| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | -186.302648 | 47.3081367 | -3.938068 | 0.0009641 |
| hgt | 1.507037 | 0.2759548 | 5.461175 | 0.0000346 |
Inference: Regression Single Predictor
Chapter 24
Math 115
Math 115
Regression Line
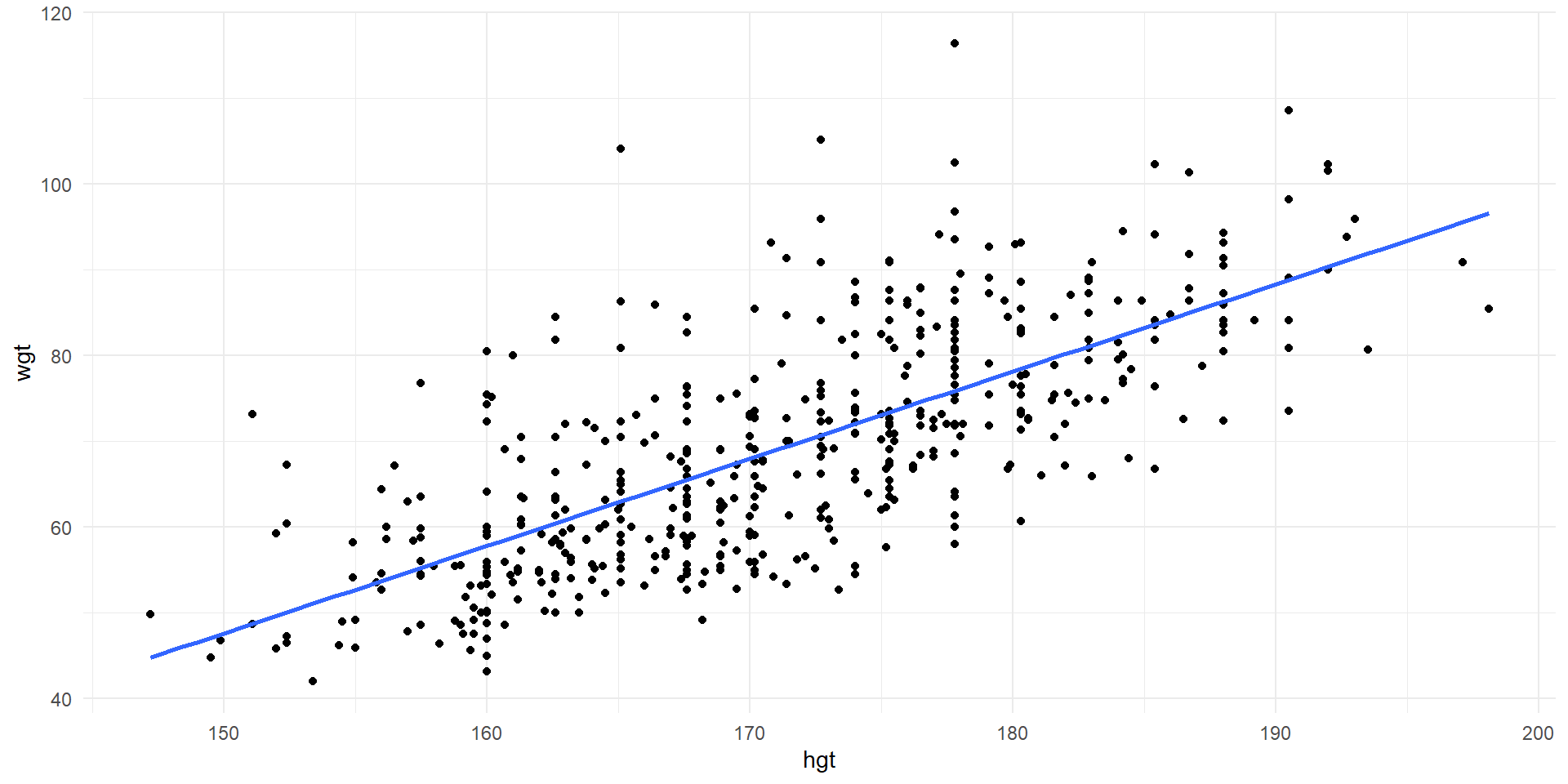
Observations of wgt vs. hgt and least squares line for the entire population.
- Least squares regression line (Recall from Chapter 7) \[\widehat{Weight}=-105.01+1.02\times Height\]
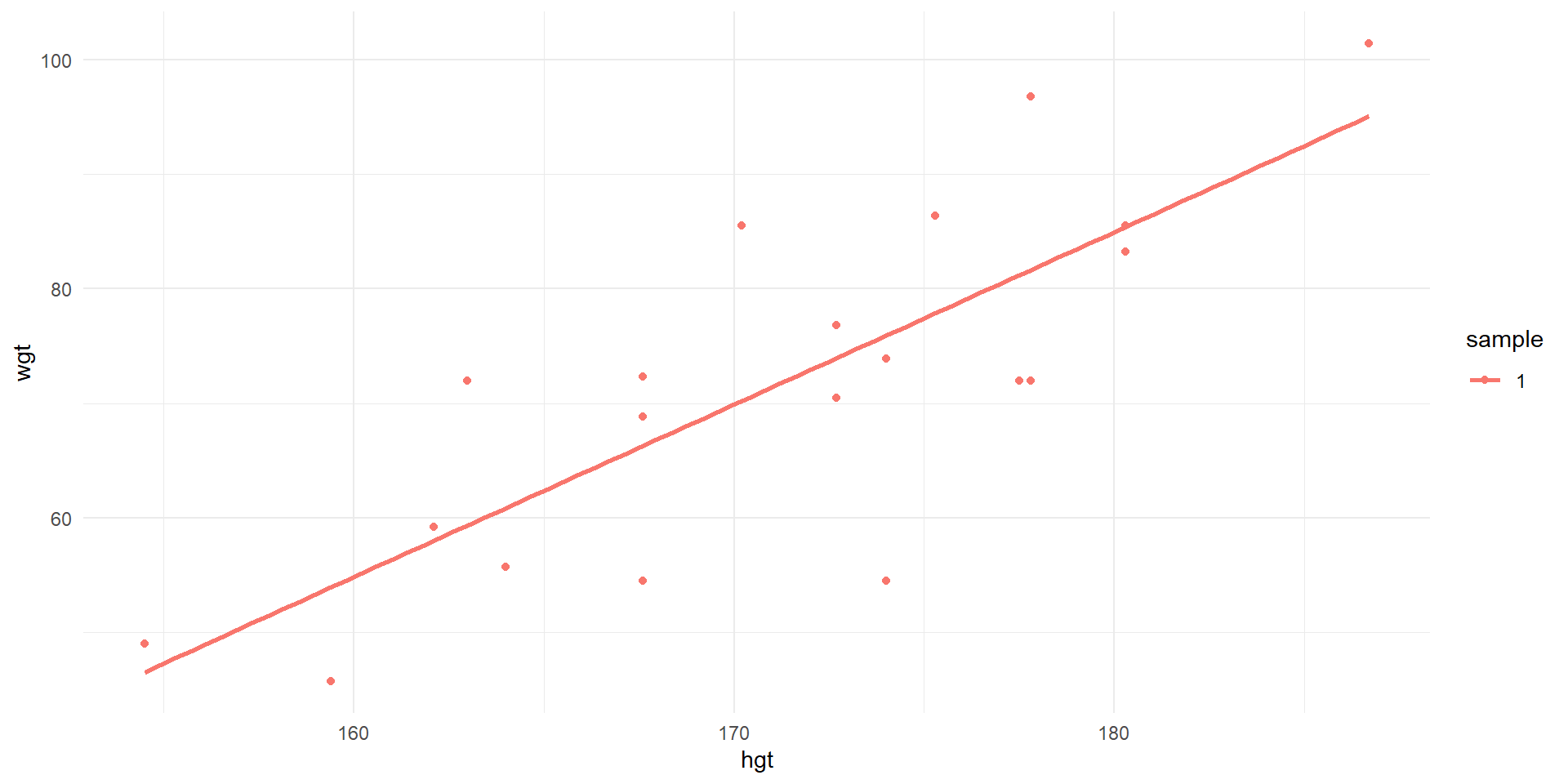
Observations of wgt vs. hgt and least squares line for first sample of 20.
