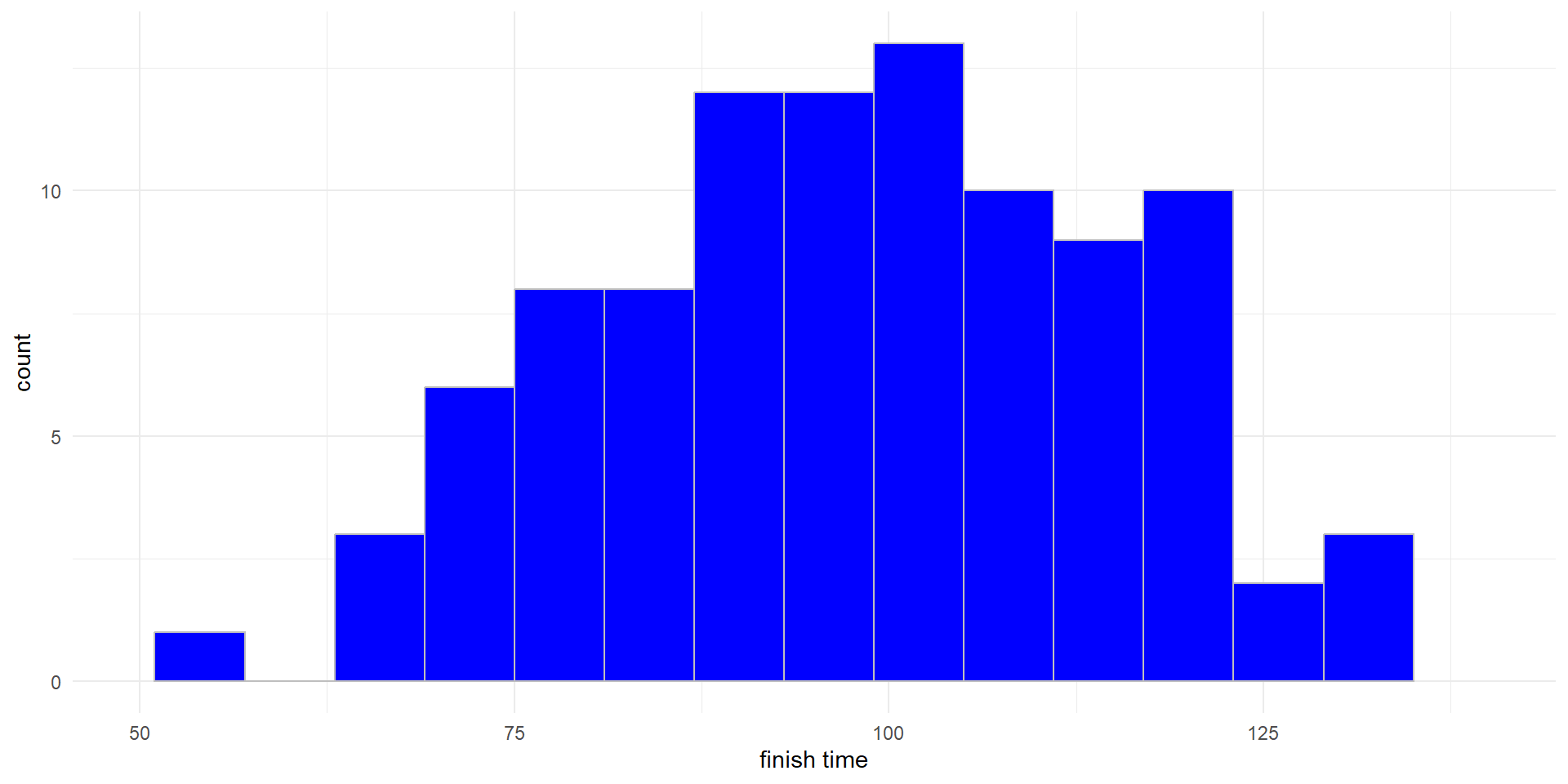
Inference: Single Mean
Chapter 19
Math 115
Math 115
Here are 5 bootstrapped means
