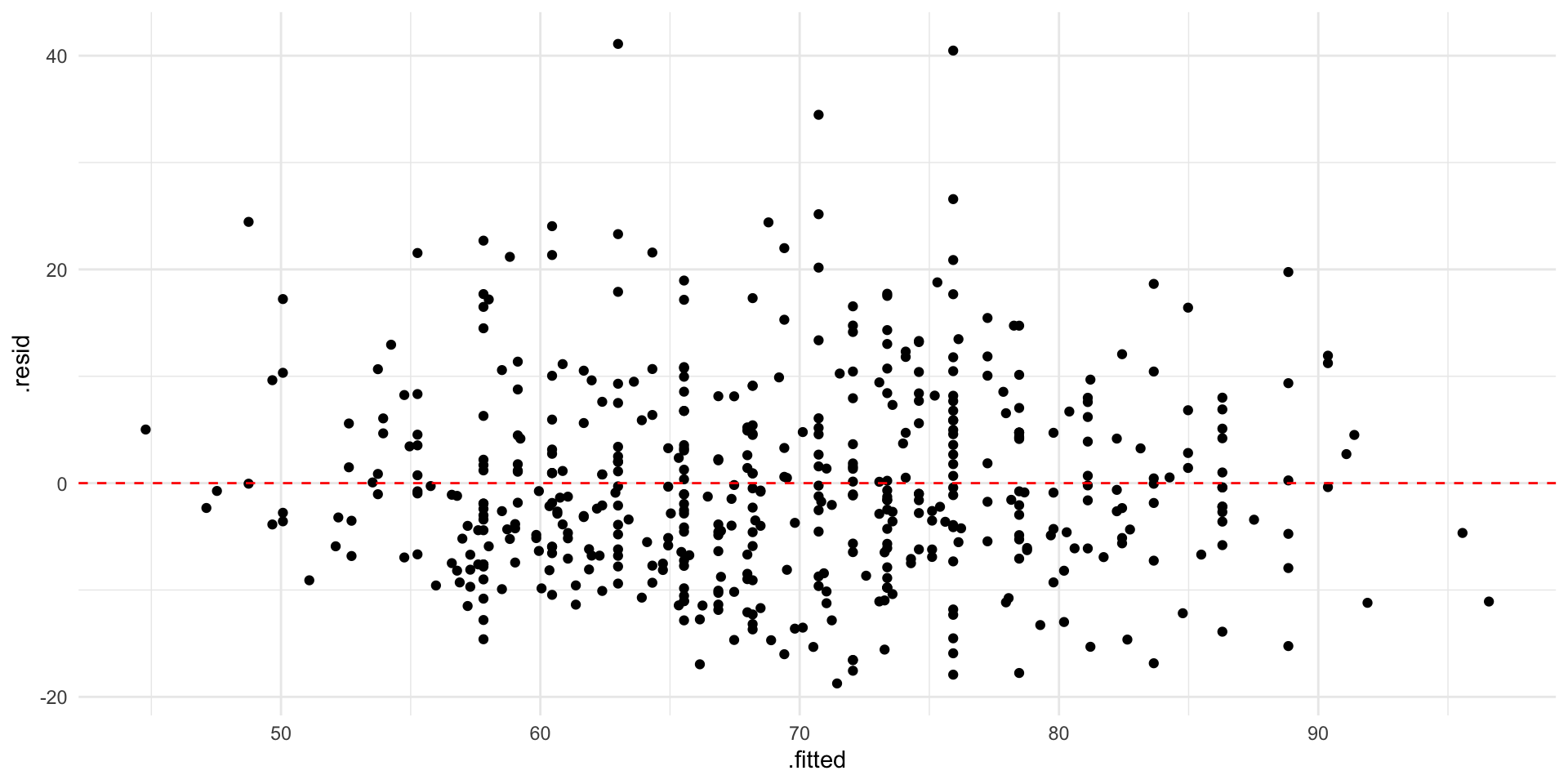
Residual plot for weight vs. height with horizontal line at \(e=0\) for reference.