Sample 1
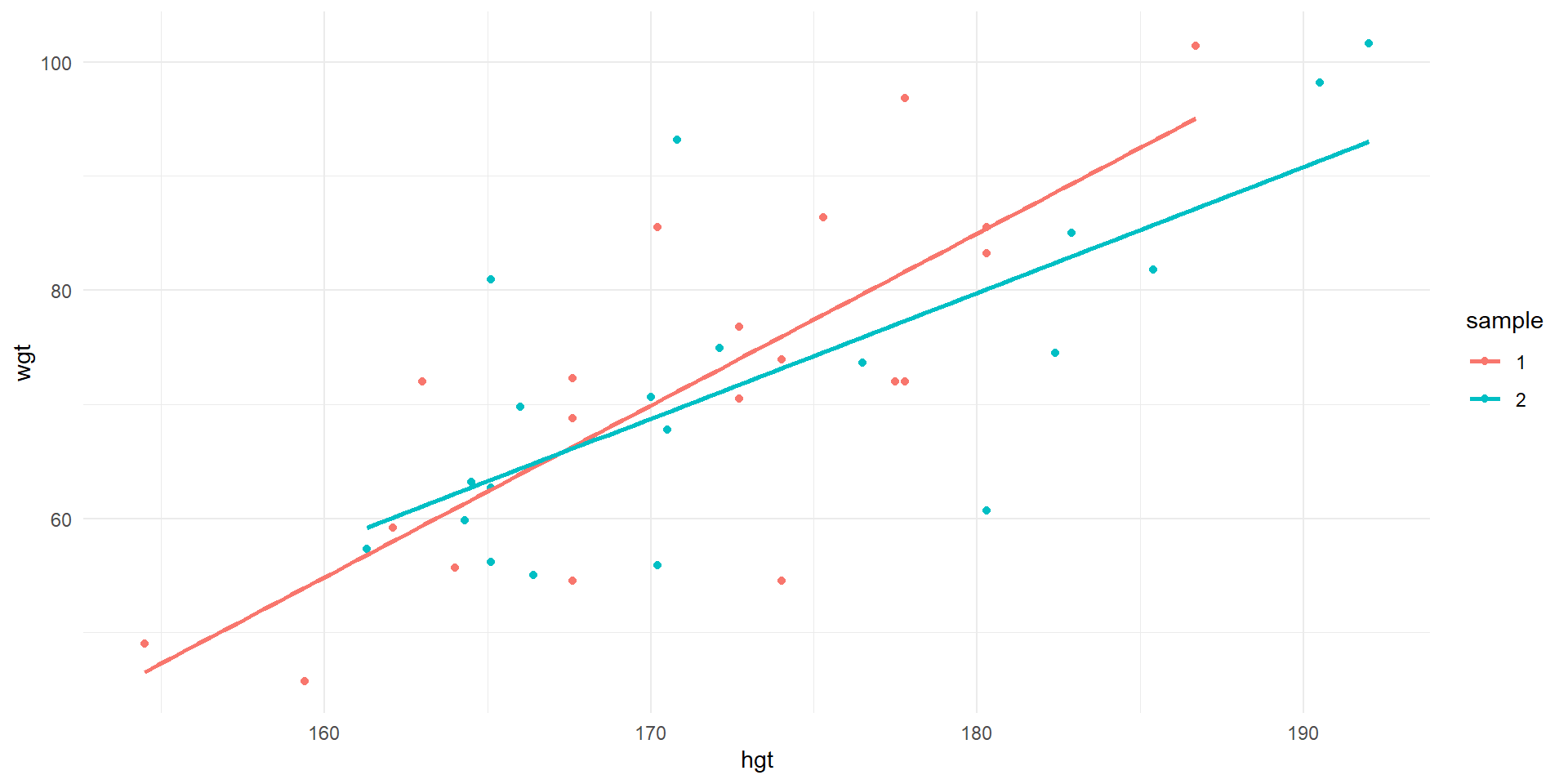
Observations of wgt vs. hgt and least squares lines for first two samples of 20.