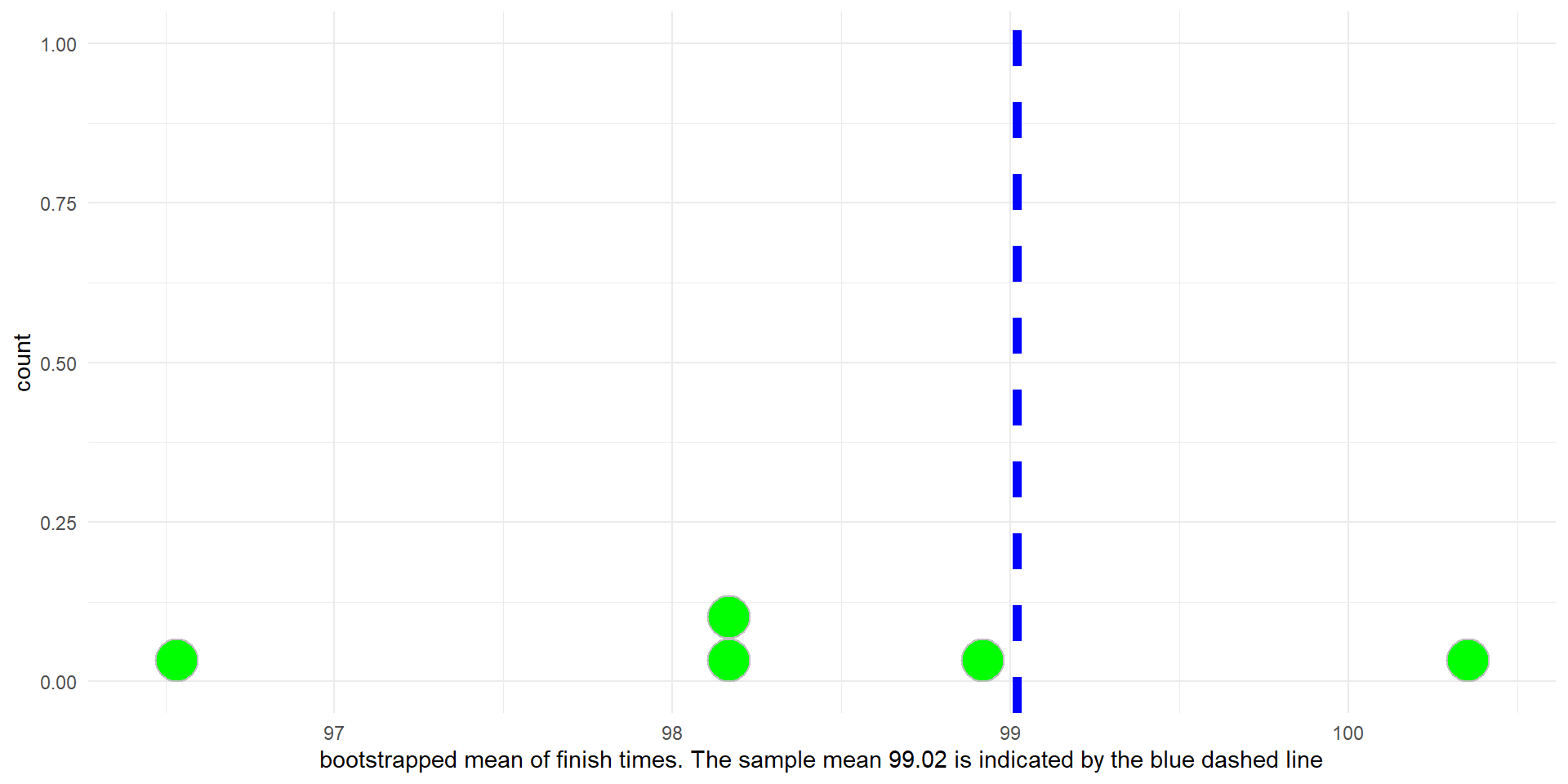
Histrogram showing 5 bootstrapped means.
Here is the result of 1,000 bootstapped means.
