# A tibble: 68 × 4
subject course_num bookstore_new amazon_new
<fct> <fct> <dbl> <dbl>
1 American Indian Studies M10 48.0 47.4
2 Anthropology 2 14.3 13.6
3 Arts and Architecture 10 13.5 12.5
4 Asian M60W 49.3 55.0
5 Astronomy 4 120. 125.
6 Communication 10 17.0 11.8
7 Comparative Literature 2CW 12.0 10.9
8 Dance 10 26.8 38.9
9 English 19 9.96 8.99
10 English Composition 1A 40.0 35
# ℹ 58 more rowsCompare Paired Means
Chapter 21
Math 115
Math 115
- What if everyone could remember exactly 2 more words when they listened to a song without lyrics?
- There could be a lot of overlap between the two sets of scores and it would be difficult to detect a difference as shown here.
- We need to focus on differences within matching pairs
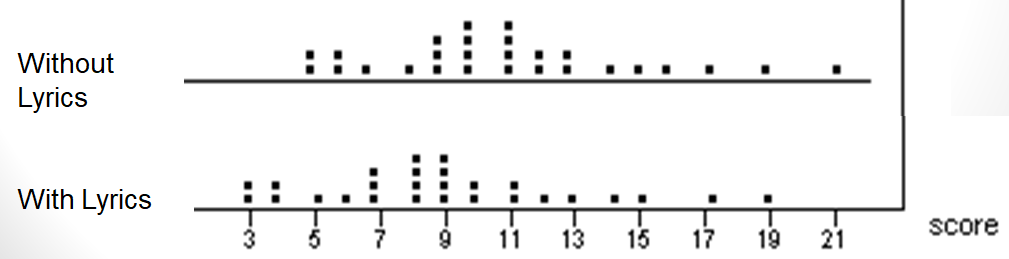
Here are side-by-side dotplots
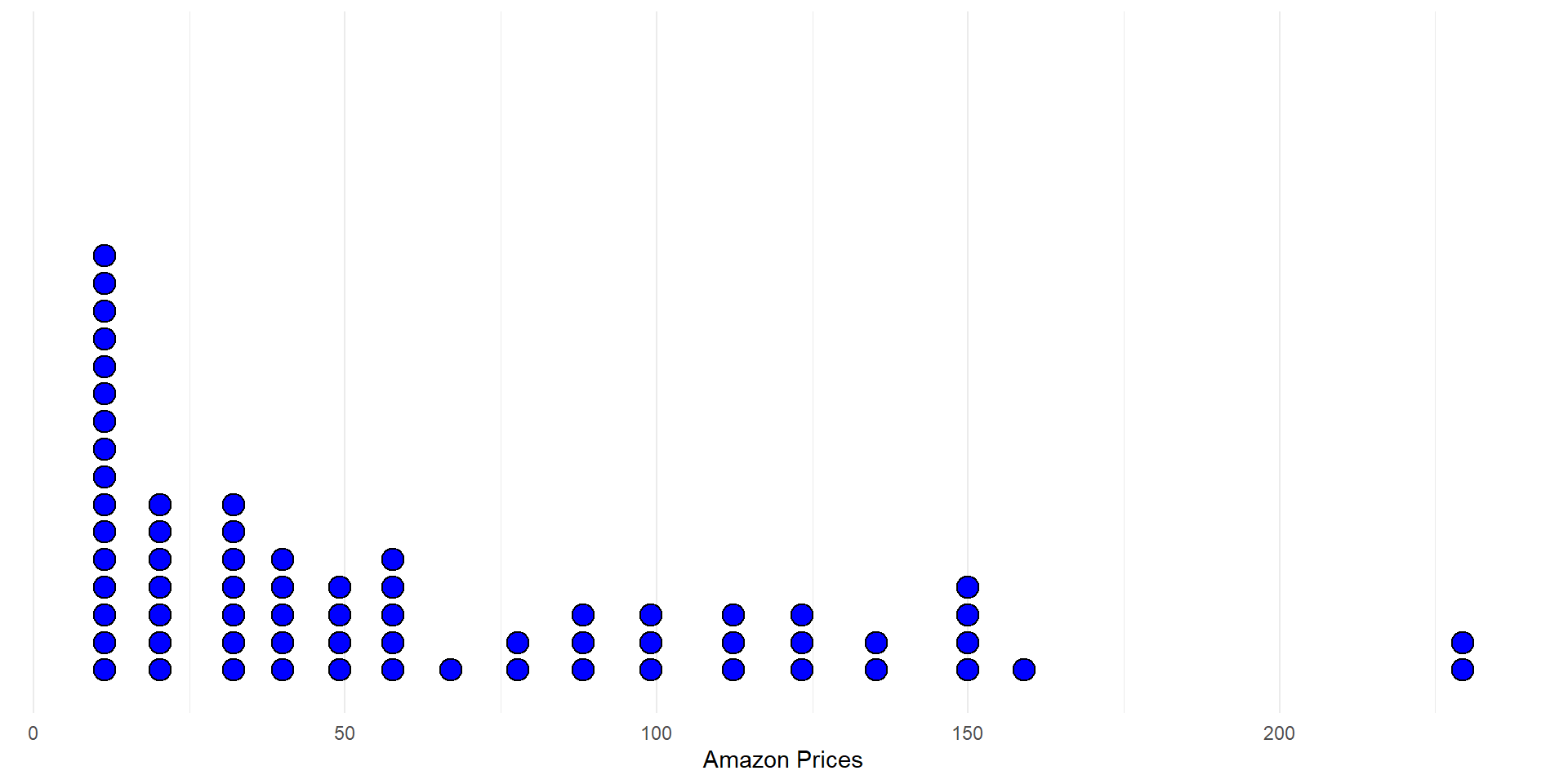
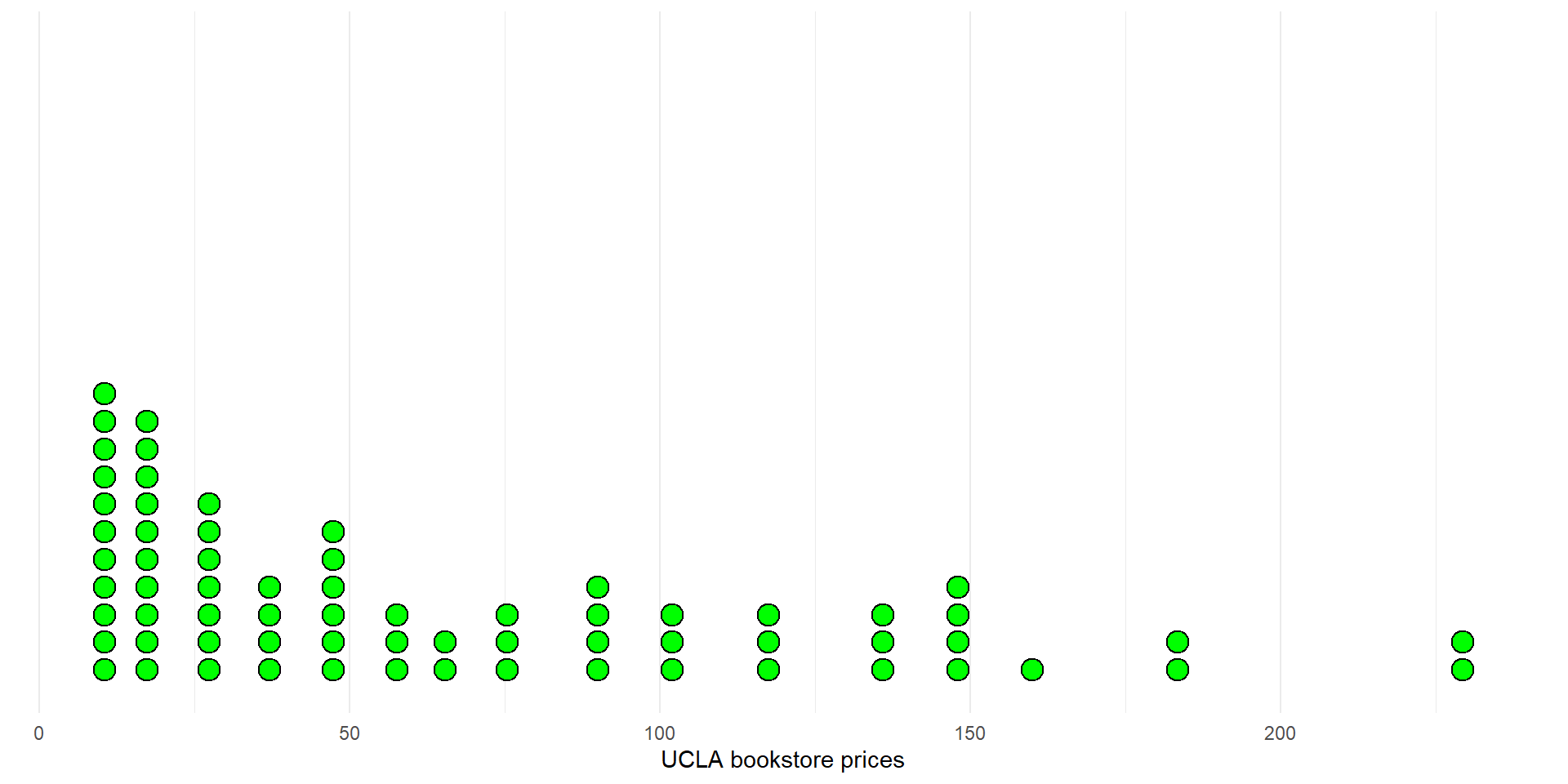
Paired dotplots and histogram of differences
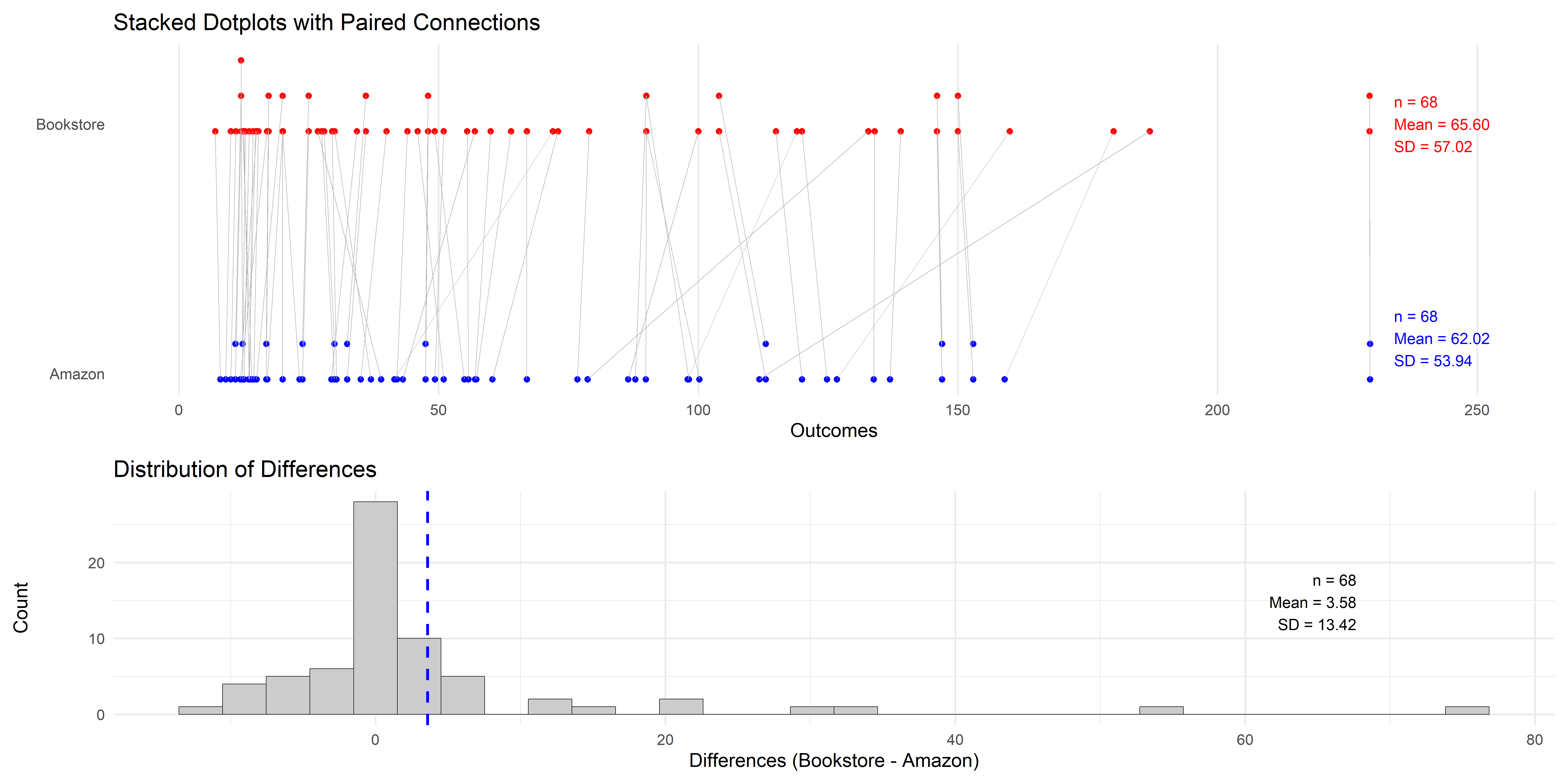