Sample 2
| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | -186.302648 | 47.3081367 | -3.938068 | 0.0009641 |
| hgt | 1.507037 | 0.2759548 | 5.461175 | 0.0000346 |
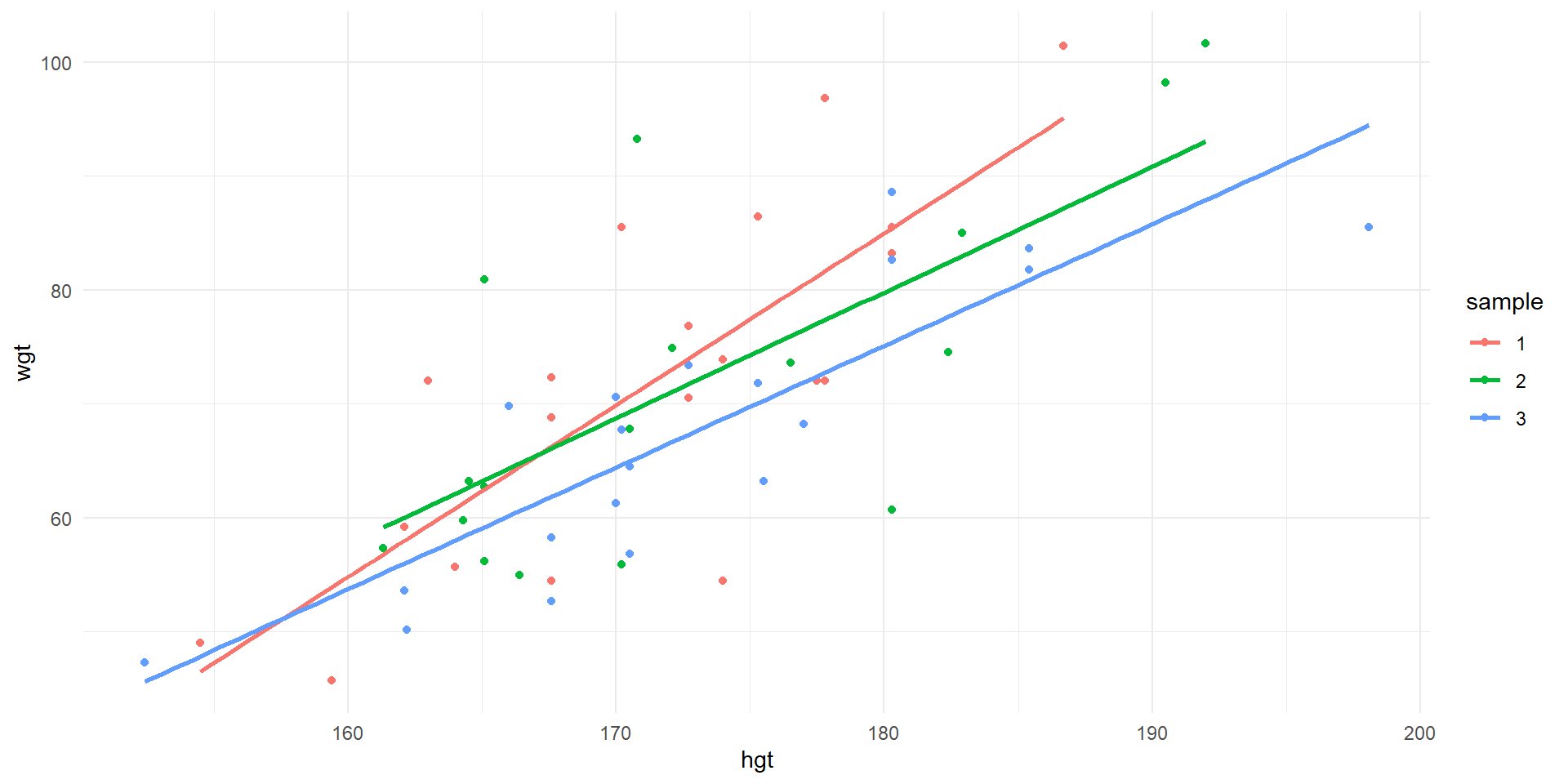
Observations of wgt vs. hgt and least squares lines for first three samples of 20.
Sample 3
| term | estimate | std.error | statistic | p.value |
|---|---|---|---|---|
| (Intercept) | -186.302648 | 47.3081367 | -3.938068 | 0.0009641 |
| hgt | 1.507037 | 0.2759548 | 5.461175 | 0.0000346 |
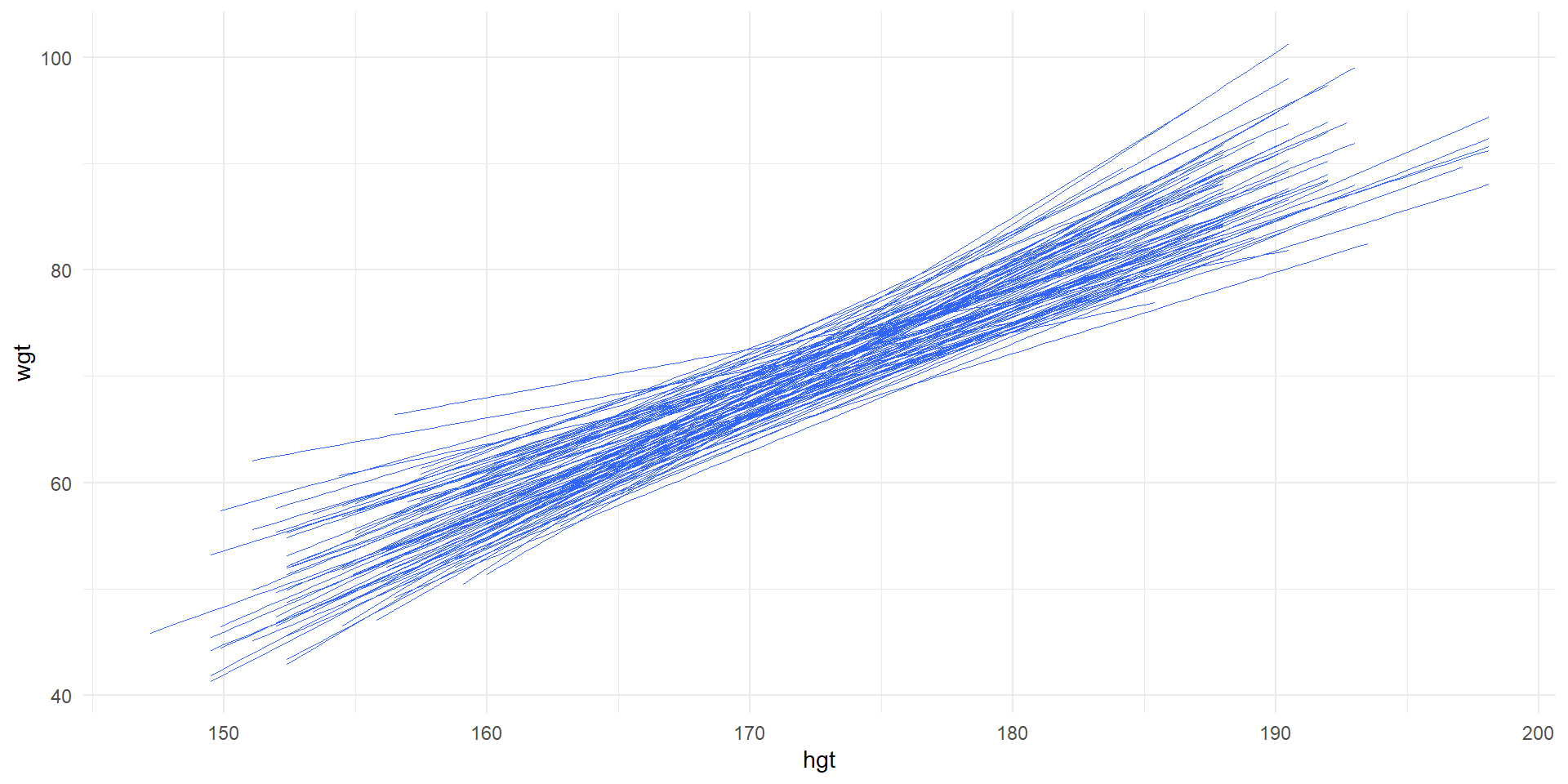
Least squares lines for 100 random samples of 20.