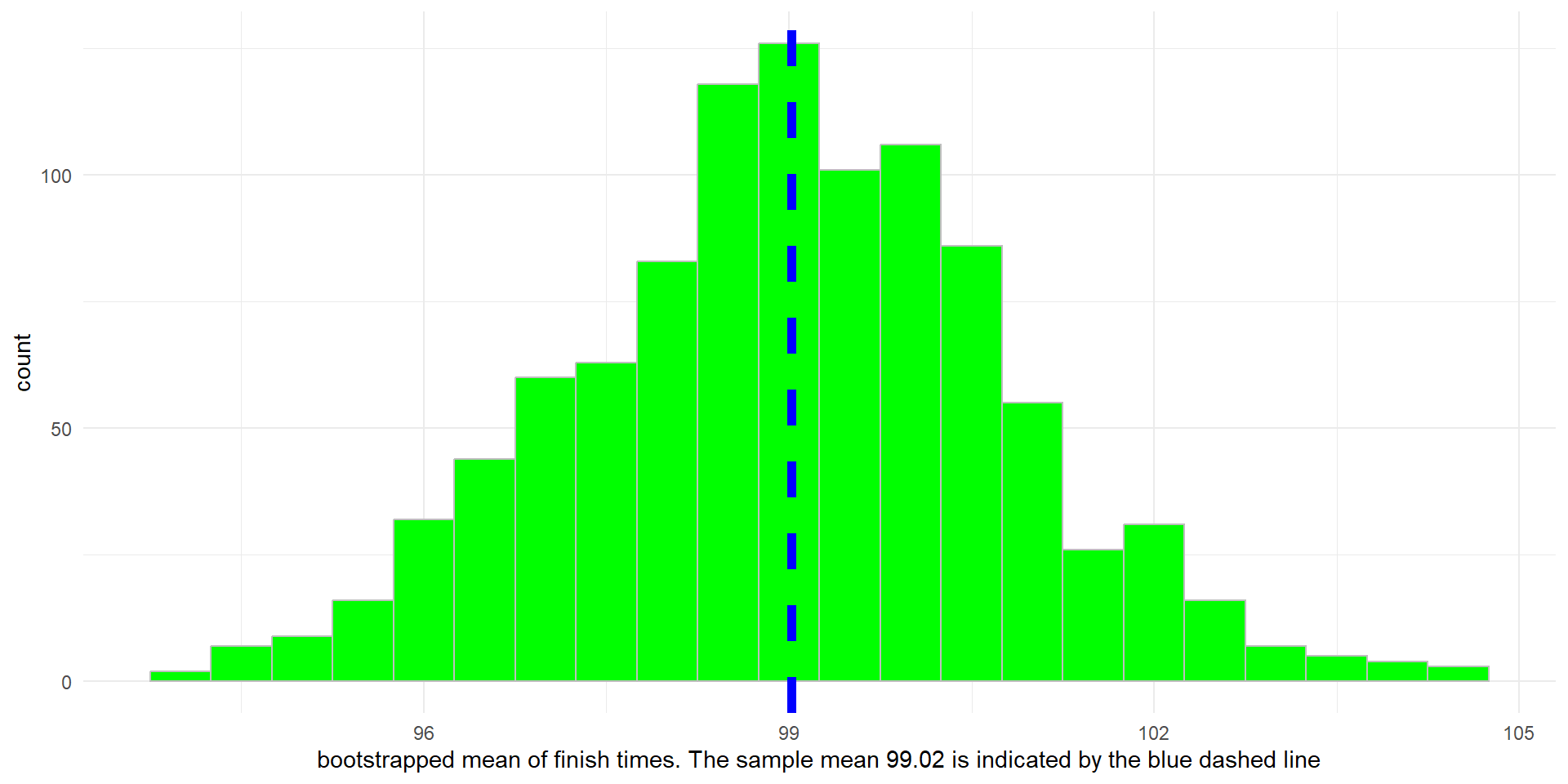
Histrogram showing 1,000 bootstrapped means.