More residual plots
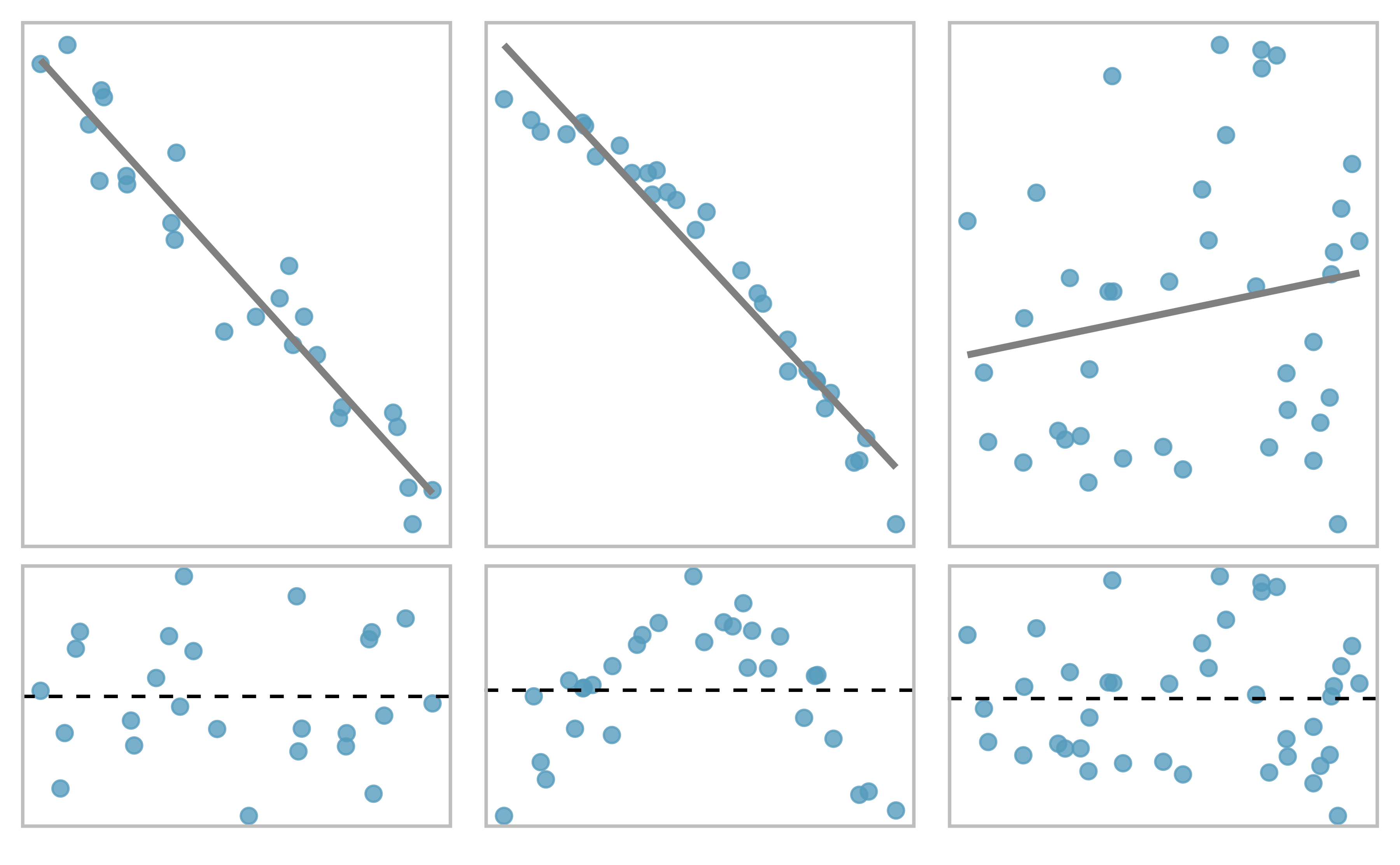
Some scatter plots (top) and corresponding residual plots (bottom). From IMS1 Fig. 7.10
More residual plots
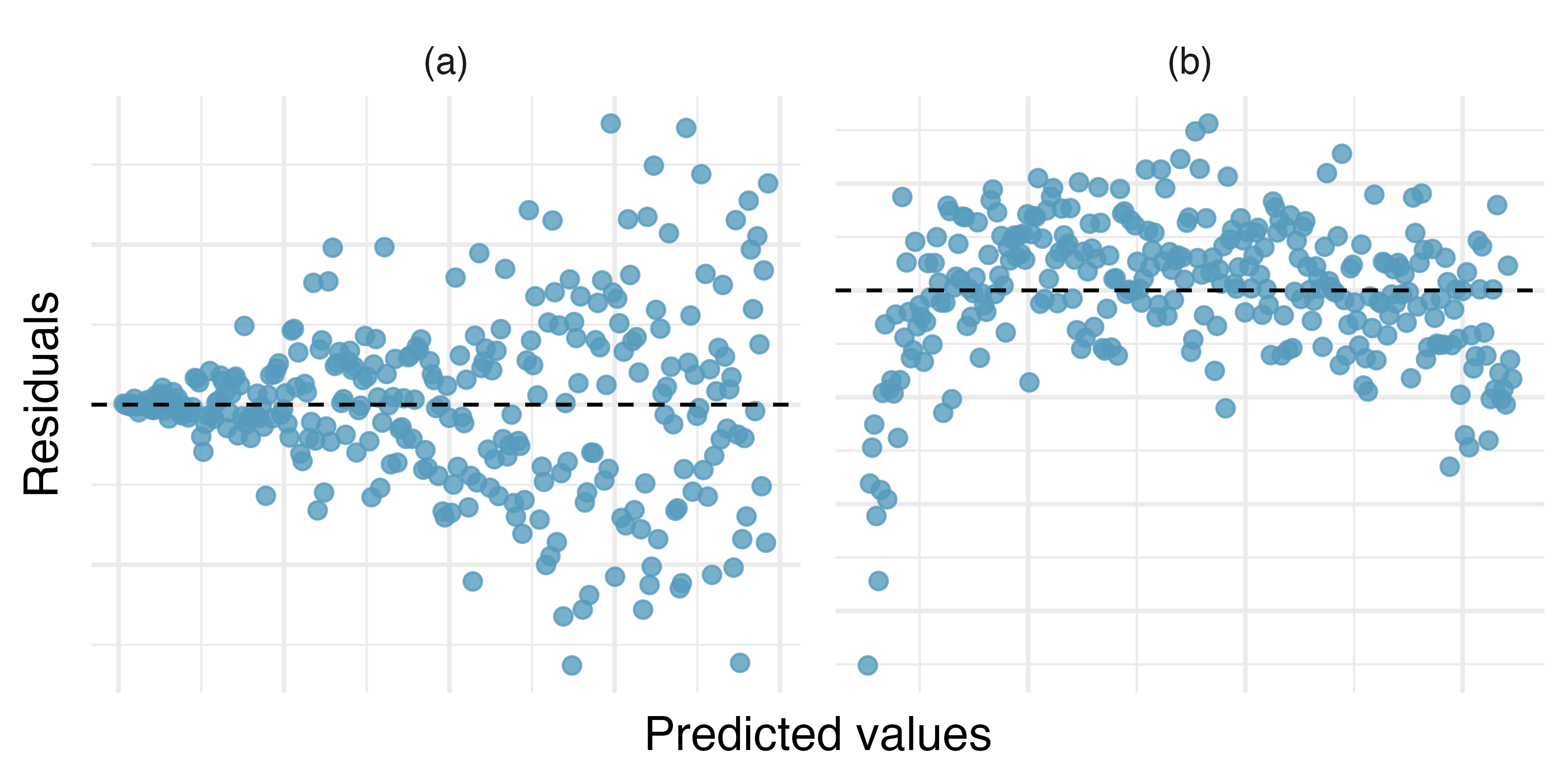
More residual plots. From IMS1 Ex. 7.2