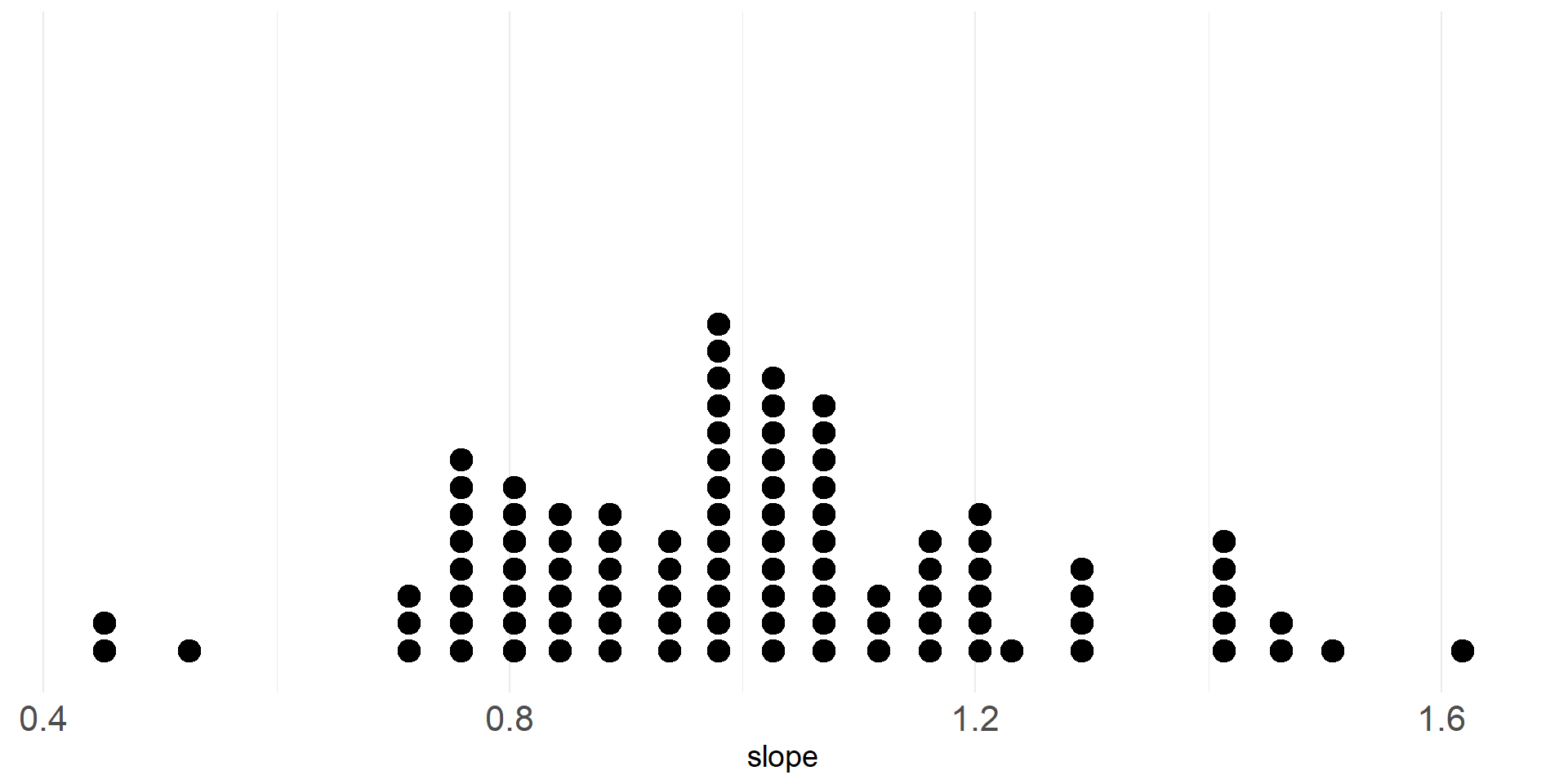
Dotplot of slopes of least squares lines from 100 random samples.
| n | mean | sd |
|---|---|---|
| 100 | 1.009732 | 0.220826 |
- Let us run 100 such simulations first
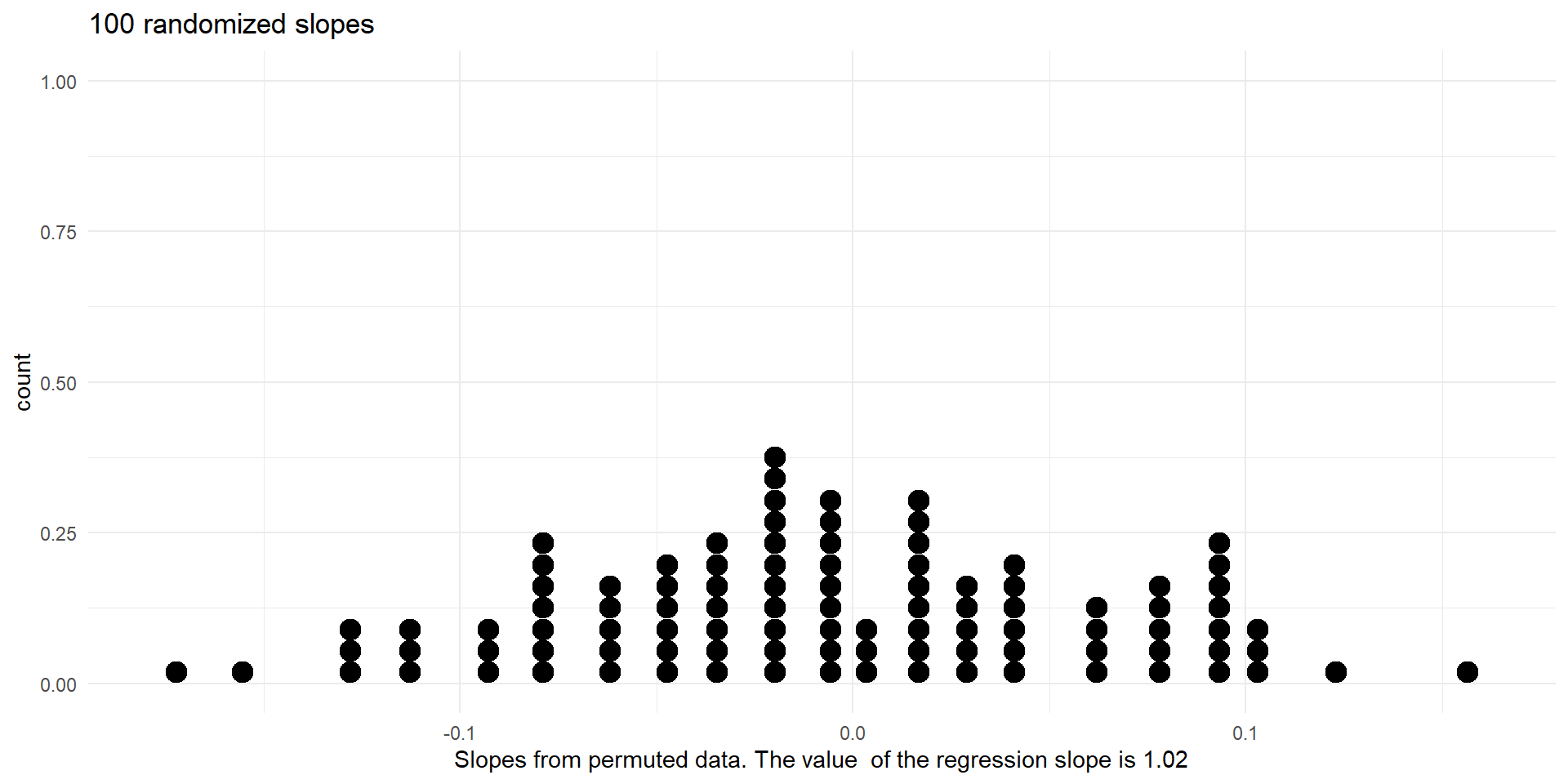
- Now we will conduct 1,000 simulations