Variability in the data vs variability of the mean
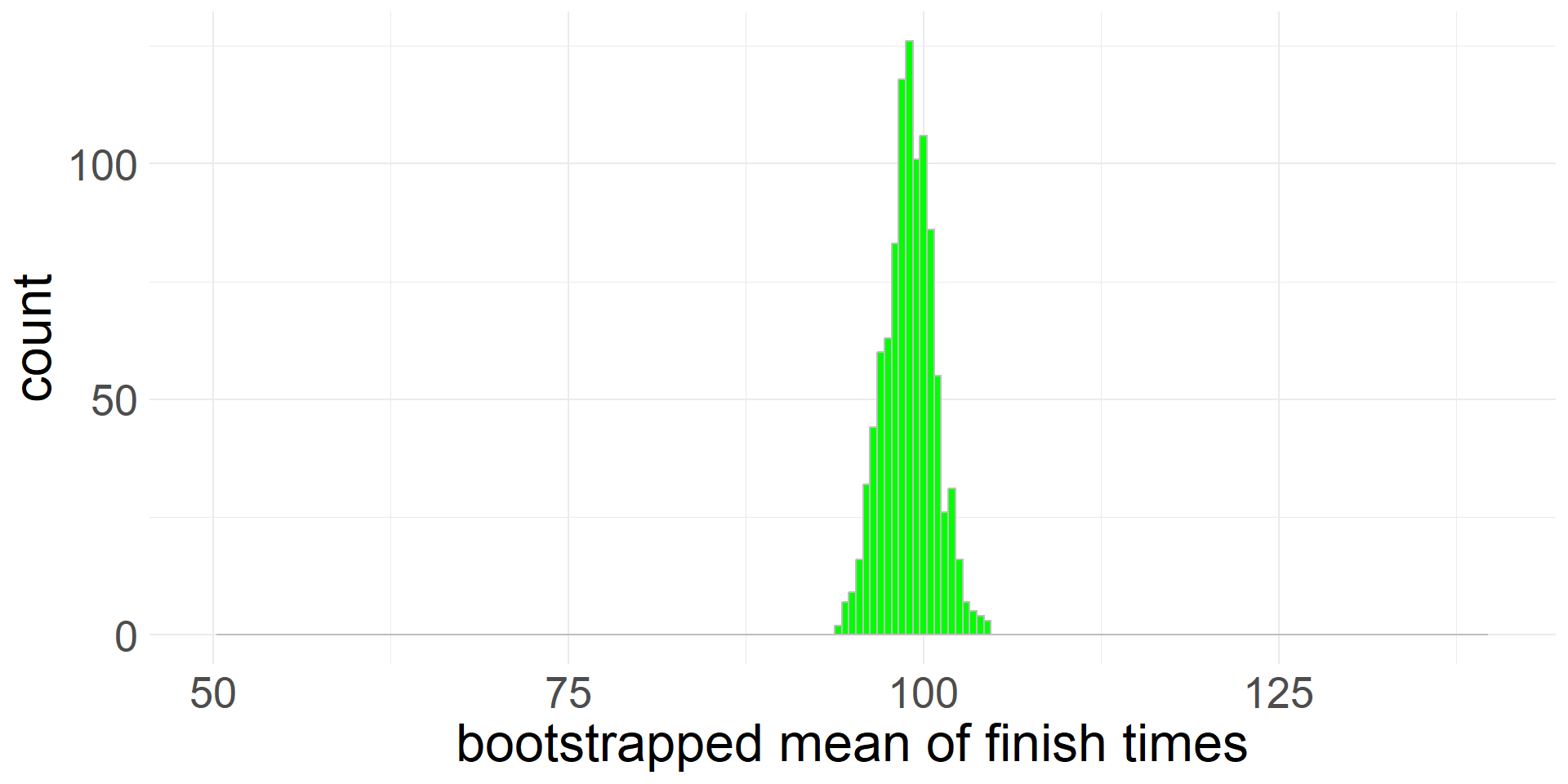
- The standard deviation of the means (1.78) is the value of the standard error(SE)
- Note that \(1.78\approx \frac{17.9}{\sqrt{100}}\)
Bootstrap Percentile CI for the Mean