Differences in prices
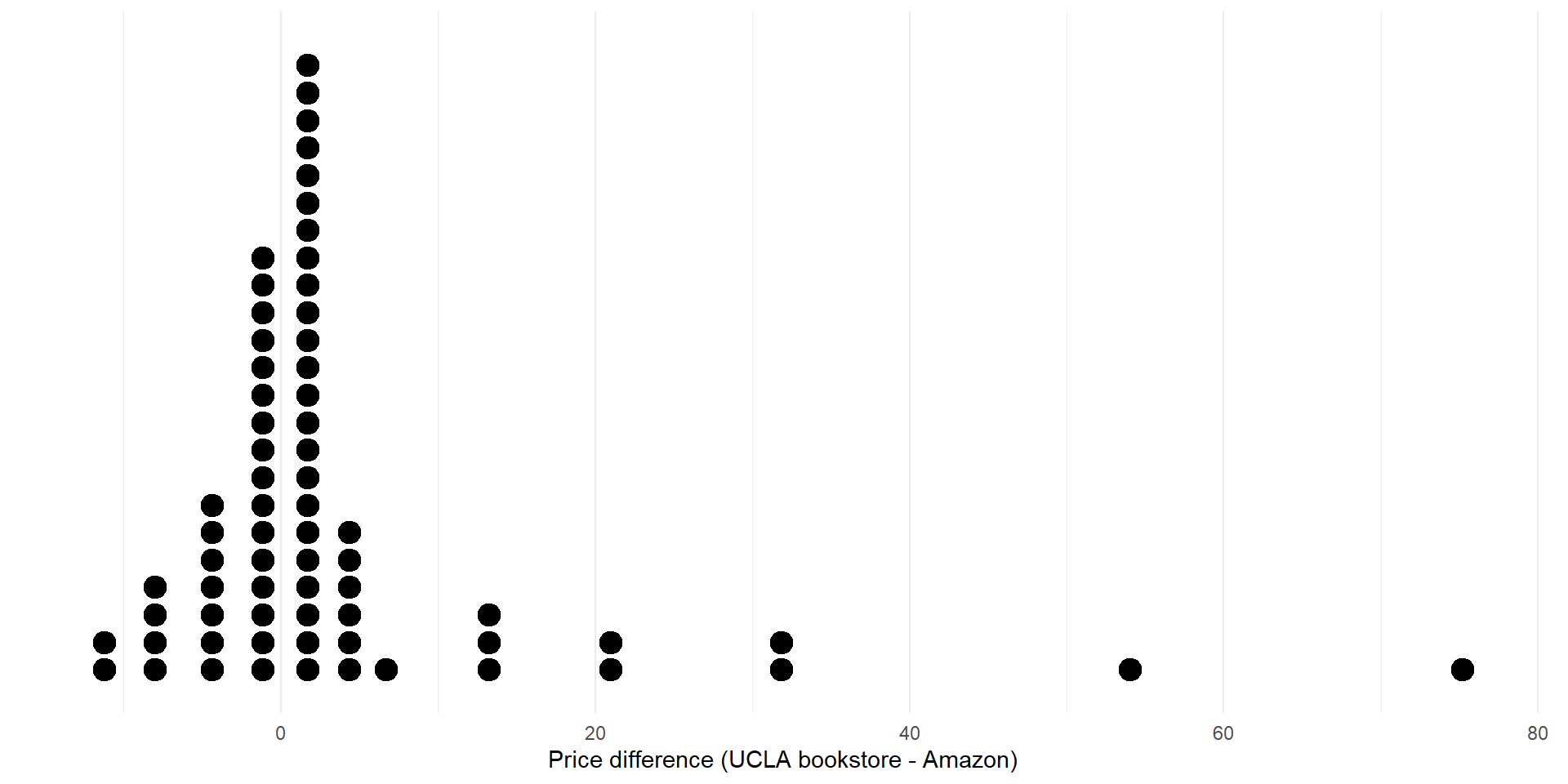
| n | mean | median | sd | iqr |
|---|---|---|---|---|
| 68 | 3.58 | 0.625 | 13.4 | 3.98 |
- The observed mean difference is \(\bar{x}_{diff}=3.58\)
- Based on the shape of the distribution, you could easily argue that the median is a more appropriate measure of center!