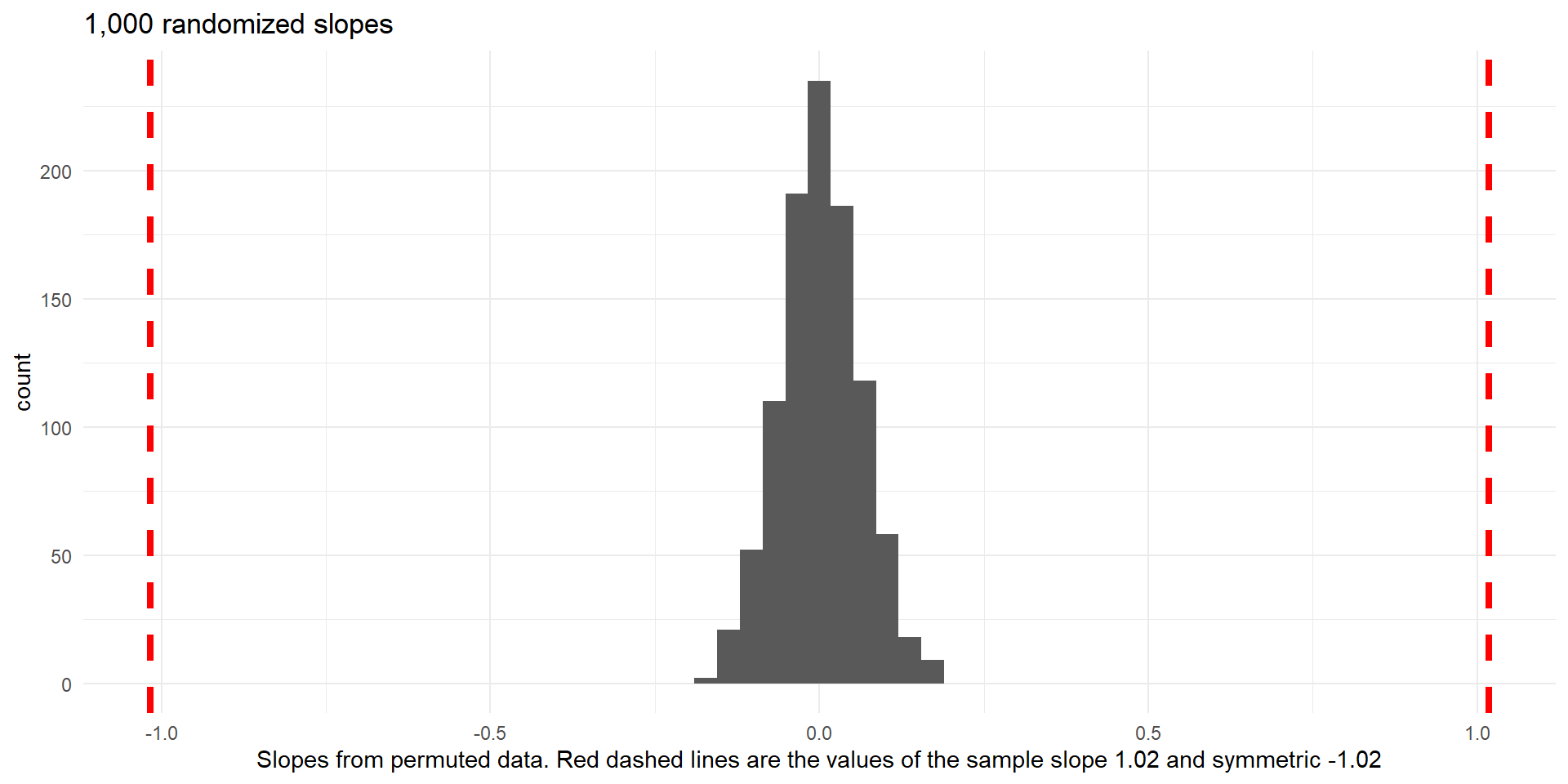
p-value \(\approx0\)
Checking Conditions
Linearity? Independent observations? Normality of residuals? Constant variability?
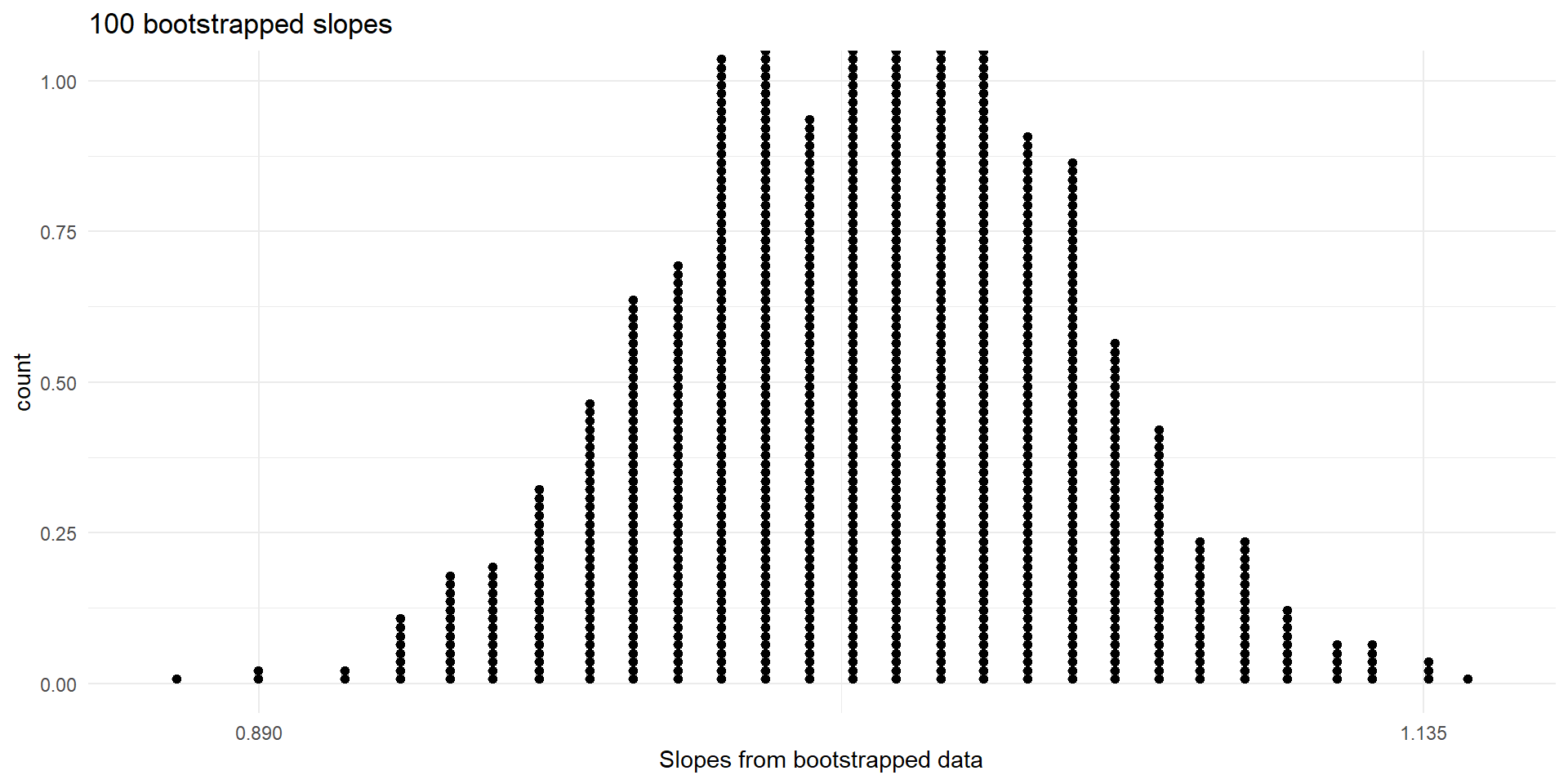
- Let us create 100 bootstrapped slopes first
- Now we will use 1,000 bootstrapped slopes