- We can also calculate a bootstrap percentile confidence interval for the mean
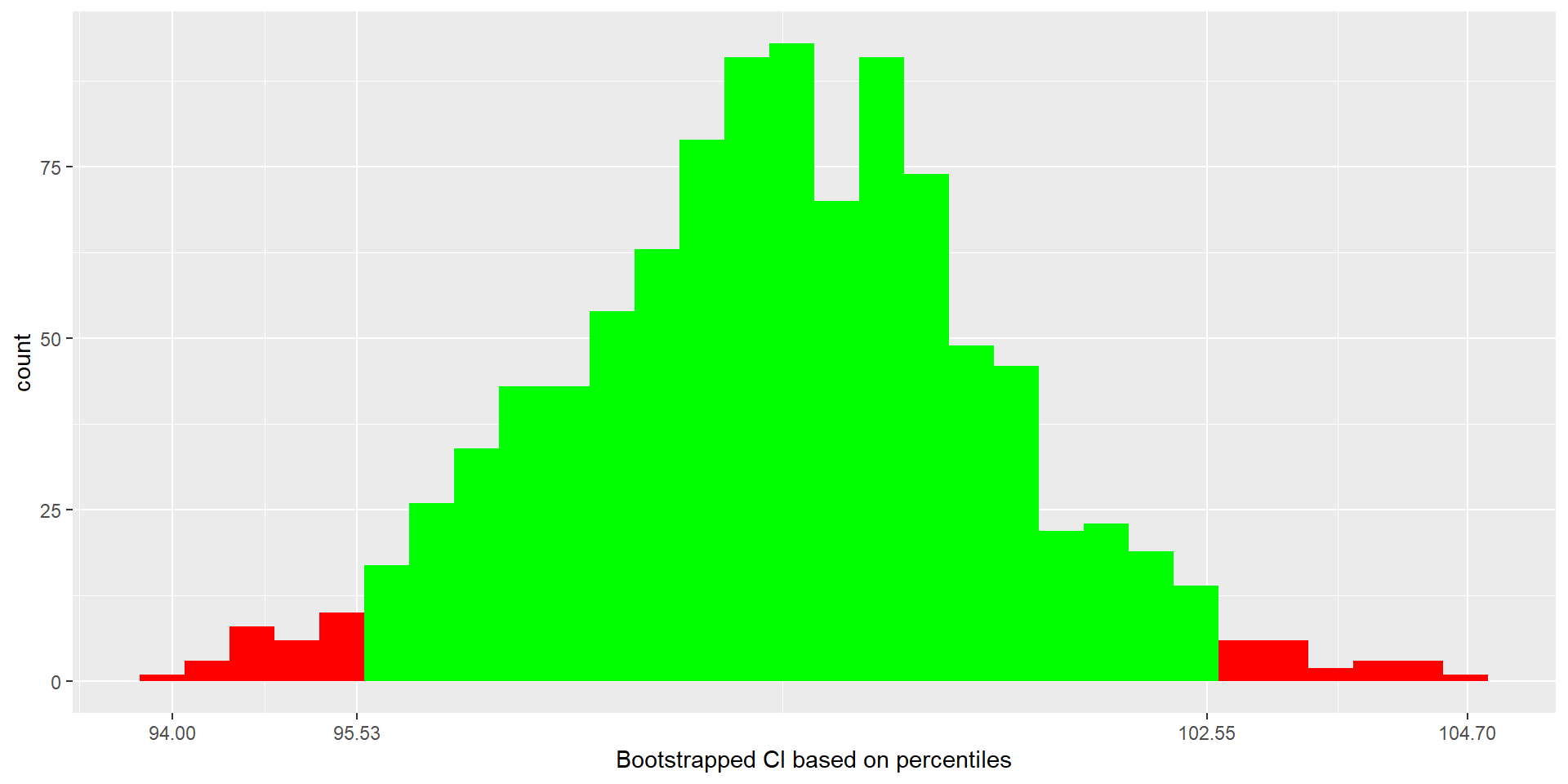
- A 95% bootstrap percentile confidence interval for the mean finish time is (95.53, 102.55)
- The Cherry Blossom run data satisfy the normality check, since