- However, since the sample size is greater than 30, the means will have approximately t-distribution
- Let’s create 1,000 random permutations of the data
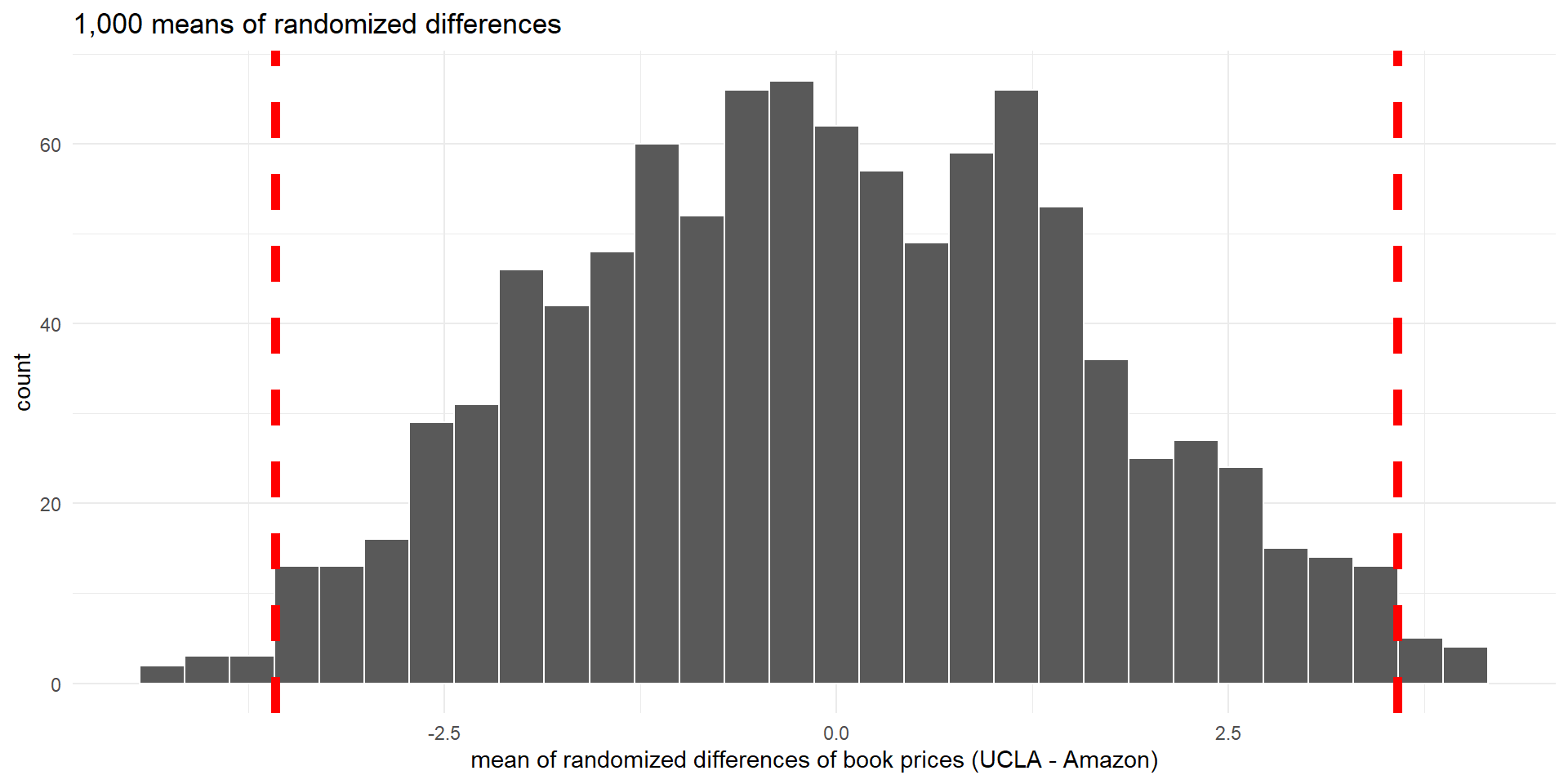
Histogram of 1,000 mean of randomized differences (null distribution). Dashed vertical lines indicate differences of 3.58 (observed mean difference) and -3.58.