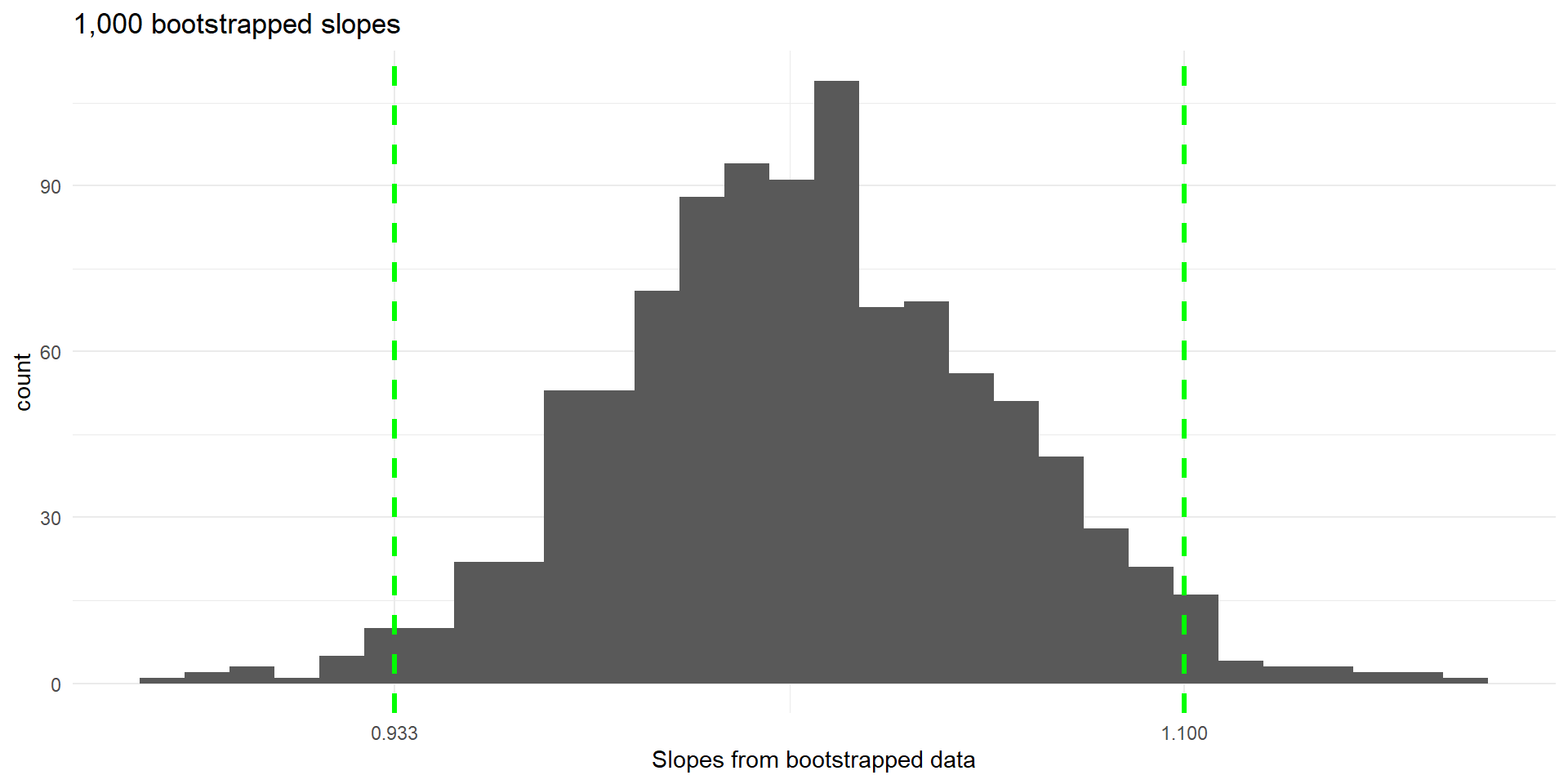
95% bootstrap percentile confidence interval: \((0.933, 1.10)\)
We are 95% confident that the slope is between 0.933 and 1.10, meaning that the weight increases from 0.933 to 1.1 kilograms for each increase of 1 cm in the height.