there are 100 (so \(n\geq 30\)) observations, and no particularly extreme outliers
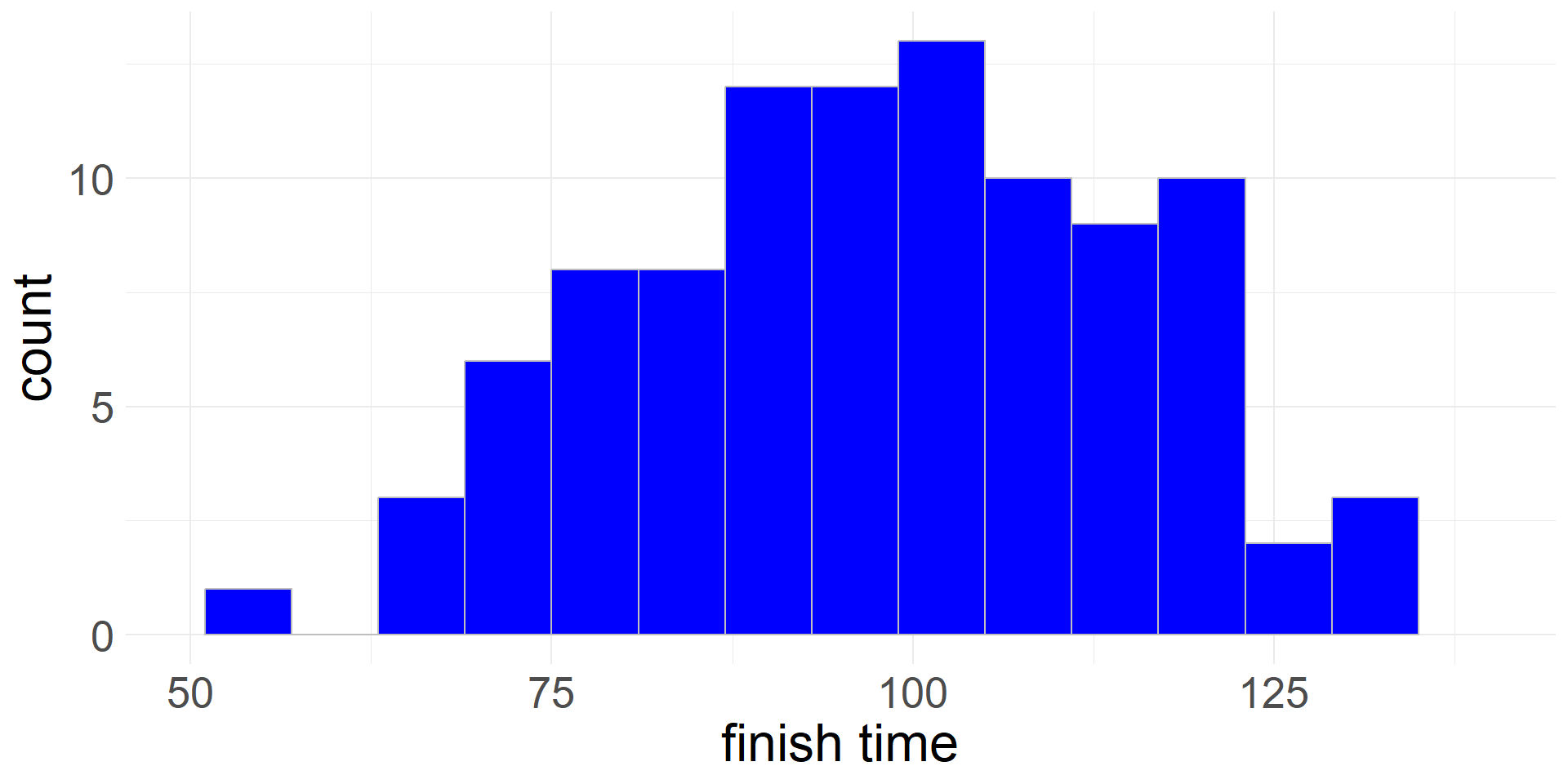
- The observations are independent, because they come from a simple random sample (SRS) of finishers
- The tails of the \(t\)-distribution are