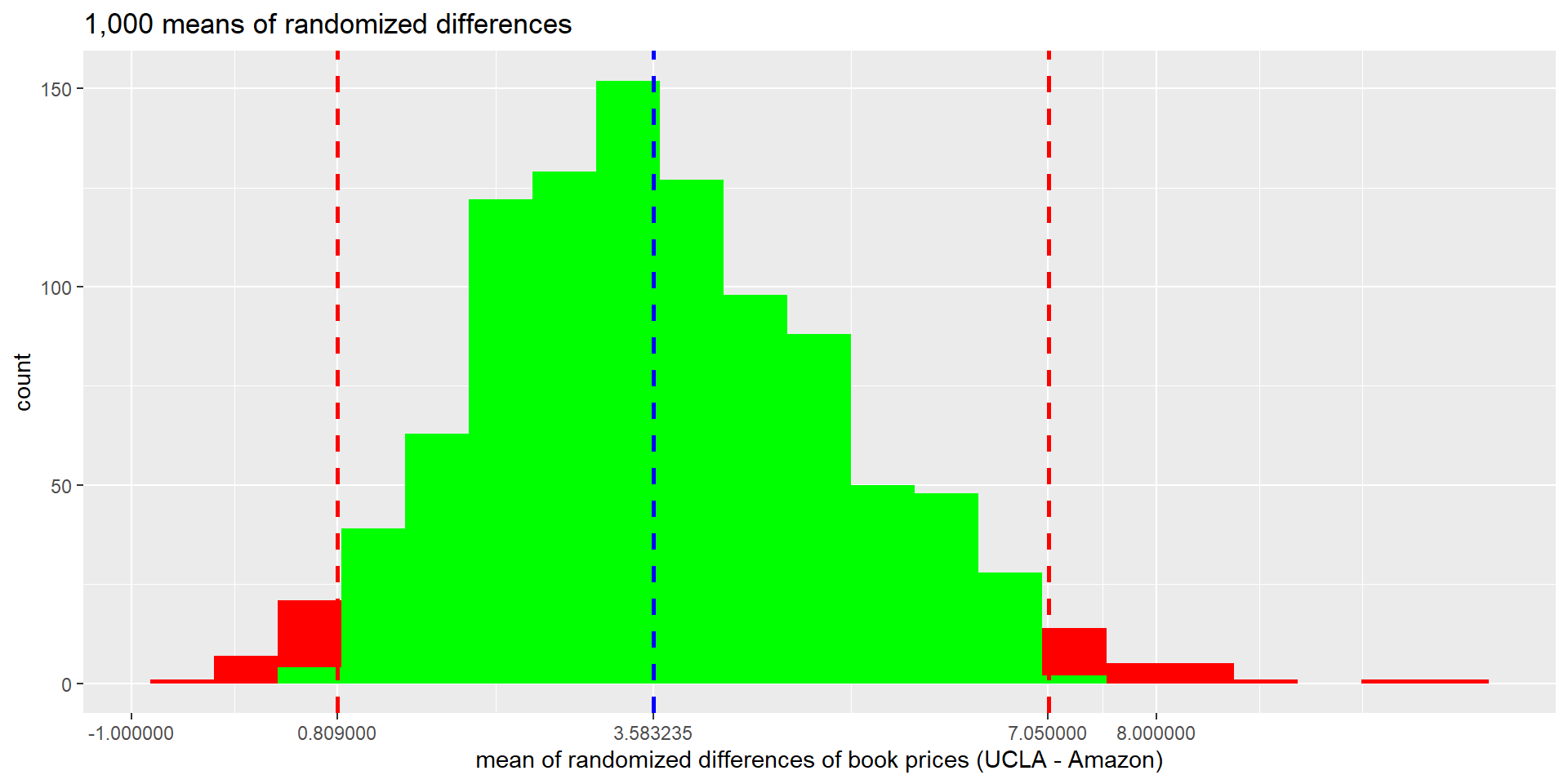
- The 95% bootstrap percentile confidence interval for the mean price difference is \((\$0.809, \$7.05)\).