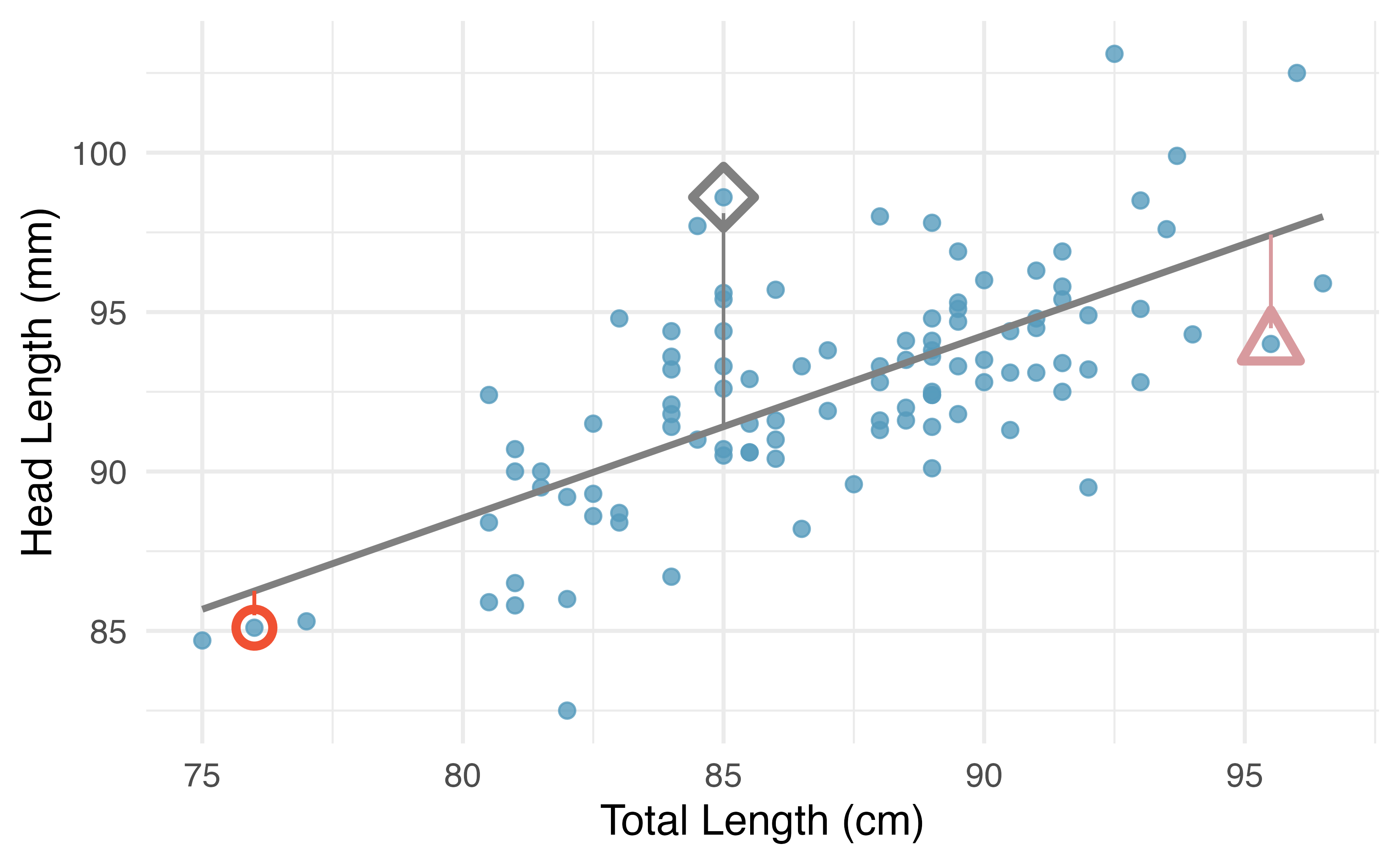
Outliers
- outliers are observations that fall far from the point cloud
- high leverage points fall horizontally far from the center of the point cloud
- high leverage points have more pull on the regression line
- influential points have a strong influence on the slope of the regression line
- influential points can be identified by fitting a line with the point removed. If the slope is very different than when the point is included, then the point is influential.