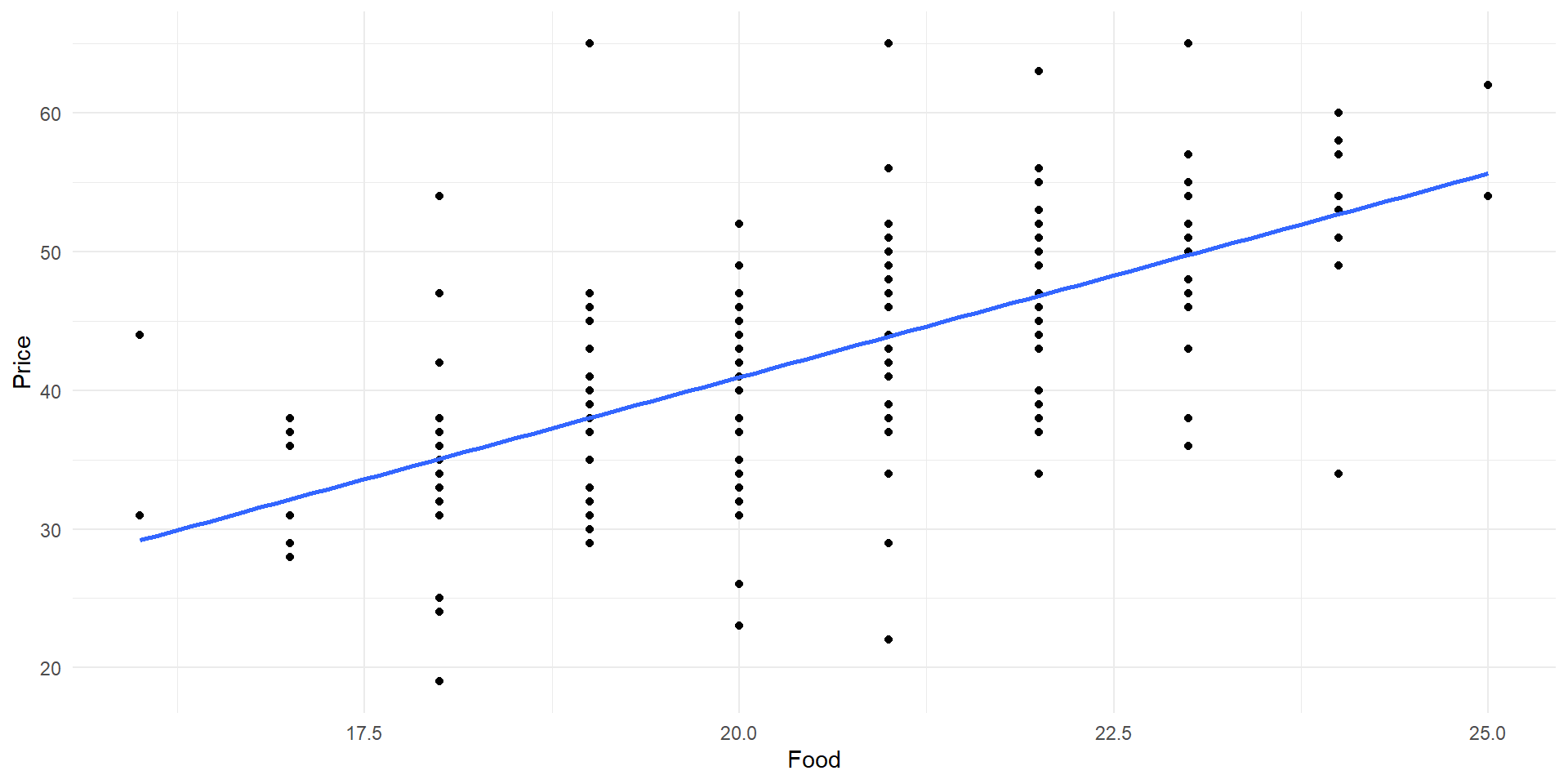
Scatter plot of Price vs Food with least squares line.
Checking Conditions
Linearity? Independent observations? Normality of residuals? Constant variability?
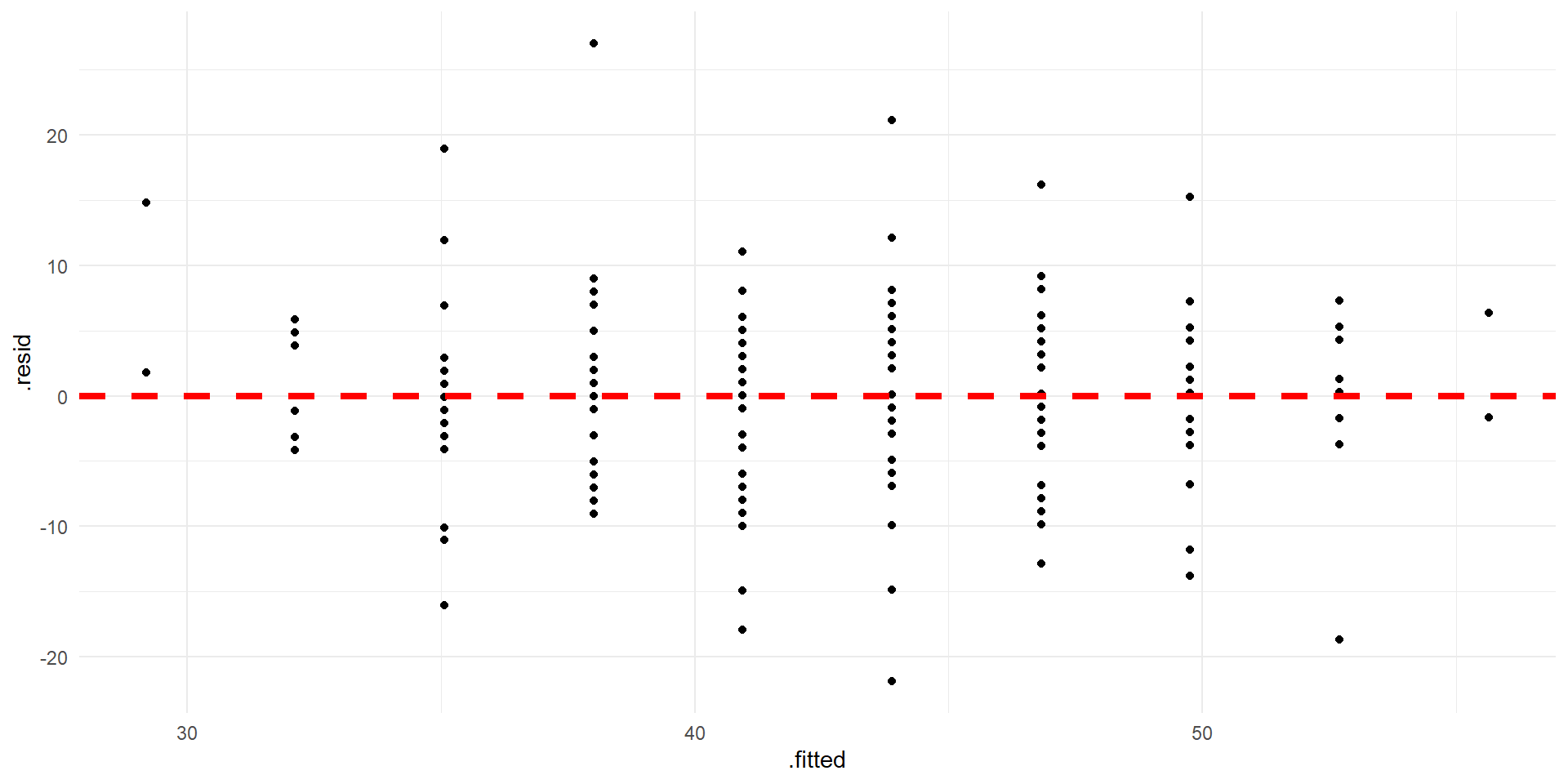
Residual plot.