thicker than the normal distribution due to uncertainty in the SE estimate
- This is especially true for smaller samples
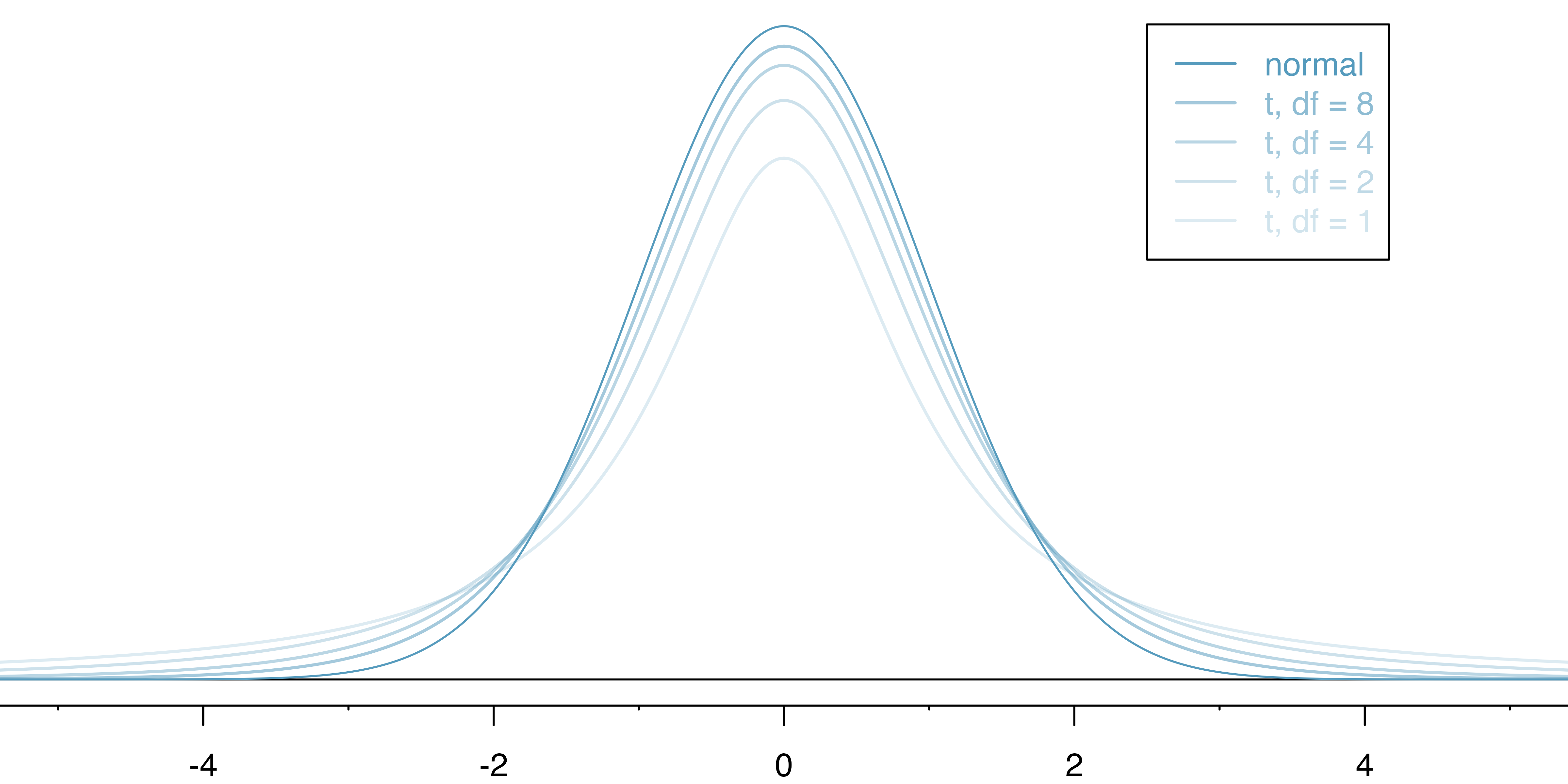
Comparison of normal distribution and \(t\)-distributions with different degrees of freedom (IMS2 Figure 19.9).