Each of the following plots has an outlier. Which are high leverage? Influential?
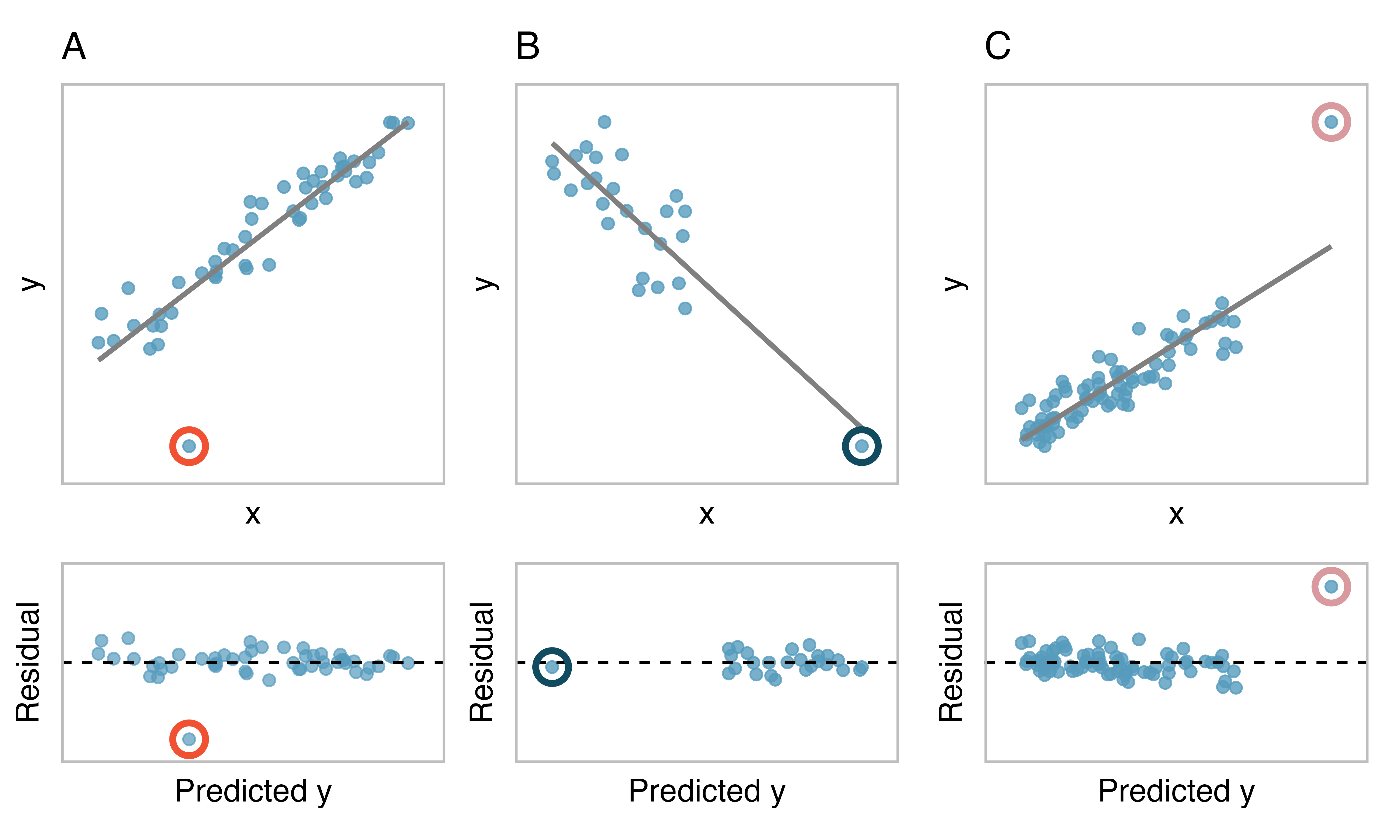
Scatter plots with outliers. From IMS1 Fig. 7.17.