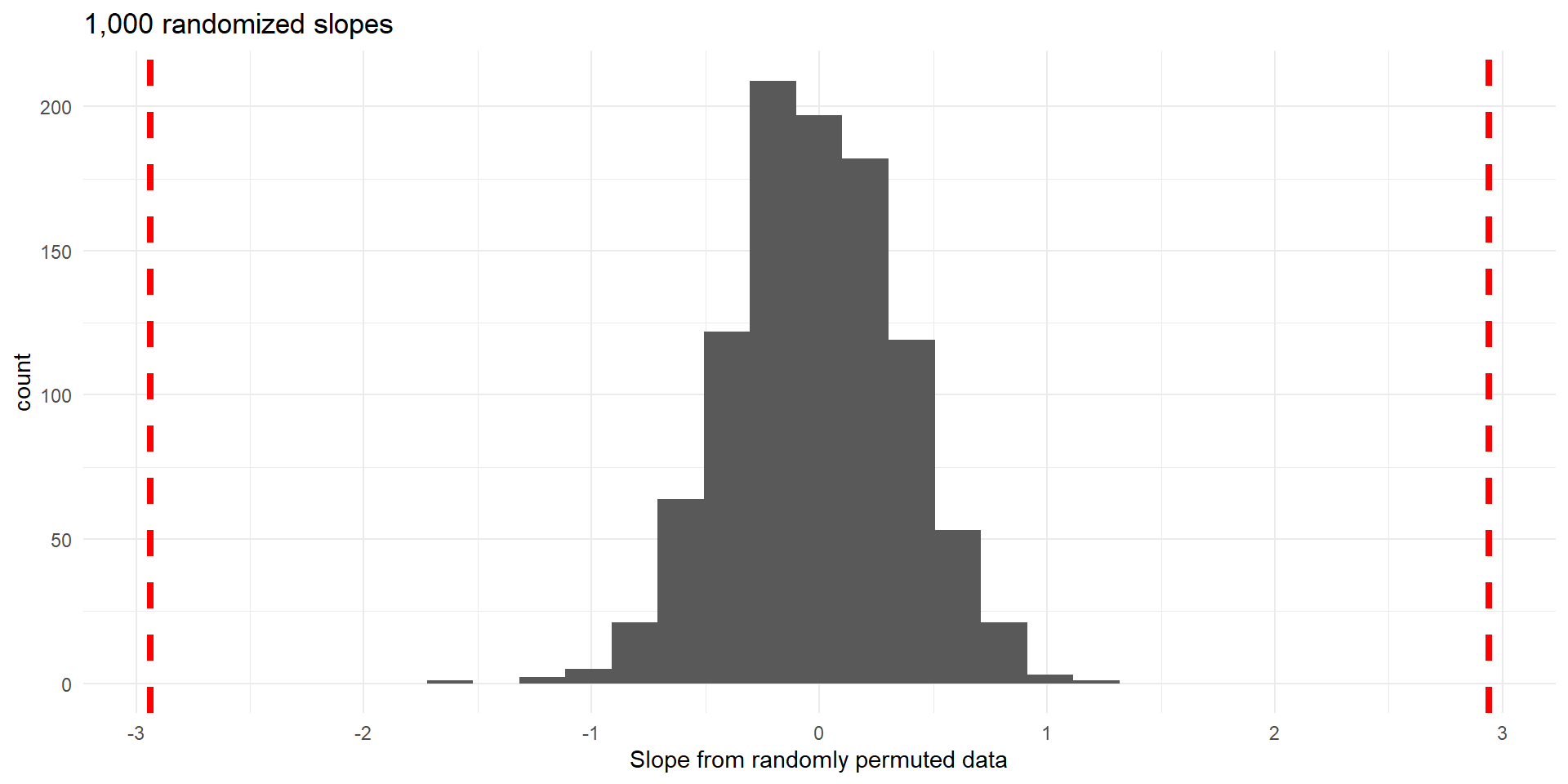
Histogram of slopes from different random permultations of Price (null distribution).
The proportion of values \(\ge 2.94\) or \(\le -2.94\) is 0, so p-value \(\approx0\)
CI Using Randomization
- We can also calculate a 95% bootstrap percentile confidence interval
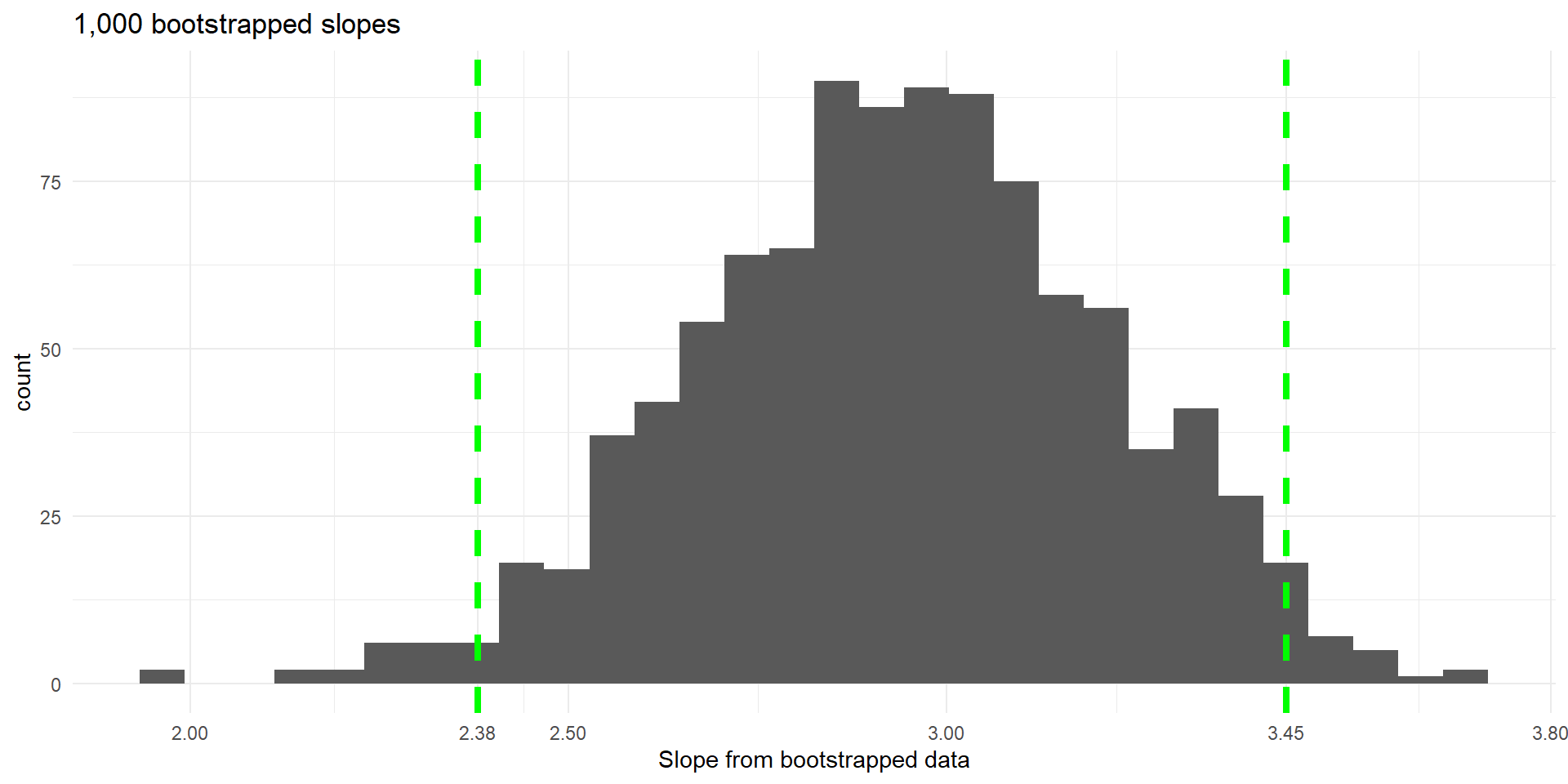
95% bootstrap percentile confidence interval: (2.38, 3.45)
- We are 95% confident that the slope is between 2.38 and 3.45, meaning that the price of a meal increases by between $2.38 and $3.45 for each increase of 1 point in the food rating.