- For the Cherry Blossom run finish times, \(df=100-1=99\)
- To find \(t^{\ast}_{99}\) for a 95% confidence interval we find the cutoff for the \(t\) distribution that gives us 95% in the middle
- In Jamovi: Randomize - > Model-Based Inference

- We find the area in the left tail using
ptand double it (the t-distribution is symmetric)
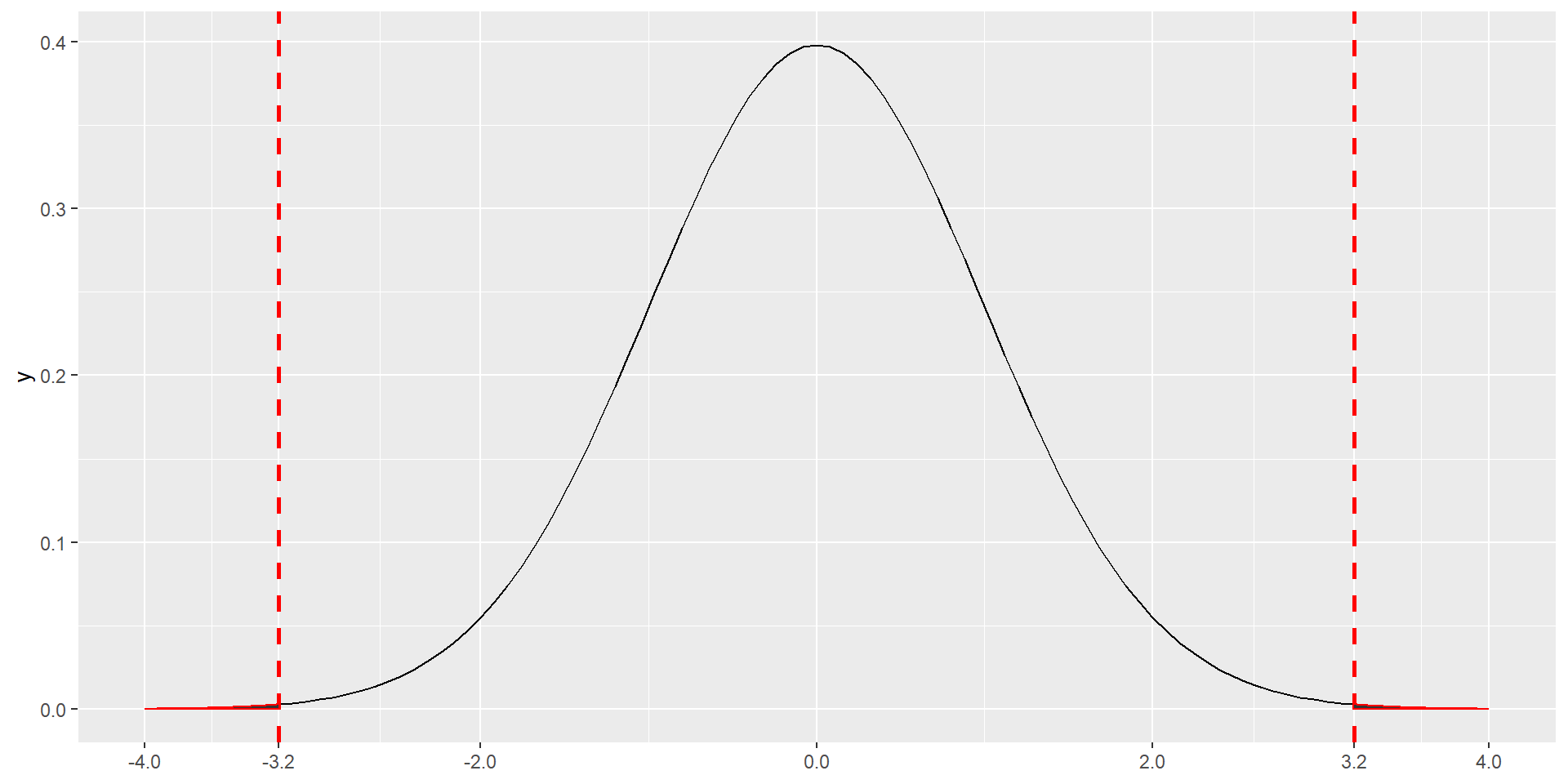
t-distribution with 99 d.f.
- In Jamovi: Randomize - > Model-Based Inference
![]()