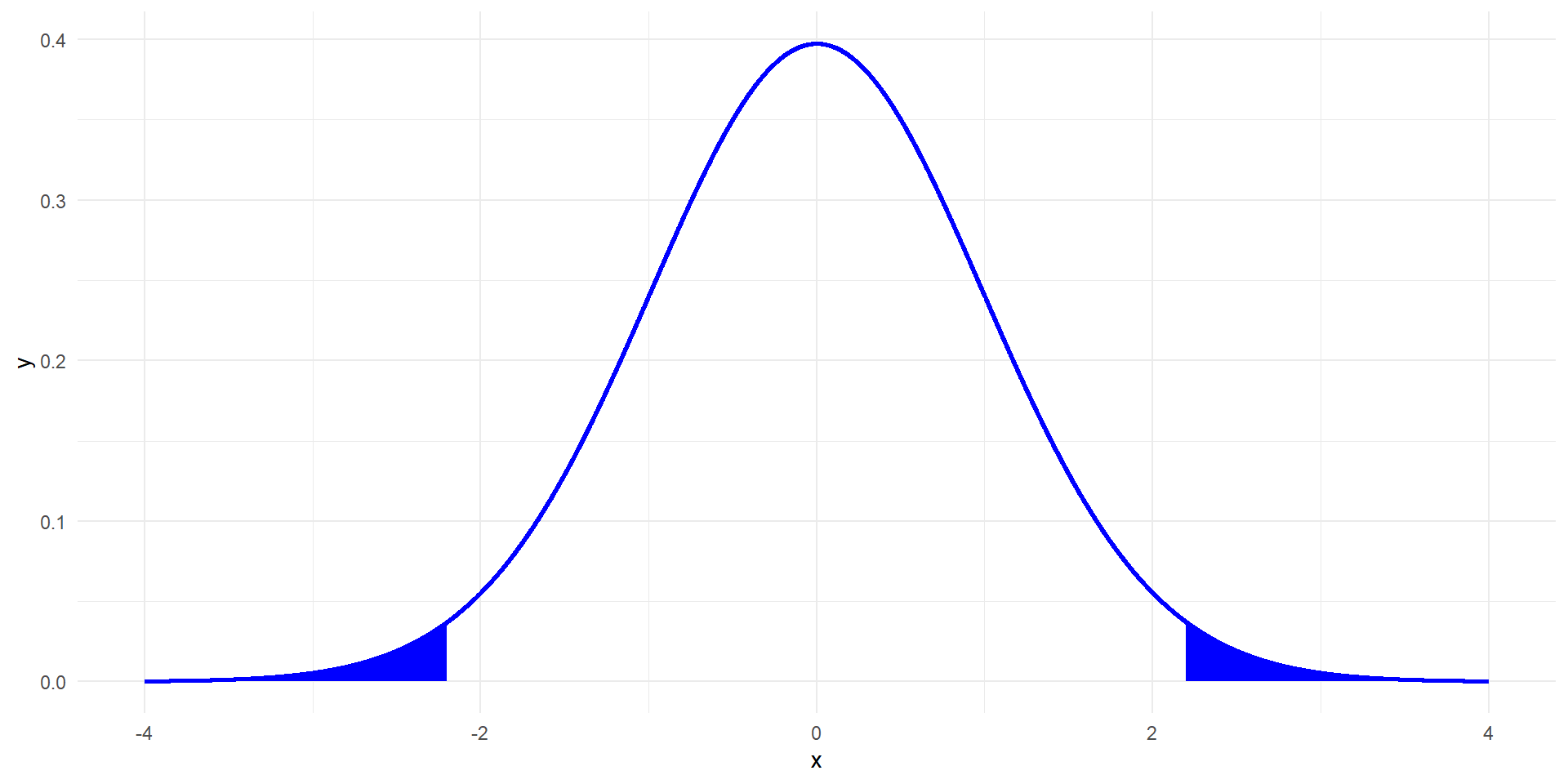
The degrees of freedom are \(df = 68-1=67\)
We can calculate a p-value by finding the area in the two tails of the \(t\)-distribution with \(df=67\) that is beyond -2.20 or 2.20
p-value of the two-sided test is 0.031
We can also find it in Jamovi